How Can Objects Help Video-Language Understanding?
作者: Zitian Tang, Shijie Wang, Junho Cho, Jaewook Yoo, Chen Sun
分类: cs.CV
发布日期: 2025-04-10 (更新: 2025-08-05)
🔗 代码/项目: GITHUB
💡 一句话要点
ObjectMLLM:通过显式对象信息提升视频语言理解能力
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频语言理解 多模态学习 对象检测 大型语言模型 视频问答
📋 核心要点
- 现有MLLM在视频理解中对对象和时空关系的建模方式存在隐式和显式两种极端,缺乏对显式对象表示必要性的深入研究。
- ObjectMLLM框架通过整合计算机视觉算法提取的结构化对象表示,探索显式对象信息在视频语言理解中的作用。
- 实验结果表明,显式整合对象信息对于视频问答至关重要,并且将量化的对象信息表示为文本效果最佳,具有数据效率。
📝 摘要(中文)
多模态大型语言模型(MLLM)是否仍然需要显式地表示对象?本文探讨了这个问题。一方面,预训练编码器将图像转换为视觉token,隐式地建模对象和时空关系。另一方面,即使缺少细粒度的时空信息,图像描述本身也能为理解任务提供强大的经验性能。为了回答这个问题,我们提出了ObjectMLLM,一个能够利用任意计算机视觉算法来提取和整合结构化视觉表示的框架。通过在六个视频问答基准上的广泛评估,我们证实了显式整合以对象为中心的表示仍然是必要的。令人惊讶的是,我们观察到量化连续的结构化对象信息并将其表示为纯文本的简单方法表现最佳,为将其他视觉感知模块集成到MLLM设计中提供了一种数据高效的方法。我们的代码和模型已在https://github.com/brown-palm/ObjectMLLM上发布。
🔬 方法详解
问题定义:现有的多模态大型语言模型(MLLM)在处理视频语言理解任务时,对于如何有效利用视觉信息存在争议。一种方法是将图像直接编码为视觉token,隐式地学习对象和时空关系;另一种方法是仅依赖图像描述,虽然简单但缺乏细粒度的时空信息。因此,如何有效地将对象信息融入MLLM,提升视频理解能力,是一个亟待解决的问题。现有方法要么过于隐式,要么丢失关键信息,无法充分利用视觉信息。
核心思路:ObjectMLLM的核心思路是显式地提取和整合视频中的对象信息,并将其融入到MLLM中。通过利用现有的计算机视觉算法,例如目标检测和跟踪,提取视频中的对象及其属性(例如位置、大小、类别等)。然后,将这些结构化的对象信息以一种合适的方式输入到MLLM中,从而增强模型对视频内容的理解能力。这样做的目的是让模型能够更直接地感知视频中的对象及其关系,从而提高视频问答等任务的性能。
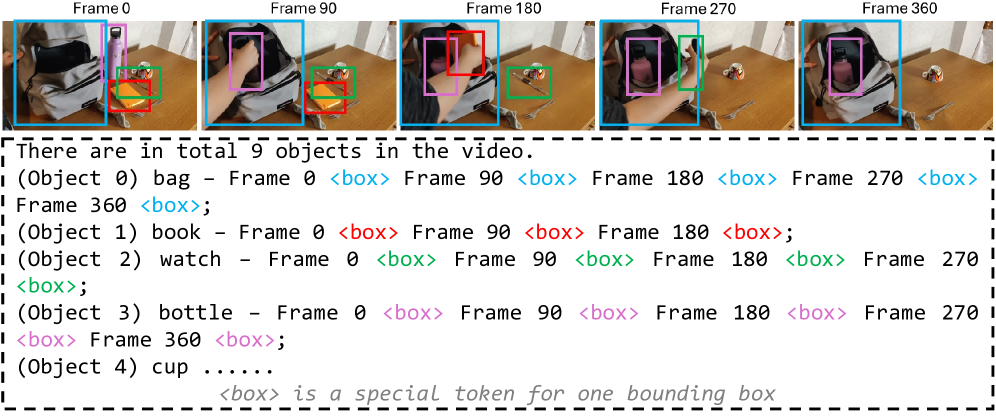
技术框架:ObjectMLLM的整体框架包含以下几个主要模块:1) 视频输入模块:接收视频作为输入。2) 对象检测与跟踪模块:利用现有的计算机视觉算法,检测和跟踪视频中的对象,提取对象的属性信息。3) 对象信息编码模块:将结构化的对象信息编码成适合MLLM处理的格式,例如文本序列。4) MLLM:使用预训练的MLLM,例如LLaMA或GPT,作为核心的语言理解模型。5) 融合模块:将编码后的对象信息与视频的其他模态信息(例如音频、文本)进行融合,输入到MLLM中进行推理。6) 输出模块:输出MLLM的预测结果。
关键创新:ObjectMLLM的关键创新在于显式地将对象信息融入到MLLM中。与以往的方法相比,ObjectMLLM不依赖于隐式的视觉token或简单的图像描述,而是直接利用计算机视觉算法提取的结构化对象信息。此外,ObjectMLLM还探索了不同的对象信息编码方式,发现将量化的对象信息表示为文本序列效果最佳,这是一种数据高效的方法。这种显式对象信息整合的方式,使得模型能够更直接地感知视频中的对象及其关系,从而提高视频理解能力。
关键设计:在对象信息编码模块中,论文探索了不同的编码方式,包括直接将连续的属性值输入到MLLM中,以及将属性值量化为离散的token。实验结果表明,将属性值量化为离散的token效果最佳。具体来说,论文将对象的位置、大小等属性值量化为若干个离散的区间,然后为每个区间分配一个唯一的token。这样做的目的是减少连续属性值的噪声,并使得MLLM更容易学习对象之间的关系。此外,论文还使用了标准的交叉熵损失函数来训练MLLM,并使用Adam优化器进行优化。
🖼️ 关键图片


📊 实验亮点
ObjectMLLM在六个视频问答基准测试中取得了显著的性能提升,证明了显式整合对象信息对于视频理解的重要性。令人惊讶的是,将量化的对象信息表示为文本序列的简单方法表现最佳,为将其他视觉感知模块集成到MLLM设计中提供了一种数据高效的方法。具体性能数据未知,但结论明确表明显式对象信息的有效性。
🎯 应用场景
ObjectMLLM具有广泛的应用前景,例如智能监控、自动驾驶、视频内容分析、智能客服等。通过显式地理解视频中的对象及其关系,ObjectMLLM可以帮助机器更好地理解视频内容,从而实现更智能化的应用。例如,在智能监控中,ObjectMLLM可以自动识别视频中的异常行为;在自动驾驶中,ObjectMLLM可以帮助车辆更好地感知周围环境;在视频内容分析中,ObjectMLLM可以自动提取视频的关键信息。
📄 摘要(原文)
Do we still need to represent objects explicitly in multimodal large language models (MLLMs)? To one extreme, pre-trained encoders convert images into visual tokens, with which objects and spatiotemporal relationships may be implicitly modeled. To the other extreme, image captions by themselves provide strong empirical performances for understanding tasks, despite missing fine-grained spatiotemporal information. To answer this question, we introduce ObjectMLLM, a framework capable of leveraging arbitrary computer vision algorithm to extract and integrate structured visual representation. Through extensive evaluations on six video question answering benchmarks, we confirm that explicit integration of object-centric representation remains necessary. Surprisingly, we observe that the simple approach of quantizing the continuous, structured object information and representing them as plain text performs the best, offering a data-efficient approach to integrate other visual perception modules into MLLM design. Our code and models are released at https://github.com/brown-palm/ObjectMLLM.