Leveraging LLMs for Multimodal Retrieval-Augmented Radiology Report Generation via Key Phrase Extraction
作者: Kyoyun Choi, Byungmu Yoon, Soobum Kim, Jonggwon Park
分类: cs.CV, cs.CL, cs.LG
发布日期: 2025-04-10
💡 一句话要点
提出基于关键短语提取的检索增强型多模态LLM放射报告生成方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 放射报告生成 多模态学习 大型语言模型 检索增强生成 关键短语提取 对比学习 医学影像
📋 核心要点
- 多模态LLM在放射报告生成中面临计算资源需求大和易产生幻觉的问题。
- 该论文提出一种检索增强生成方法,利用LLM提取关键短语,并结合对比学习。
- 实验表明,该方法在MIMIC-CXR数据集上取得了SOTA的CheXbert指标,且无需LLM微调。
📝 摘要(中文)
自动放射报告生成(RRG)有潜力减轻放射科医生的工作负担,特别是随着大型语言模型(LLM)的最新进展,使得开发用于胸部X光(CXR)报告生成的多模态模型成为可能。然而,多模态LLM(MLLM)是资源密集型的,需要庞大的数据集和大量的计算成本进行训练。为了应对这些挑战,我们提出了一种检索增强生成方法,该方法利用多模态检索和LLM来生成放射报告,同时减轻幻觉并降低计算需求。我们的方法使用LLM从放射报告中提取关键短语,有效地关注重要的诊断信息。通过探索有效的训练策略,包括图像编码器结构搜索、向文本嵌入添加噪声以及额外的训练目标,我们结合了互补的预训练图像编码器,并采用文本和语义图像嵌入之间的对比学习。我们在MIMIC-CXR数据集上评估了我们的方法,在CheXbert指标上取得了最先进的结果,并在RadGraph F1指标上与MLLM相比具有竞争力,而无需LLM微调。我们的方法展示了多视图RRG的强大泛化能力,使其适用于全面的临床应用。
🔬 方法详解
问题定义:现有基于多模态LLM的放射报告生成方法需要大量的计算资源和训练数据,并且容易产生幻觉,即生成与图像内容不符的报告。这些问题限制了其在实际临床环境中的应用。
核心思路:该论文的核心思路是利用检索增强生成来缓解MLLM的资源需求和幻觉问题。通过从现有的放射报告中检索相关信息,并将其作为LLM生成报告的上下文,可以减少LLM对自身知识的依赖,从而降低幻觉风险。同时,通过关键短语提取,可以使检索过程更加高效,并聚焦于重要的诊断信息。
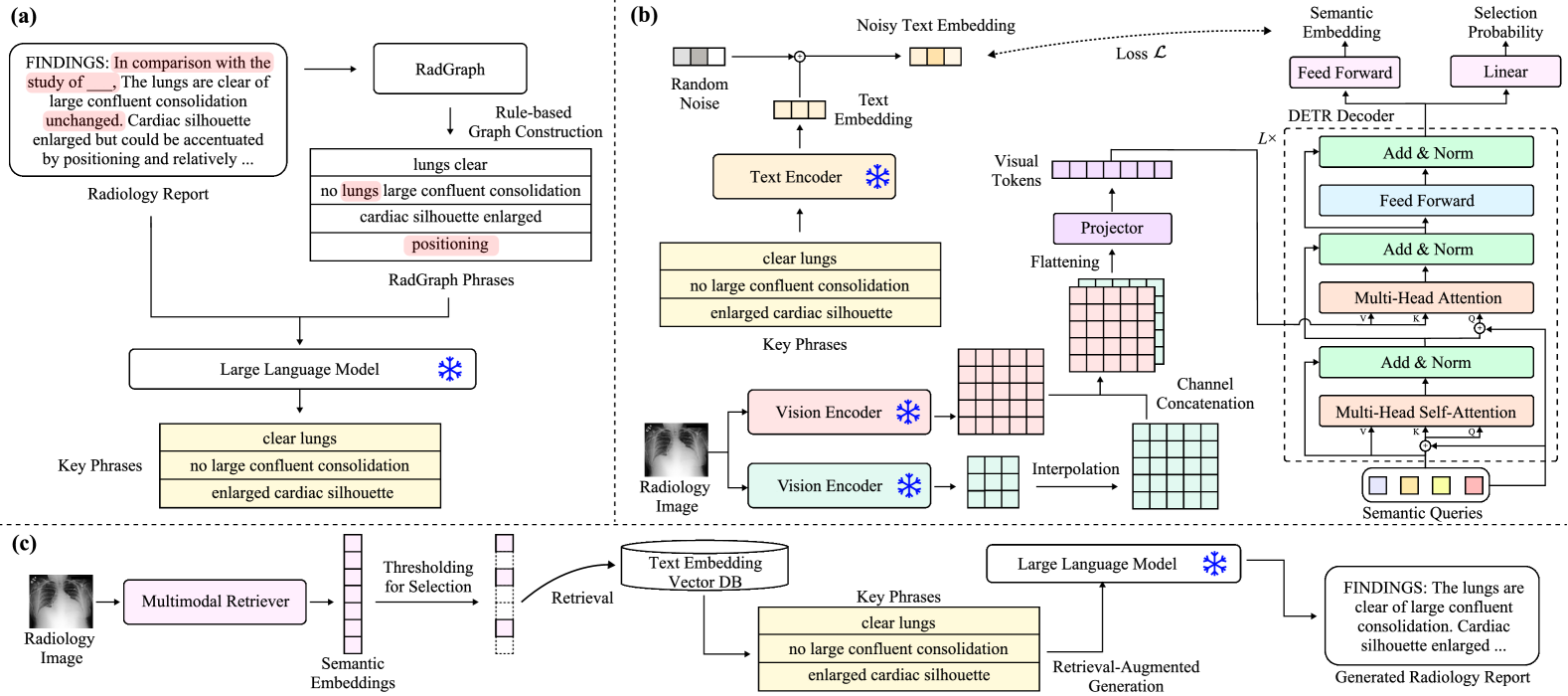
技术框架:该方法主要包含以下几个模块:1) 关键短语提取模块:使用LLM从放射报告中提取关键短语。2) 多模态检索模块:基于图像和文本(关键短语)信息,从数据库中检索相关的放射报告。3) 报告生成模块:将检索到的报告作为上下文,输入LLM生成最终的放射报告。此外,还包括图像编码器结构搜索和对比学习等训练策略。
关键创新:该论文的关键创新在于将关键短语提取与检索增强生成相结合,用于放射报告生成。通过关键短语提取,可以有效地聚焦于重要的诊断信息,提高检索效率和报告生成的准确性。此外,该方法还探索了多种有效的训练策略,包括图像编码器结构搜索、添加噪声到文本嵌入以及额外的训练目标,进一步提升了模型的性能。
关键设计:在图像编码器结构搜索方面,论文探索了不同的预训练图像编码器,并选择了合适的结构。在对比学习方面,采用了文本和语义图像嵌入之间的对比学习,以增强图像和文本之间的关联性。此外,还通过添加噪声到文本嵌入来提高模型的鲁棒性。损失函数方面,除了传统的交叉熵损失外,还使用了对比学习损失。
🖼️ 关键图片

📊 实验亮点
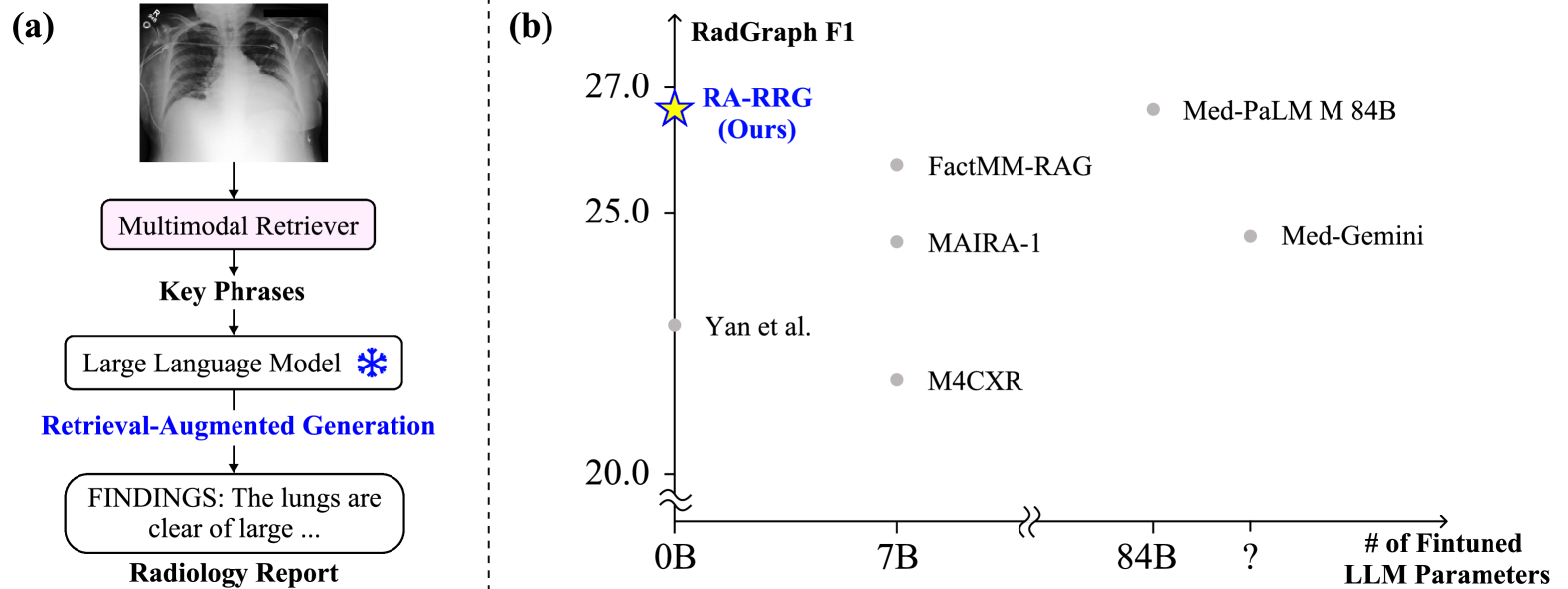
该方法在MIMIC-CXR数据集上取得了显著的成果,在CheXbert指标上达到了state-of-the-art的水平,并且在RadGraph F1指标上与MLLM模型具有竞争力,而无需对LLM进行微调。这表明该方法在降低计算成本的同时,能够有效地提升放射报告生成的质量。
🎯 应用场景
该研究成果可应用于临床放射报告的自动生成,减轻放射科医生的工作负担,提高报告的效率和准确性。尤其是在医疗资源匮乏的地区,该技术可以辅助医生进行诊断,提升医疗服务水平。未来,该技术还可以扩展到其他医学影像领域,如CT、MRI等。
📄 摘要(原文)
Automated radiology report generation (RRG) holds potential to reduce radiologists' workload, especially as recent advancements in large language models (LLMs) enable the development of multimodal models for chest X-ray (CXR) report generation. However, multimodal LLMs (MLLMs) are resource-intensive, requiring vast datasets and substantial computational cost for training. To address these challenges, we propose a retrieval-augmented generation approach that leverages multimodal retrieval and LLMs to generate radiology reports while mitigating hallucinations and reducing computational demands. Our method uses LLMs to extract key phrases from radiology reports, effectively focusing on essential diagnostic information. Through exploring effective training strategies, including image encoder structure search, adding noise to text embeddings, and additional training objectives, we combine complementary pre-trained image encoders and adopt contrastive learning between text and semantic image embeddings. We evaluate our approach on MIMIC-CXR dataset, achieving state-of-the-art results on CheXbert metrics and competitive RadGraph F1 metric alongside MLLMs, without requiring LLM fine-tuning. Our method demonstrates robust generalization for multi-view RRG, making it suitable for comprehensive clinical applications.