Novel Diffusion Models for Multimodal 3D Hand Trajectory Prediction
作者: Junyi Ma, Wentao Bao, Jingyi Xu, Guanzhong Sun, Xieyuanli Chen, Hesheng Wang
分类: cs.CV
发布日期: 2025-04-10 (更新: 2025-11-14)
备注: Accepted to IROS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出MMTwin,一种用于多模态3D手部轨迹预测的新型扩散模型。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion) 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 手部轨迹预测 扩散模型 多模态融合 自我运动估计 人机交互
📋 核心要点
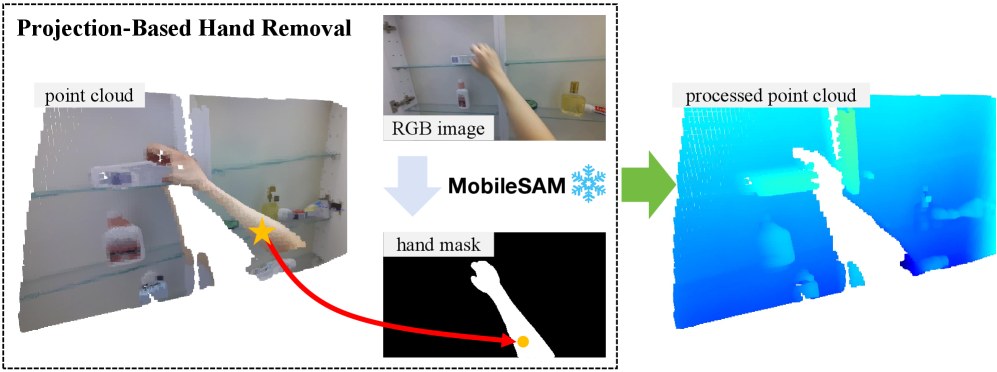
- 现有手部轨迹预测方法主要依赖2D视频输入,忽略了3D环境信息和手部与相机运动的协同。
- MMTwin模型通过融合2D图像、3D点云、历史轨迹和文本提示等多模态信息,同时预测相机自我运动和手部轨迹。
- 实验结果表明,MMTwin在多个数据集上优于现有方法,并具有良好的泛化能力。
📝 摘要(中文)
手部运动预测对于理解人类意图以及连接人类动作空间和机器人操作至关重要。现有的手部轨迹预测(HTP)方法基于过去的自我中心视角观测预测未来3D空间中的手部航点。然而,这些模型仅设计用于处理2D自我中心视频输入,缺乏对来自2D和3D观测的多模态环境信息的感知,阻碍了3D HTP性能的进一步提升。此外,这些模型忽略了手部运动和头戴式相机自我运动之间的协同作用,要么孤立地预测手部轨迹,要么仅从过去的帧中编码自我运动。为了解决这些局限性,我们提出了一种用于多模态3D手部轨迹预测的新型扩散模型(MMTwin)。MMTwin旨在吸收包含2D RGB图像、3D点云、过去的手部航点和文本提示的多模态信息作为输入。此外,两个潜在扩散模型,即自我运动扩散和HTP扩散,作为孪生模型集成到MMTwin中,以同时预测相机自我运动和未来手部轨迹。我们提出了一种新型混合Mamba-Transformer模块作为HTP扩散的去噪模型,以更好地融合多模态特征。在三个公开数据集和我们自己记录的数据上的实验结果表明,与最先进的基线相比,我们提出的MMTwin可以预测合理的未来3D手部轨迹,并且可以很好地推广到未见过的环境。代码和预训练模型已在https://github.com/IRMVLab/MMTwin上发布。
🔬 方法详解
问题定义:现有手部轨迹预测方法主要依赖于2D自我中心视频输入,忽略了3D环境信息以及手部运动与头戴式相机自我运动之间的协同关系。这限制了预测的准确性和鲁棒性,尤其是在复杂环境中。现有方法要么孤立地预测手部轨迹,要么仅从过去的帧中编码自我运动,未能充分利用手部运动和相机运动之间的内在联系。
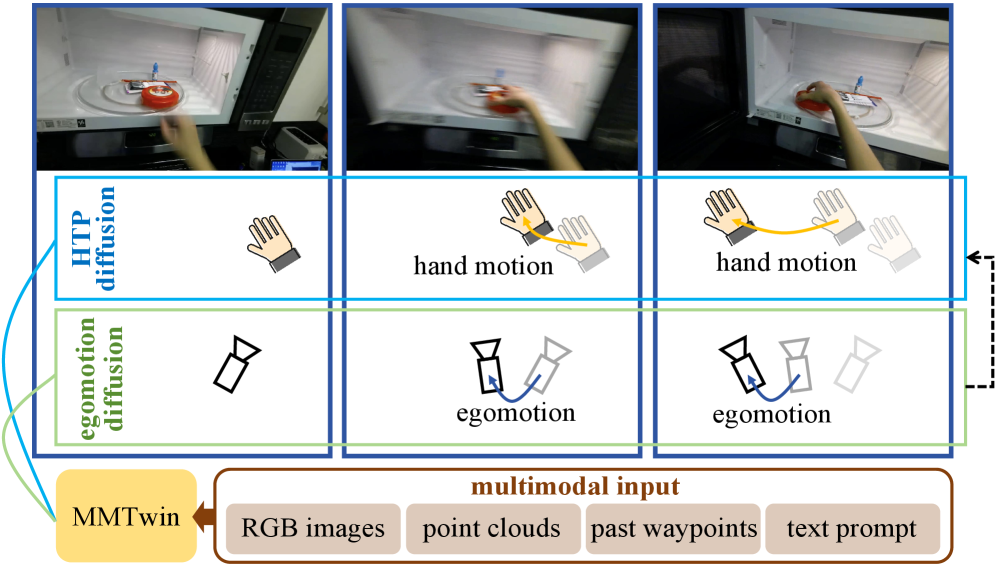
核心思路:MMTwin的核心思路是利用扩散模型同时预测相机自我运动和手部轨迹,并将它们视为孪生任务。通过融合多模态信息(2D RGB图像、3D点云、历史手部航点和文本提示),模型能够更好地理解环境并预测更准确的轨迹。同时预测自我运动和手部轨迹,可以捕捉它们之间的依赖关系,提高预测的连贯性。
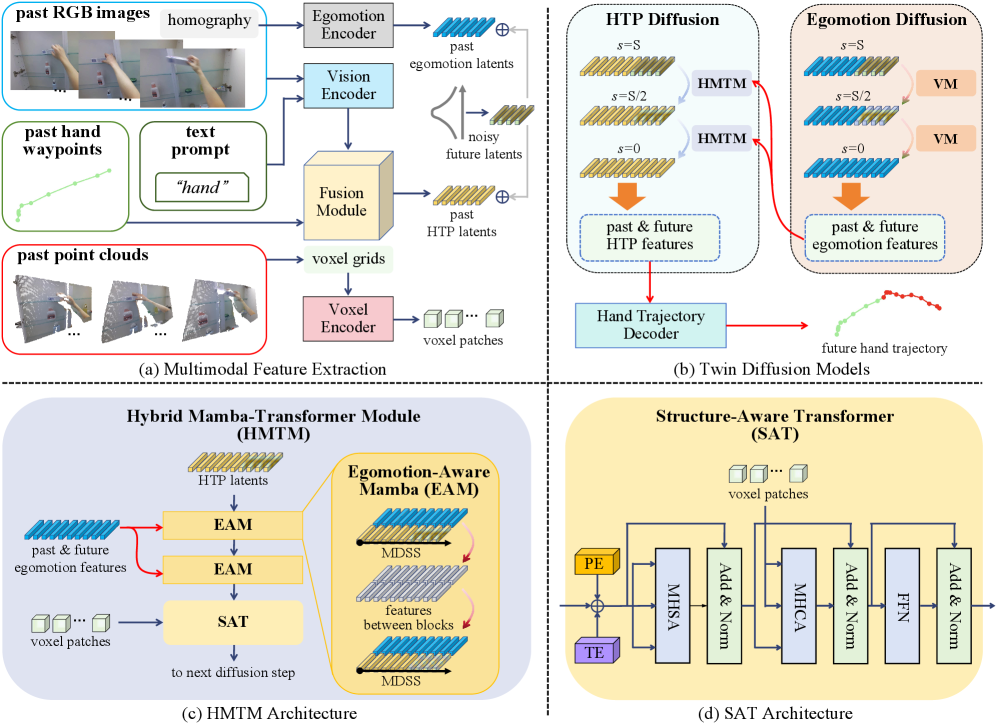
技术框架:MMTwin包含两个主要的潜在扩散模型:自我运动扩散和HTP扩散。首先,多模态输入被编码到潜在空间中。然后,自我运动扩散模型预测相机自我运动,HTP扩散模型预测未来手部轨迹。这两个扩散模型并行工作,并通过共享潜在表示进行信息交互。最后,解码器将潜在空间中的预测结果转换回3D空间中的轨迹。
关键创新:MMTwin的关键创新在于:1) 提出了一个多模态融合框架,能够有效地整合来自不同模态的信息;2) 将自我运动预测和手部轨迹预测视为孪生任务,利用扩散模型同时进行预测;3) 提出了一个新型混合Mamba-Transformer模块作为HTP扩散的去噪模型,以更好地融合多模态特征。
关键设计:MMTwin使用潜在扩散模型,通过学习数据分布的逆过程来生成轨迹。混合Mamba-Transformer模块结合了Mamba模型的序列建模能力和Transformer模型的全局注意力机制,以更好地处理时序数据和融合多模态特征。损失函数包括扩散模型的标准损失以及用于约束自我运动和手部轨迹一致性的损失项。具体参数设置和网络结构细节可以在论文的补充材料中找到。
🖼️ 关键图片
📊 实验亮点
MMTwin在三个公开数据集和作者自建数据集上进行了评估,实验结果表明,MMTwin在手部轨迹预测的准确性和鲁棒性方面均优于现有方法。特别是在复杂环境中,MMTwin的预测结果更加合理和连贯。作者还进行了消融实验,验证了多模态融合和孪生任务设计的有效性。
🎯 应用场景
该研究成果可应用于人机交互、机器人操作、虚拟现实和增强现实等领域。例如,在机器人辅助手术中,预测医生手部运动轨迹可以帮助机器人更好地辅助手术操作。在VR/AR游戏中,预测用户手部运动轨迹可以提供更自然、流畅的交互体验。此外,该技术还可以用于手语识别和手势控制等应用。
📄 摘要(原文)
Predicting hand motion is critical for understanding human intentions and bridging the action space between human movements and robot manipulations. Existing hand trajectory prediction (HTP) methods forecast the future hand waypoints in 3D space conditioned on past egocentric observations. However, such models are only designed to accommodate 2D egocentric video inputs. There is a lack of awareness of multimodal environmental information from both 2D and 3D observations, hindering the further improvement of 3D HTP performance. In addition, these models overlook the synergy between hand movements and headset camera egomotion, either predicting hand trajectories in isolation or encoding egomotion only from past frames. To address these limitations, we propose novel diffusion models (MMTwin) for multimodal 3D hand trajectory prediction. MMTwin is designed to absorb multimodal information as input encompassing 2D RGB images, 3D point clouds, past hand waypoints, and text prompt. Besides, two latent diffusion models, the egomotion diffusion and the HTP diffusion as twins, are integrated into MMTwin to predict camera egomotion and future hand trajectories concurrently. We propose a novel hybrid Mamba-Transformer module as the denoising model of the HTP diffusion to better fuse multimodal features. The experimental results on three publicly available datasets and our self-recorded data demonstrate that our proposed MMTwin can predict plausible future 3D hand trajectories compared to the state-of-the-art baselines, and generalizes well to unseen environments. The code and pretrained models have been released at https://github.com/IRMVLab/MMTwin.