Caption Anything in Video: Fine-grained Object-centric Captioning via Spatiotemporal Multimodal Prompting
作者: Yunlong Tang, Jing Bi, Chao Huang, Susan Liang, Daiki Shimada, Hang Hua, Yunzhong Xiao, Yizhi Song, Pinxin Liu, Mingqian Feng, Junjia Guo, Zhuo Liu, Luchuan Song, Ali Vosoughi, Jinxi He, Liu He, Zeliang Zhang, Jiebo Luo, Chenliang Xu
分类: cs.CV
发布日期: 2025-04-07 (更新: 2025-04-09)
🔗 代码/项目: GITHUB
💡 一句话要点
提出CAT-V:一个免训练的视频细粒度、以对象为中心的描述框架。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频描述 细粒度描述 对象中心 时空提示 免训练 视觉语言模型 思维链推理
📋 核心要点
- 现有视频描述方法抽象程度高,缺乏对象级别的精确描述,难以满足细粒度分析需求。
- CAT-V框架利用时空视觉提示和思维链推理,无需额外训练即可生成对象属性、动作等详细描述。
- CAT-V通过集成SAMURAI、TRACE-Uni和InternVL-2.5等模块,实现了精确分割、时间分析和详细描述。
📝 摘要(中文)
本文提出CAT-V,一个免训练的视频细粒度、以对象为中心的描述框架,它能够生成用户选定对象随时间变化的详细描述。CAT-V集成了三个关键组件:基于SAMURAI的分割器,用于跨帧精确的对象分割;由TRACE-Uni驱动的时间分析器,用于准确的事件边界检测和时间分析;以及使用InternVL-2.5的描述器,用于生成详细的以对象为中心的描述。通过时空视觉提示和思维链推理,我们的框架生成关于对象的属性、动作、状态、交互和环境上下文的详细的、具有时间意识的描述,而无需额外的训练数据。CAT-V通过各种视觉提示(点、边界框和不规则区域)支持灵活的用户交互,并通过跟踪不同时间段内的对象状态和交互来保持时间敏感性。我们的方法解决了现有视频描述方法的局限性,这些方法要么产生过于抽象的描述,要么缺乏对象级别的精度,从而实现细粒度的、对象特定的描述,同时保持时间连贯性和空间准确性。
🔬 方法详解
问题定义:现有视频描述方法通常生成过于宽泛的描述,缺乏对视频中特定对象的细粒度理解和描述能力。用户难以获取关于特定对象在视频中的行为、状态变化以及与其他对象交互的详细信息。现有方法无法有效利用用户提供的关于目标对象的先验知识(例如,通过点击、框选等方式指定目标对象)。
核心思路:CAT-V的核心思路是利用预训练的视觉模型(如SAMURAI、TRACE-Uni、InternVL-2.5)的强大能力,通过时空提示(spatiotemporal prompts)引导模型关注用户感兴趣的对象,并结合思维链(chain-of-thought)推理逐步生成详细的描述。这种方法避免了从头训练或微调模型的需要,实现了零样本(zero-shot)的细粒度视频描述。
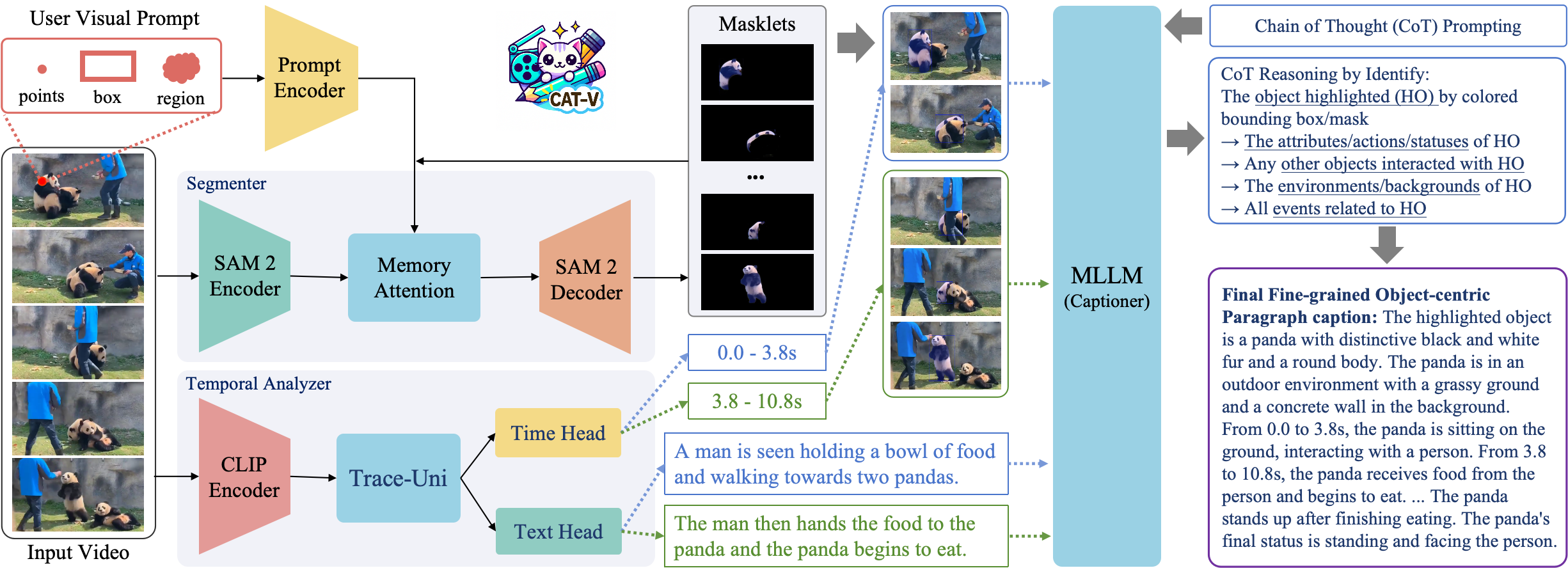
技术框架:CAT-V框架包含三个主要模块:1) 分割器 (Segmenter):基于SAMURAI,用于在视频帧中精确分割用户指定的对象。用户可以通过点、边界框或不规则区域等视觉提示来指定对象。2) 时间分析器 (Temporal Analyzer):由TRACE-Uni驱动,用于检测视频中的事件边界,并进行时间分析,以理解对象在不同时间段内的状态和行为变化。3) 描述器 (Captioner):使用InternVL-2.5,根据分割结果和时间分析结果,生成详细的、以对象为中心的描述。框架通过时空视觉提示将用户输入的对象信息传递给各个模块,并利用思维链推理逐步生成描述。
关键创新:CAT-V的关键创新在于其免训练(training-free)的特性,以及通过时空视觉提示和思维链推理实现细粒度对象描述的能力。与需要大量训练数据的传统视频描述方法不同,CAT-V能够直接利用预训练模型的知识,根据用户指定的对象生成详细的描述。此外,CAT-V通过时间分析器实现了对对象状态和行为随时间变化的建模,从而生成更连贯和准确的描述。
关键设计:CAT-V的关键设计包括:1) 使用SAMURAI进行精确的对象分割,确保描述器能够关注到用户感兴趣的对象。2) 使用TRACE-Uni进行时间分析,从而理解对象在不同时间段内的状态和行为变化。3) 使用InternVL-2.5作为描述器,利用其强大的视觉语言能力生成详细的描述。4) 通过时空视觉提示将用户输入的对象信息传递给各个模块,并利用思维链推理逐步生成描述。具体的参数设置、损失函数和网络结构等细节取决于所使用的预训练模型(SAMURAI、TRACE-Uni、InternVL-2.5)。
🖼️ 关键图片

📊 实验亮点
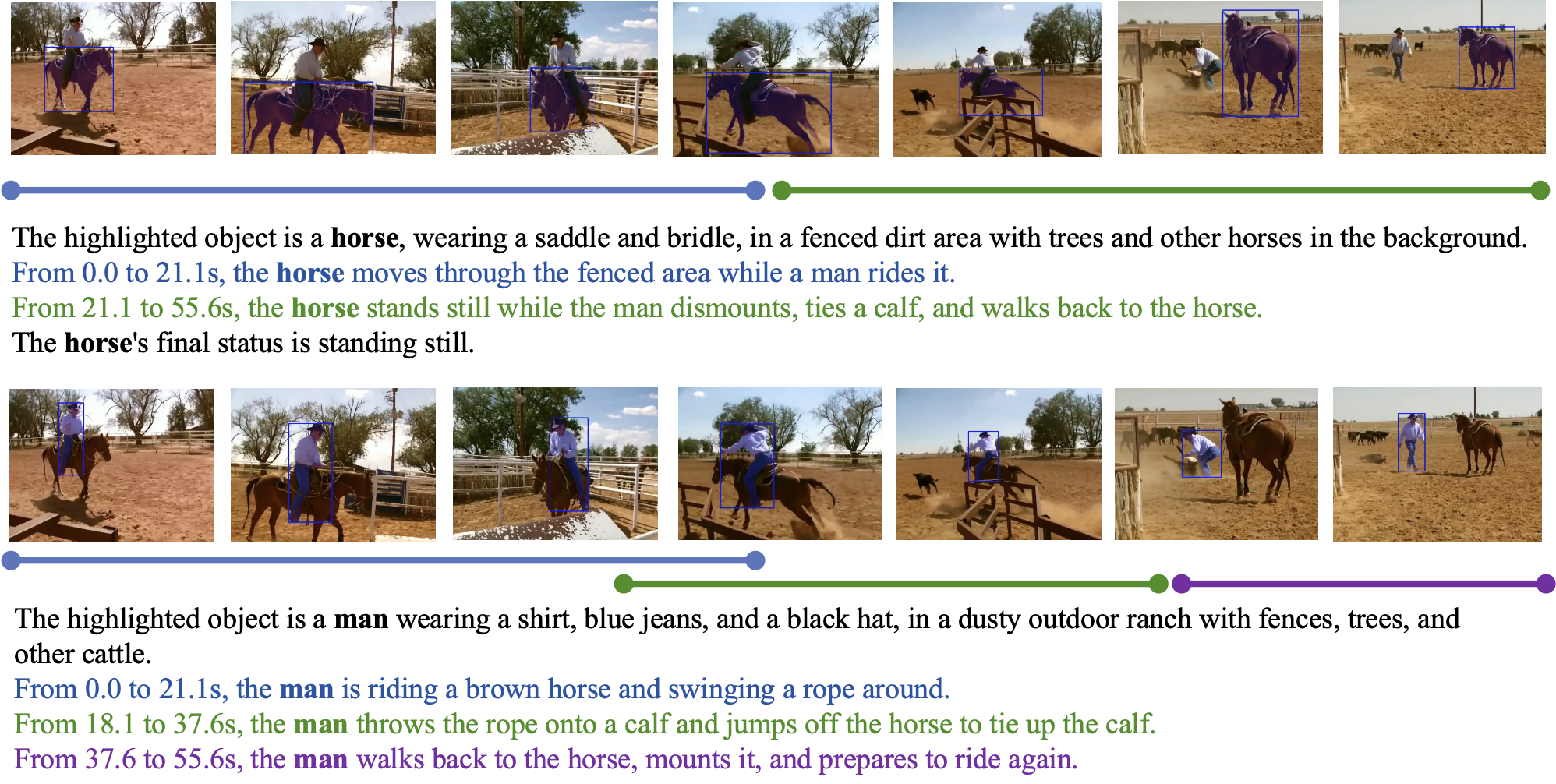
CAT-V是一个免训练框架,无需额外数据即可实现细粒度的视频对象描述。通过集成SAMURAI、TRACE-Uni和InternVL-2.5等预训练模型,CAT-V能够生成关于对象属性、动作、状态、交互和环境上下文的详细描述。该方法解决了现有视频描述方法抽象程度高、缺乏对象级别精确描述的问题,实现了时间和空间上的连贯性和准确性。
🎯 应用场景
CAT-V具有广泛的应用前景,例如视频监控分析、智能安防、自动驾驶、视频编辑、教育娱乐等领域。它可以帮助用户快速理解视频内容,提取关键信息,并进行细粒度的分析和检索。例如,在视频监控中,可以利用CAT-V自动识别和描述特定人员或物体的行为,从而提高监控效率。在自动驾驶中,可以利用CAT-V理解周围环境,识别交通参与者的行为,从而提高驾驶安全性。
📄 摘要(原文)
We present CAT-V (Caption AnyThing in Video), a training-free framework for fine-grained object-centric video captioning that enables detailed descriptions of user-selected objects through time. CAT-V integrates three key components: a Segmenter based on SAMURAI for precise object segmentation across frames, a Temporal Analyzer powered by TRACE-Uni for accurate event boundary detection and temporal analysis, and a Captioner using InternVL-2.5 for generating detailed object-centric descriptions. Through spatiotemporal visual prompts and chain-of-thought reasoning, our framework generates detailed, temporally-aware descriptions of objects' attributes, actions, statuses, interactions, and environmental contexts without requiring additional training data. CAT-V supports flexible user interactions through various visual prompts (points, bounding boxes, and irregular regions) and maintains temporal sensitivity by tracking object states and interactions across different time segments. Our approach addresses limitations of existing video captioning methods, which either produce overly abstract descriptions or lack object-level precision, enabling fine-grained, object-specific descriptions while maintaining temporal coherence and spatial accuracy. The GitHub repository for this project is available at https://github.com/yunlong10/CAT-V