SSLFusion: Scale & Space Aligned Latent Fusion Model for Multimodal 3D Object Detection
作者: Bonan Ding, Jin Xie, Jing Nie, Jiale Cao
分类: cs.CV, cs.AI
发布日期: 2025-04-07
备注: Accepted by AAAI 2025
💡 一句话要点
SSLFusion:提出尺度与空间对齐的潜在融合模型,用于多模态3D目标检测。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态融合 3D目标检测 尺度对齐 空间对齐 潜在空间 自动驾驶 点云处理
📋 核心要点
- 现有方法在多模态3D目标检测中,难以有效整合不同尺度和模态的特征,导致检测精度受限。
- SSLFusion通过尺度对齐融合、空间对齐和潜在空间融合,解决多模态特征的尺度和空间不对齐问题。
- 实验结果表明,SSLFusion在KITTI测试集上,相比现有最优方法,3D AP指标提升了2.15%。
📝 摘要(中文)
基于深度神经网络的多模态3D目标检测取得了显著进展,但仍面临2D图像特征与3D点云特征之间尺度和空间信息不对齐的挑战。现有方法通常在单一阶段聚合多模态特征,然而,利用多阶段跨模态特征对于检测不同尺度的目标至关重要。这些方法难以有效整合不同尺度和模态的特征,从而限制了检测精度。此外,现有方法中耗时的基于Query-Key-Value的跨注意力操作通过捕获非局部上下文来推断目标的位置和存在,但往往会增加计算复杂度。为了解决这些挑战,我们提出了SSLFusion,一种新颖的尺度与空间对齐的潜在融合模型,包含尺度对齐融合策略(SAF)、3D到2D空间对齐模块(SAM)和潜在跨模态融合模块(LFM)。SAF通过聚合来自图像和点云的多层特征来缓解模态间的尺度不对齐。SAM旨在通过将3D坐标信息融入2D图像特征来减小图像和点云特征之间的模态间隙。此外,LFM在潜在空间中捕获跨模态非局部上下文,而无需使用基于QKV的注意力操作,从而降低了计算复杂度。在KITTI和DENSE数据集上的实验表明,我们的SSLFusion优于最先进的方法。与最先进的GraphAlign方法相比,我们的方法在KITTI测试集的中等难度水平上获得了2.15%的3D AP绝对增益。
🔬 方法详解
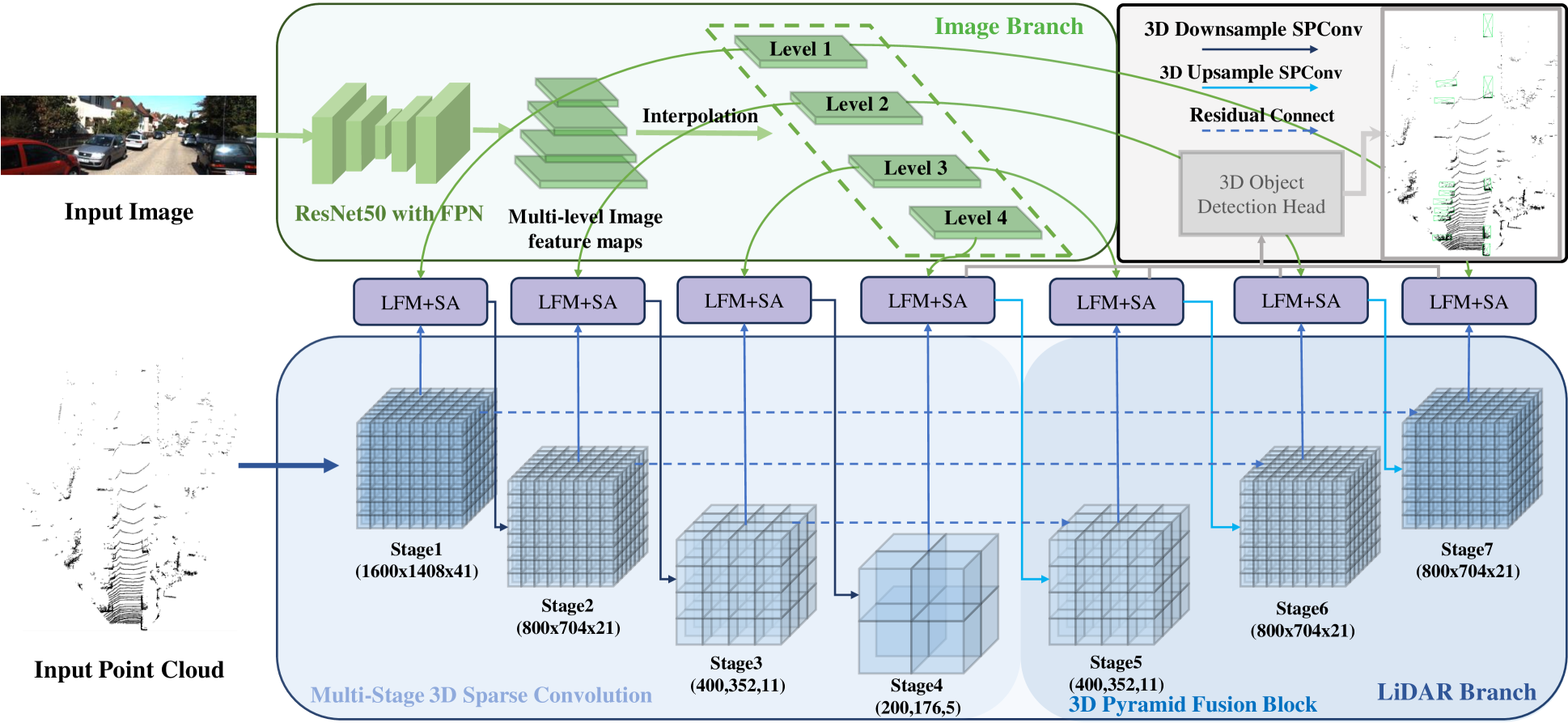
问题定义:论文旨在解决多模态3D目标检测中,2D图像特征和3D点云特征之间存在的尺度和空间不对齐问题。现有方法通常在单一阶段融合特征,忽略了多尺度特征的重要性,并且依赖计算复杂度高的QKV注意力机制来捕获跨模态上下文,效率较低。
核心思路:论文的核心思路是通过三个模块分别解决尺度不对齐、空间不对齐和计算复杂度高的问题。首先,通过尺度对齐融合策略(SAF)聚合多层特征,缓解尺度差异。其次,通过3D到2D空间对齐模块(SAM)将3D信息融入2D特征,缩小模态间隙。最后,通过潜在跨模态融合模块(LFM)在潜在空间中捕获跨模态上下文,避免使用耗时的QKV注意力机制。
技术框架:SSLFusion的整体框架包含三个主要模块:尺度对齐融合策略(SAF)、3D到2D空间对齐模块(SAM)和潜在跨模态融合模块(LFM)。首先,SAF从图像和点云中提取多尺度特征。然后,SAM将3D坐标信息融入2D图像特征。最后,LFM在潜在空间中融合对齐后的特征,进行目标检测。
关键创新:论文的关键创新在于提出了一个完整的尺度和空间对齐的潜在融合框架,该框架能够有效地解决多模态3D目标检测中的特征不对齐问题,并且通过在潜在空间中进行融合,避免了使用计算复杂度高的QKV注意力机制。与现有方法相比,SSLFusion能够更好地利用多尺度信息,并且具有更高的计算效率。
关键设计:SAF模块的具体实现方式未知,但推测可能使用了特征金字塔网络(FPN)类似的结构。SAM模块的关键在于如何将3D坐标信息有效地融入2D图像特征,具体实现方式未知。LFM模块的关键在于潜在空间的构建方式和融合策略,具体实现方式未知。损失函数方面,论文可能使用了标准的3D目标检测损失函数,例如Smooth L1 loss和Focal loss。
🖼️ 关键图片


📊 实验亮点
SSLFusion在KITTI数据集上取得了显著的性能提升。与最先进的GraphAlign方法相比,SSLFusion在KITTI测试集的中等难度水平上获得了2.15%的3D AP绝对增益。此外,该方法在DENSE数据集上也表现出优越的性能,证明了其在不同场景下的泛化能力。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、智能监控等领域。通过更精确地检测3D环境中的目标,可以提高自动驾驶系统的安全性,增强机器人对环境的感知能力,并提升智能监控系统的准确性。未来,该技术有望在智慧城市、智能交通等领域发挥重要作用。
📄 摘要(原文)
Multimodal 3D object detection based on deep neural networks has indeed made significant progress. However, it still faces challenges due to the misalignment of scale and spatial information between features extracted from 2D images and those derived from 3D point clouds. Existing methods usually aggregate multimodal features at a single stage. However, leveraging multi-stage cross-modal features is crucial for detecting objects of various scales. Therefore, these methods often struggle to integrate features across different scales and modalities effectively, thereby restricting the accuracy of detection. Additionally, the time-consuming Query-Key-Value-based (QKV-based) cross-attention operations often utilized in existing methods aid in reasoning the location and existence of objects by capturing non-local contexts. However, this approach tends to increase computational complexity. To address these challenges, we present SSLFusion, a novel Scale & Space Aligned Latent Fusion Model, consisting of a scale-aligned fusion strategy (SAF), a 3D-to-2D space alignment module (SAM), and a latent cross-modal fusion module (LFM). SAF mitigates scale misalignment between modalities by aggregating features from both images and point clouds across multiple levels. SAM is designed to reduce the inter-modal gap between features from images and point clouds by incorporating 3D coordinate information into 2D image features. Additionally, LFM captures cross-modal non-local contexts in the latent space without utilizing the QKV-based attention operations, thus mitigating computational complexity. Experiments on the KITTI and DENSE datasets demonstrate that our SSLFusion outperforms state-of-the-art methods. Our approach obtains an absolute gain of 2.15% in 3D AP, compared with the state-of-art method GraphAlign on the moderate level of the KITTI test set.