3D Scene Understanding Through Local Random Access Sequence Modeling
作者: Wanhee Lee, Klemen Kotar, Rahul Mysore Venkatesh, Jared Watrous, Honglin Chen, Khai Loong Aw, Daniel L. K. Yamins
分类: cs.CV
发布日期: 2025-04-04
备注: Project webpage: https://neuroailab.github.io/projects/lras_3d/
💡 一句话要点
提出局部随机访问序列建模(LRAS),用于提升单图三维场景理解的一致性和编辑能力。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 三维场景理解 自回归模型 新视角合成 深度估计 光流 序列建模 局部量化
📋 核心要点
- 现有基于扩散模型的三维场景理解方法难以在复杂场景中保持对象和场景的一致性。
- LRAS采用局部块量化和随机排序序列生成,通过自回归方式建模三维场景,提升一致性。
- 实验表明,LRAS在视角合成、三维物体操作和自监督深度估计任务上均取得了优异的性能。
📝 摘要(中文)
本文提出了一种用于单图像三维场景理解的自回归生成方法,称为局部随机访问序列(LRAS)建模。该方法利用局部块量化和随机排序的序列生成,旨在解决基于扩散模型的方法在复杂真实场景中保持对象和场景一致性的问题。实验表明,LRAS通过使用光流作为三维场景编辑的中间表示,实现了最先进的新视角合成和三维对象操作能力。此外,该框架通过对序列设计的简单修改,自然地扩展到自监督深度估计。LRAS在多个三维场景理解任务上表现出色,为构建下一代三维视觉模型提供了一个统一且有效的框架。
🔬 方法详解
问题定义:论文旨在解决单张图像的三维场景理解问题,特别是现有基于扩散模型的方法在复杂真实场景中难以保持对象和场景一致性的问题。这些方法在生成复杂场景时,容易出现物体形状扭曲、场景结构混乱等问题,限制了其在实际应用中的效果。
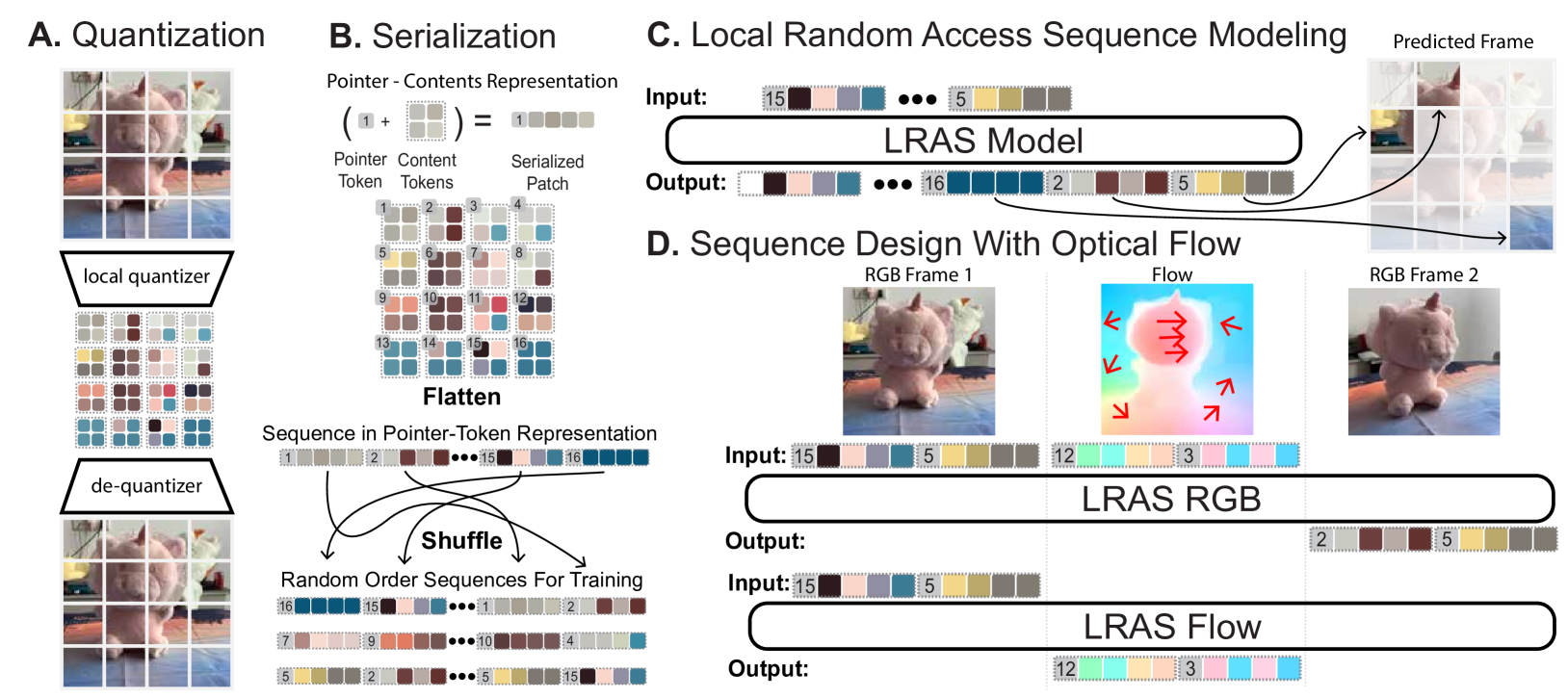
核心思路:论文的核心思路是利用自回归生成模型,通过局部随机访问序列(LRAS)建模来提升场景一致性。LRAS将三维场景分解为局部块,并以随机顺序生成这些块的量化表示。这种随机排序的方式有助于模型学习块之间的依赖关系,从而更好地保持场景的整体结构。
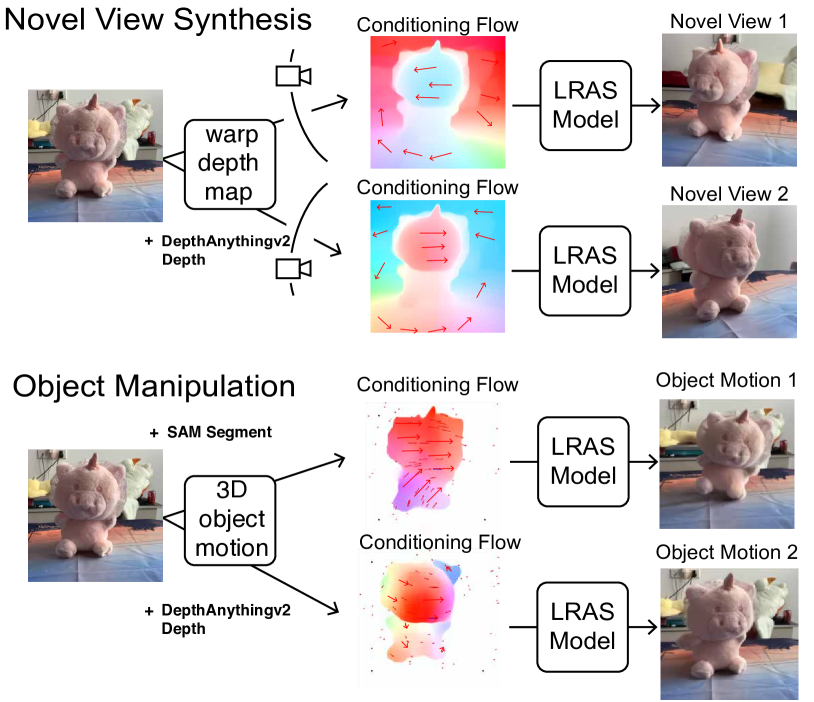
技术框架:LRAS框架主要包含以下几个阶段:1) 输入图像经过特征提取网络得到特征表示;2) 特征表示被划分为多个局部块;3) 每个局部块被量化为离散的码本索引;4) 这些码本索引以随机顺序输入到自回归序列模型中进行生成;5) 生成的序列被解码为三维场景表示,例如光流或深度图。光流被用作三维场景编辑的中间表示。
关键创新:LRAS的关键创新在于局部块量化和随机排序序列生成。局部块量化降低了模型的复杂度,使其更容易学习场景的局部结构。随机排序序列生成则打破了传统的序列生成顺序,使得模型能够更好地捕捉块之间的长距离依赖关系,从而提升场景的一致性。
关键设计:LRAS的关键设计包括:1) 使用光流作为三维场景编辑的中间表示,方便进行物体操作和视角合成;2) 设计了一种特殊的序列结构,使得模型能够自然地扩展到自监督深度估计任务;3) 采用了合适的损失函数来训练自回归序列模型,例如交叉熵损失或负对数似然损失。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LRAS在新的视角合成和三维物体操作任务上取得了state-of-the-art的性能。此外,通过简单的序列设计修改,LRAS能够有效地进行自监督深度估计,并在多个数据集上取得了具有竞争力的结果。这些结果验证了LRAS在三维场景理解任务上的有效性和通用性。
🎯 应用场景
该研究成果可广泛应用于增强现实、虚拟现实、机器人导航、三维场景编辑等领域。例如,在增强现实中,可以利用该方法从单张图像中重建三维场景,并将虚拟物体无缝地融入到真实场景中。在机器人导航中,可以利用该方法进行环境感知和地图构建,帮助机器人更好地理解周围环境。
📄 摘要(原文)
3D scene understanding from single images is a pivotal problem in computer vision with numerous downstream applications in graphics, augmented reality, and robotics. While diffusion-based modeling approaches have shown promise, they often struggle to maintain object and scene consistency, especially in complex real-world scenarios. To address these limitations, we propose an autoregressive generative approach called Local Random Access Sequence (LRAS) modeling, which uses local patch quantization and randomly ordered sequence generation. By utilizing optical flow as an intermediate representation for 3D scene editing, our experiments demonstrate that LRAS achieves state-of-the-art novel view synthesis and 3D object manipulation capabilities. Furthermore, we show that our framework naturally extends to self-supervised depth estimation through a simple modification of the sequence design. By achieving strong performance on multiple 3D scene understanding tasks, LRAS provides a unified and effective framework for building the next generation of 3D vision models.