MME-Unify: A Comprehensive Benchmark for Unified Multimodal Understanding and Generation Models
作者: Wulin Xie, Yi-Fan Zhang, Chaoyou Fu, Yang Shi, Bingyan Nie, Hongkai Chen, Zhang Zhang, Liang Wang, Tieniu Tan
分类: cs.CV
发布日期: 2025-04-04 (更新: 2025-04-07)
备注: Project page: https://mme-unify.github.io/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
MME-Unify:一个用于统一多模态理解与生成模型的综合性评测基准。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 统一模型 评测基准 多模态推理 图像生成
📋 核心要点
- 现有MLLM评测缺乏标准化基准和混合模态生成评估,难以有效评估U-MLLM。
- 提出MME-Unify,包含标准化传统任务评估和统一任务评估,全面评估U-MLLM。
- 评估了12个领先的U-MLLM,发现现有模型在混合模态任务上存在显著性能差距。
📝 摘要(中文)
现有的多模态大语言模型(MLLM)评测基准在评估统一多模态语言模型(U-MLLM)时面临重大挑战,原因在于:1)缺乏针对传统任务的标准化基准,导致比较不一致;2)缺乏混合模态生成基准,无法评估多模态推理能力。因此,本文提出了一个综合评估框架,旨在系统地评估U-MLLM。该基准包括:标准化的传统任务评估,从12个数据集采样,涵盖10个任务和30个子任务,确保跨研究的一致性和公平比较;统一的任务评估,引入了五个新颖的任务,测试多模态推理,包括图像编辑、带有图像生成的常识问答和几何推理;全面的模型基准测试,评估了12个领先的U-MLLM,以及专门的理解和生成模型。研究结果表明,现有的U-MLLM存在显著的性能差距,突出了对能够有效处理混合模态任务的更强大模型的需求。代码和评估数据可在https://mme-unify.github.io/找到。
🔬 方法详解
问题定义:现有MLLM评测基准在评估统一多模态语言模型(U-MLLM)时存在两个主要痛点。一是缺乏针对传统任务的标准化基准,导致不同研究之间的比较缺乏一致性和公平性。二是缺乏对混合模态生成能力的有效评估,无法全面考察模型的多模态推理能力。
核心思路:MME-Unify的核心思路是构建一个综合性的评测框架,既包含标准化的传统任务评估,又引入新的统一任务评估,从而全面、系统地评估U-MLLM的理解和生成能力。通过统一的评估标准,可以更准确地衡量不同模型之间的性能差异,并为未来的模型发展提供指导。
技术框架:MME-Unify框架主要包含两个部分:标准化的传统任务评估和统一的任务评估。标准化的传统任务评估部分,从12个数据集采样,涵盖10个任务和30个子任务,确保评估的覆盖面和一致性。统一的任务评估部分,引入了五个新颖的任务,包括图像编辑、带有图像生成的常识问答和几何推理,旨在测试模型的多模态推理能力。
关键创新:MME-Unify的关键创新在于其统一的任务评估部分,引入了五个新颖的多模态推理任务,这些任务需要模型同时理解和生成不同模态的信息,从而更全面地评估模型的多模态能力。此外,MME-Unify还提供了一个标准化的评估流程,使得不同模型之间的比较更加公平和可靠。
关键设计:在标准化的传统任务评估中,论文采用了统一的数据采样和评估指标,以确保评估的一致性。在统一的任务评估中,论文精心设计了五个新颖的任务,并为每个任务定义了明确的评估指标。例如,在图像编辑任务中,论文采用了图像质量和编辑效果等指标来评估模型的性能。具体的参数设置、损失函数和网络结构等技术细节取决于被评估的U-MLLM本身,MME-Unify主要提供评估框架和数据。
🖼️ 关键图片

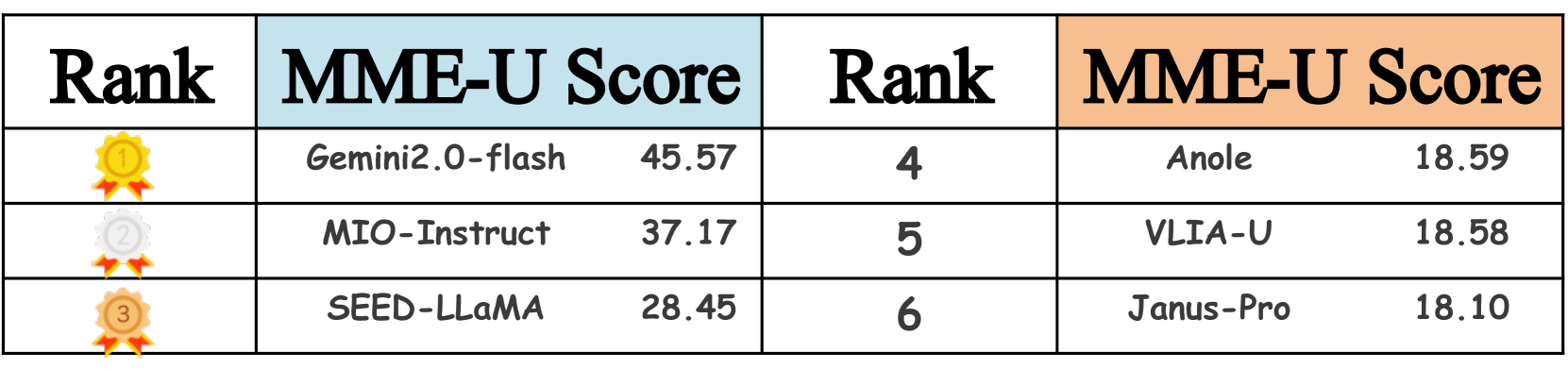

📊 实验亮点
MME-Unify评估了12个领先的U-MLLM,包括Janus-Pro、EMU3、VILA-U和Gemini2-flash,以及专门的理解和生成模型,如Claude-3.5-Sonnet和DALL-E-3。实验结果表明,现有U-MLLM在混合模态任务上存在显著的性能差距,突出了对更强大模型的需求。具体性能数据可在论文和相关网站上找到。
🎯 应用场景
MME-Unify可应用于多模态大语言模型的研发和评估,推动模型在图像编辑、常识推理、几何推理等领域的应用。该基准有助于提升模型在智能客服、内容创作、教育娱乐等领域的实际应用价值,并促进通用人工智能的发展。
📄 摘要(原文)
Existing MLLM benchmarks face significant challenges in evaluating Unified MLLMs (U-MLLMs) due to: 1) lack of standardized benchmarks for traditional tasks, leading to inconsistent comparisons; 2) absence of benchmarks for mixed-modality generation, which fails to assess multimodal reasoning capabilities. We present a comprehensive evaluation framework designed to systematically assess U-MLLMs. Our benchmark includes: Standardized Traditional Task Evaluation. We sample from 12 datasets, covering 10 tasks with 30 subtasks, ensuring consistent and fair comparisons across studies." 2. Unified Task Assessment. We introduce five novel tasks testing multimodal reasoning, including image editing, commonsense QA with image generation, and geometric reasoning. 3. Comprehensive Model Benchmarking. We evaluate 12 leading U-MLLMs, such as Janus-Pro, EMU3, VILA-U, and Gemini2-flash, alongside specialized understanding (e.g., Claude-3.5-Sonnet) and generation models (e.g., DALL-E-3). Our findings reveal substantial performance gaps in existing U-MLLMs, highlighting the need for more robust models capable of handling mixed-modality tasks effectively. The code and evaluation data can be found in https://mme-unify.github.io/.