HumanDreamer-X: Photorealistic Single-image Human Avatars Reconstruction via Gaussian Restoration
作者: Boyuan Wang, Runqi Ouyang, Xiaofeng Wang, Zheng Zhu, Guosheng Zhao, Chaojun Ni, Xiaopei Zhang, Guan Huang, Yijie Ren, Lihong Liu, Xingang Wang
分类: cs.CV
发布日期: 2025-04-04 (更新: 2025-11-12)
备注: Project Page: https://humandreamer-x.github.io/
💡 一句话要点
提出HumanDreamer-X以解决单图人类重建中的几何不一致问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱七:动作重定向 (Motion Retargeting)
关键词: 单图重建 3D高斯点云 几何一致性 视觉保真度 人类建模 注意力机制 多视图生成
📋 核心要点
- 现有方法在从单图生成多视图时存在几何不一致性,导致重建模型出现肢体模糊和碎片化问题。
- 提出HumanDreamer-X框架,将多视图生成与重建整合,利用3D高斯点云提供几何和外观优先级。
- 实验结果显示,生成和重建的PSNR分别提高了16.45%和12.65%,在多种数据集上表现出良好的泛化能力。
📝 摘要(中文)
单图人类重建对于数字人类建模应用至关重要,但仍然是一项极具挑战性的任务。现有方法依赖生成模型合成多视图图像以进行后续的3D重建和动画。然而,从单一图像直接生成多个视图存在几何不一致性,导致重建模型中出现肢体碎片或模糊等问题。为了解决这些局限性,我们提出了HumanDreamer-X,一个将多视图人类生成和重建整合为统一管道的新框架,显著增强了重建3D模型的几何一致性和视觉保真度。该框架中,3D高斯点云作为显式3D表示提供初始几何和外观优先级。在此基础上,HumanFixer被训练用于恢复3DGS渲染,确保获得照片级真实感的结果。此外,我们深入探讨了多视图人类生成中注意力机制的固有挑战,并提出了一种注意力调制策略,有效增强了多视图间几何细节的一致性。实验结果表明,我们的方法在生成和重建的PSNR质量指标上分别提高了16.45%和12.65%,达到25.62 dB的PSNR,同时在野外数据上展现了良好的泛化能力和对多种人类重建基础模型的适用性。
🔬 方法详解
问题定义:本论文旨在解决单图人类重建中的几何不一致性问题。现有方法在生成多视图图像时,常常导致重建模型中的肢体模糊和碎片化,影响最终效果。
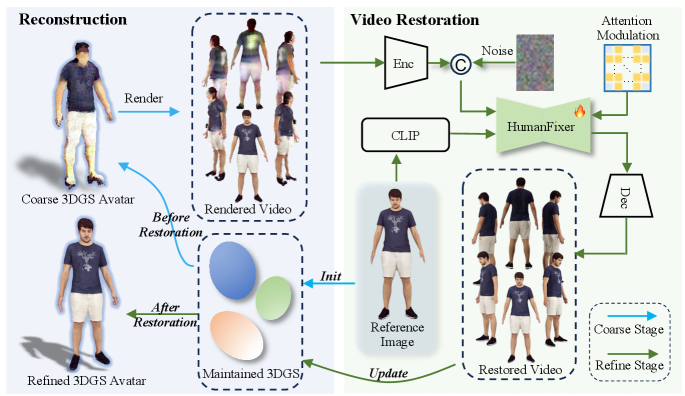
核心思路:我们提出的HumanDreamer-X框架通过将多视图生成与重建整合为一个统一的管道,显著提升了几何一致性和视觉保真度。3D高斯点云作为初始几何表示,确保了生成过程中的几何优先级。
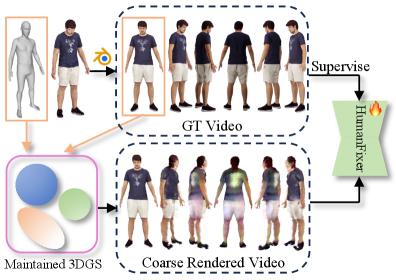
技术框架:该框架主要包含两个模块:首先是3D高斯点云生成模块,提供初始的几何和外观信息;其次是HumanFixer模块,负责恢复3DGS渲染,确保生成结果的真实感。
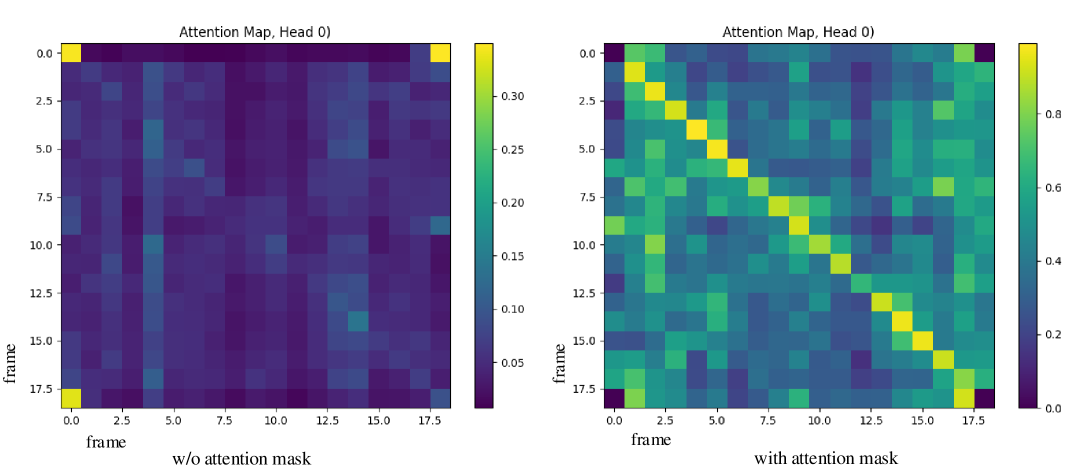
关键创新:最重要的创新在于将多视图生成与重建整合为一个统一的框架,并引入了注意力调制策略,增强了多视图间几何细节的一致性。这一设计与现有方法的分离生成和重建过程形成了鲜明对比。
关键设计:在模型设计中,我们采用了特定的损失函数来优化几何一致性,并通过调节注意力机制来提升多视图生成的细节表现。此外,网络结构经过精心设计,以适应3D高斯点云的处理需求。
🖼️ 关键图片
📊 实验亮点
实验结果表明,HumanDreamer-X在生成和重建的PSNR质量指标上分别提高了16.45%和12.65%,最终达到25.62 dB的PSNR。这一显著提升展示了该方法在几何一致性和视觉保真度方面的优势,并在多种人类重建基础模型上展现了良好的适用性。
🎯 应用场景
该研究的潜在应用领域包括虚拟现实、游戏开发、动画制作以及数字人类建模等。通过实现高质量的人类重建,能够为用户提供更加真实的交互体验,推动相关行业的发展。未来,该技术还可能扩展到医疗影像分析和人机交互等领域,具有广泛的实际价值和影响力。
📄 摘要(原文)
Single-image human reconstruction is vital for digital human modeling applications but remains an extremely challenging task. Current approaches rely on generative models to synthesize multi-view images for subsequent 3D reconstruction and animation. However, directly generating multiple views from a single human image suffers from geometric inconsistencies, resulting in issues like fragmented or blurred limbs in the reconstructed models. To tackle these limitations, we introduce \textbf{HumanDreamer-X}, a novel framework that integrates multi-view human generation and reconstruction into a unified pipeline, which significantly enhances the geometric consistency and visual fidelity of the reconstructed 3D models. In this framework, 3D Gaussian Splatting serves as an explicit 3D representation to provide initial geometry and appearance priority. Building upon this foundation, \textbf{HumanFixer} is trained to restore 3DGS renderings, which guarantee photorealistic results. Furthermore, we delve into the inherent challenges associated with attention mechanisms in multi-view human generation, and propose an attention modulation strategy that effectively enhances geometric details identity consistency across multi-view. Experimental results demonstrate that our approach markedly improves generation and reconstruction PSNR quality metrics by 16.45% and 12.65%, respectively, achieving a PSNR of up to 25.62 dB, while also showing generalization capabilities on in-the-wild data and applicability to various human reconstruction backbone models.