Mamba as a Bridge: Where Vision Foundation Models Meet Vision Language Models for Domain-Generalized Semantic Segmentation
作者: Xin Zhang, Robby T. Tan
分类: cs.CV
发布日期: 2025-04-04 (更新: 2025-04-15)
备注: Accepted to CVPR 2025 (Highlight)
🔗 代码/项目: GITHUB
💡 一句话要点
提出MFuser,利用Mamba融合视觉和视觉-语言模型,提升领域泛化语义分割性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 领域泛化语义分割 视觉基础模型 视觉-语言模型 Mamba架构 特征融合
📋 核心要点
- 现有领域泛化语义分割方法未能有效融合视觉基础模型和视觉-语言模型的互补优势,尤其是在长序列建模中面临挑战。
- 提出MFuser,利用Mamba架构高效融合视觉和视觉-语言模型的特征,同时设计MVFuser和MTEnhancer模块增强模型性能。
- 实验结果表明,MFuser在多个领域泛化语义分割基准测试中显著优于现有方法,验证了其有效性和优越性。
📝 摘要(中文)
视觉基础模型(VFMs)和视觉-语言模型(VLMs)因其强大的泛化能力在领域泛化语义分割(DGSS)中备受关注。然而,现有的DGSS方法通常只依赖于VFMs或VLMs,忽略了它们互补的优势。VFMs(如DINOv2)擅长捕捉细粒度特征,而VLMs(如CLIP)提供强大的文本对齐能力,但在粗粒度方面表现不佳。尽管它们具有互补的优势,但使用注意力机制有效地整合VFMs和VLMs具有挑战性,因为增加的patch tokens会使长序列建模变得复杂。为了解决这个问题,我们提出MFuser,一种新颖的基于Mamba的融合框架,它有效地结合了VFMs和VLMs的优势,同时保持了序列长度的线性可扩展性。MFuser由两个关键组件组成:MVFuser,它作为一个co-adapter,通过捕捉序列和空间动态来联合微调这两个模型;以及MTEnhancer,一个混合注意力-Mamba模块,通过结合图像先验来细化文本嵌入。我们的方法实现了精确的特征局部性和强大的文本对齐,而不会产生显著的计算开销。大量的实验表明,MFuser显著优于最先进的DGSS方法,在synthetic-to-real基准上实现了68.20 mIoU,在real-to-real基准上实现了71.87 mIoU。代码可在https://github.com/devinxzhang/MFuser获取。
🔬 方法详解
问题定义:领域泛化语义分割(DGSS)旨在训练一个模型,使其在未见过的目标领域上也能表现良好。现有的DGSS方法通常只依赖于视觉基础模型(VFMs)或视觉-语言模型(VLMs),而忽略了它们各自的优势。VFMs擅长捕捉图像的细粒度特征,而VLMs则擅长进行文本对齐。然而,直接融合这两种模型面临挑战,特别是当使用注意力机制时,由于patch tokens数量的增加,导致长序列建模的计算复杂度显著增加。
核心思路:MFuser的核心思路是利用Mamba架构的线性可扩展性来高效融合VFMs和VLMs的特征。Mamba架构能够处理长序列数据,并且计算复杂度与序列长度呈线性关系,这使得它非常适合融合来自VFMs和VLMs的大量patch tokens。此外,MFuser还设计了MVFuser和MTEnhancer两个模块,分别用于联合微调VFMs和VLMs,以及增强文本嵌入。
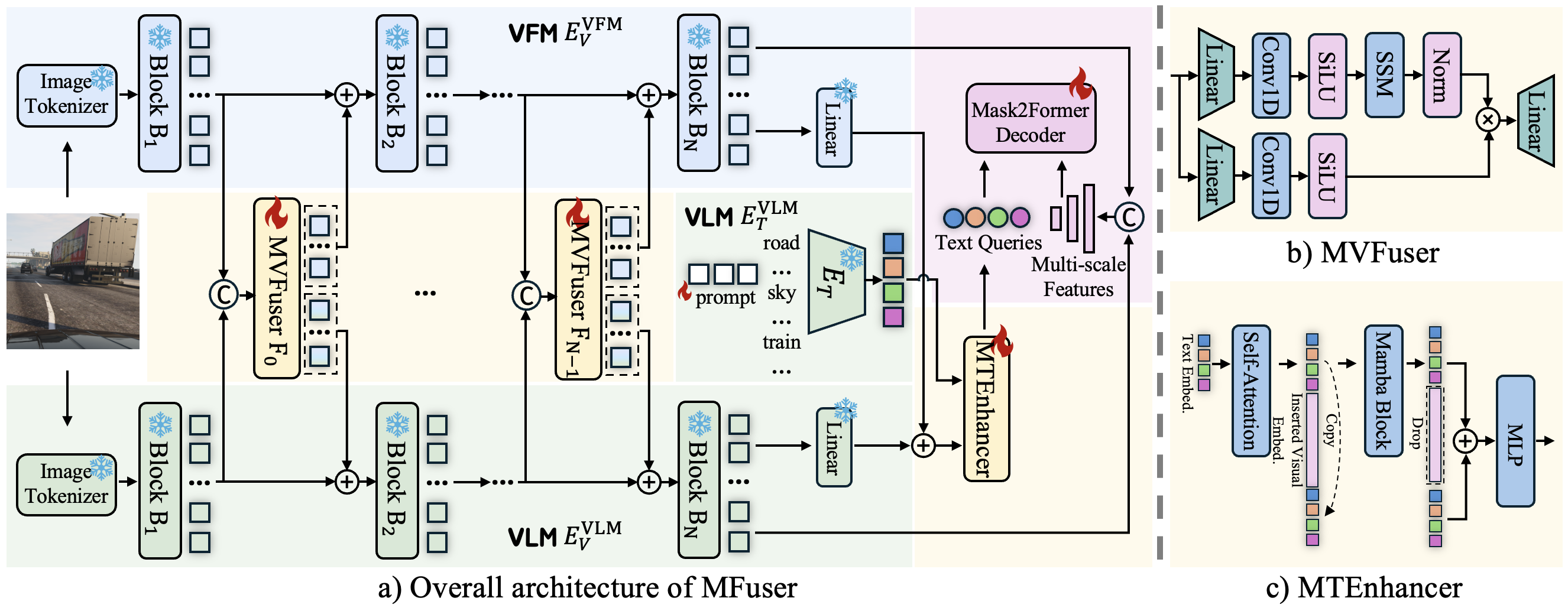
技术框架:MFuser的整体框架包括三个主要部分:视觉基础模型(VFM),视觉-语言模型(VLM),以及Mamba融合模块。首先,输入图像分别通过VFM(如DINOv2)和VLM(如CLIP)提取视觉特征和文本特征。然后,MVFuser模块作为一个co-adapter,联合微调VFM和VLM,捕捉序列和空间动态。接着,MTEnhancer模块利用混合注意力-Mamba机制,通过结合图像先验来细化文本嵌入。最后,融合后的特征被用于语义分割任务。
关键创新:MFuser的关键创新在于使用Mamba架构作为桥梁,连接视觉基础模型和视觉-语言模型。与传统的注意力机制相比,Mamba架构具有线性可扩展性,能够高效处理长序列数据。此外,MVFuser模块通过联合微调VFM和VLM,实现了更好的特征对齐。MTEnhancer模块则通过结合图像先验,进一步增强了文本嵌入的表达能力。
关键设计:MVFuser模块采用了一种co-adapter结构,通过共享参数来联合微调VFM和VLM。MTEnhancer模块则结合了自注意力机制和Mamba架构,利用自注意力机制捕捉全局上下文信息,并利用Mamba架构处理长序列依赖关系。损失函数方面,使用了交叉熵损失函数来优化语义分割结果。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片
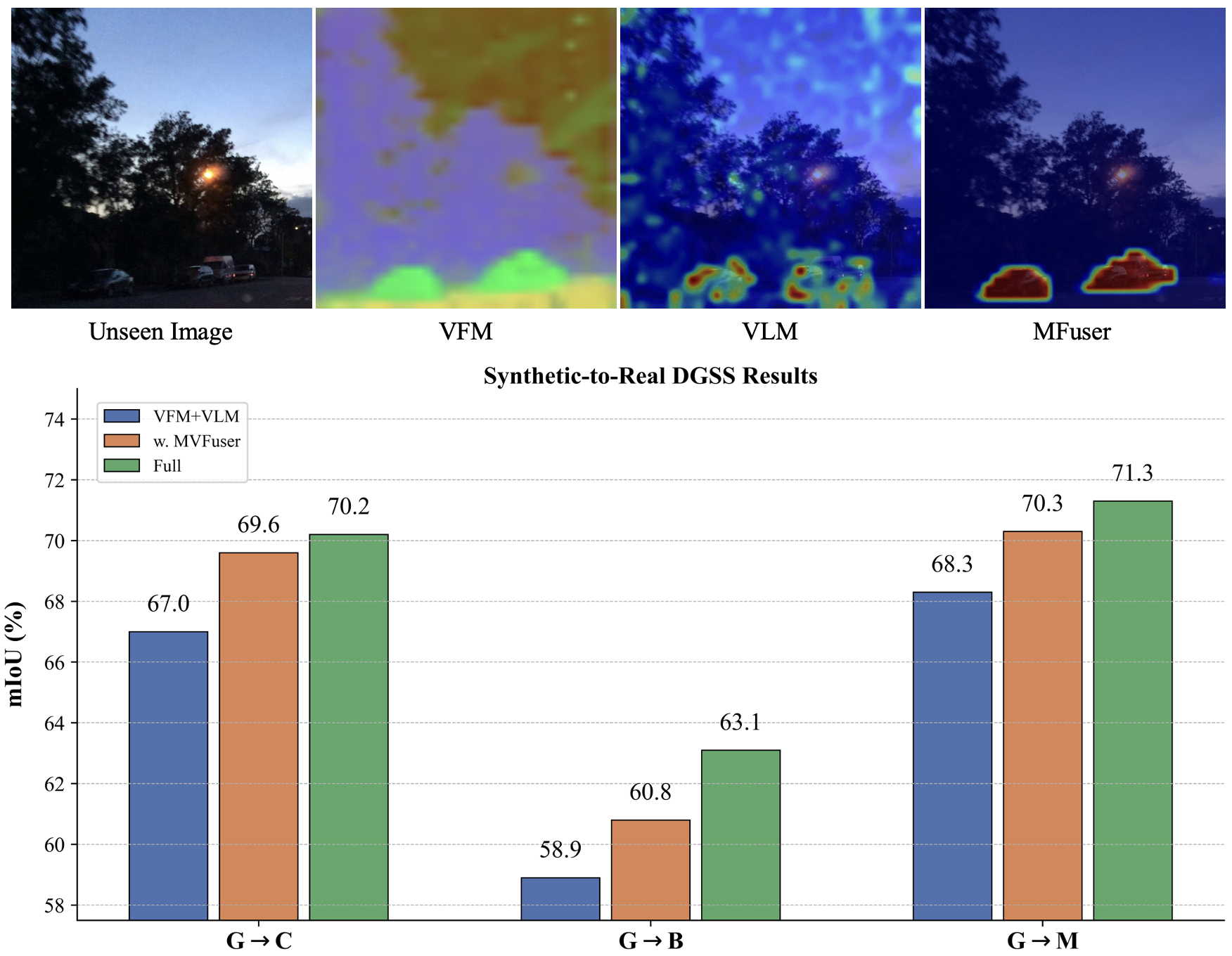

📊 实验亮点
MFuser在synthetic-to-real和real-to-real两个DGSS基准测试中均取得了显著的性能提升。在synthetic-to-real基准上,MFuser达到了68.20 mIoU,在real-to-real基准上达到了71.87 mIoU,显著优于现有的state-of-the-art方法,证明了其在领域泛化语义分割任务中的有效性。
🎯 应用场景
该研究成果可应用于自动驾驶、遥感图像分析、医学图像诊断等领域。通过提升模型在不同领域环境下的泛化能力,可以减少对大量标注数据的依赖,降低模型部署成本,并提高实际应用中的可靠性。
📄 摘要(原文)
Vision Foundation Models (VFMs) and Vision-Language Models (VLMs) have gained traction in Domain Generalized Semantic Segmentation (DGSS) due to their strong generalization capabilities. However, existing DGSS methods often rely exclusively on either VFMs or VLMs, overlooking their complementary strengths. VFMs (e.g., DINOv2) excel at capturing fine-grained features, while VLMs (e.g., CLIP) provide robust text alignment but struggle with coarse granularity. Despite their complementary strengths, effectively integrating VFMs and VLMs with attention mechanisms is challenging, as the increased patch tokens complicate long-sequence modeling. To address this, we propose MFuser, a novel Mamba-based fusion framework that efficiently combines the strengths of VFMs and VLMs while maintaining linear scalability in sequence length. MFuser consists of two key components: MVFuser, which acts as a co-adapter to jointly fine-tune the two models by capturing both sequential and spatial dynamics; and MTEnhancer, a hybrid attention-Mamba module that refines text embeddings by incorporating image priors. Our approach achieves precise feature locality and strong text alignment without incurring significant computational overhead. Extensive experiments demonstrate that MFuser significantly outperforms state-of-the-art DGSS methods, achieving 68.20 mIoU on synthetic-to-real and 71.87 mIoU on real-to-real benchmarks. The code is available at https://github.com/devinxzhang/MFuser.