Scaling Open-Vocabulary Action Detection
作者: Zhen Hao Sia, Yogesh Singh Rawat
分类: cs.CV
发布日期: 2025-04-04 (更新: 2025-08-14)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出一种可扩展的开放词汇动作检测方法,解决现有方法对大规模数据集和参数量大的依赖。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 开放词汇动作检测 多模态学习 弱监督学习 视频理解 动作识别
📋 核心要点
- 现有动作检测方法依赖封闭数据集和复杂架构,难以扩展到开放词汇场景,且缺乏大规模数据集支持。
- 论文提出一种仅编码器的多模态模型,并采用弱监督训练策略,降低对参数量和大规模标注数据的依赖。
- 设计新的评估基准,在封闭集数据集上评估开放词汇动作检测能力,为未来研究提供基线。
📝 摘要(中文)
本文致力于扩展开放词汇动作检测。现有的动作检测方法主要局限于封闭集场景,并且依赖于复杂的、参数量大的架构。将这些模型扩展到开放词汇设置面临两个关键挑战:(1)缺乏具有大量动作类别的大规模数据集来进行鲁棒训练;(2)对预训练的视觉-语言对比模型进行参数量大的调整以将其转换为检测模型,这可能会导致额外的非预训练参数过度拟合到基本动作类别。首先,我们引入了一个仅编码器的多模态模型用于视频动作检测,减少了对视频动作检测中参数量大的附加组件的依赖。其次,我们引入了一个简单的弱监督训练策略,以利用现有的封闭集动作检测数据集进行预训练。最后,我们放弃了先前开放词汇动作检测工作中使用的不适定的基础到新颖的基准,并设计了一个新的基准,以评估现有的封闭集动作检测数据集,而无需将它们用于训练,展示了新的结果,作为未来工作的基础。
🔬 方法详解
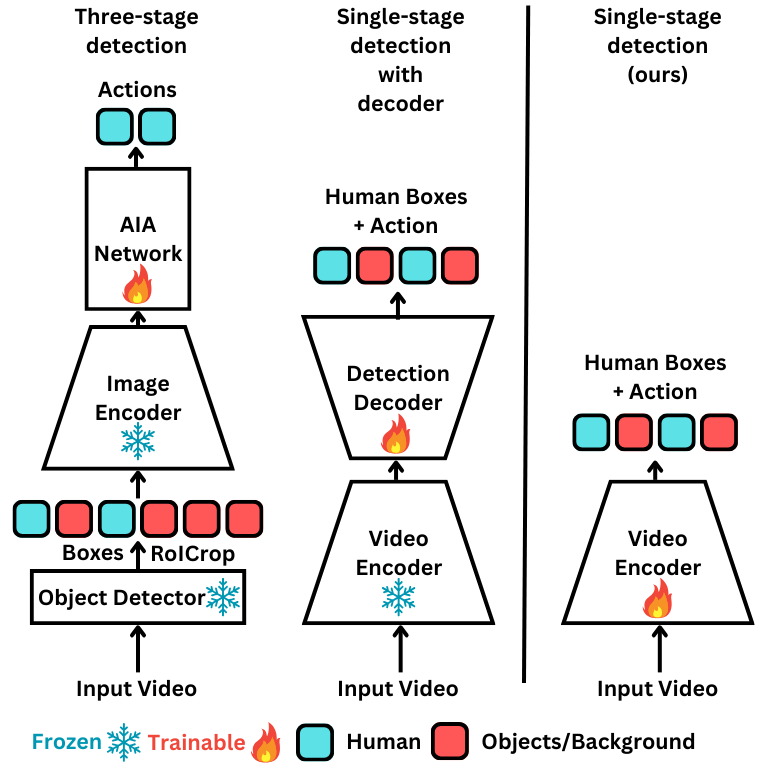
问题定义:现有动作检测方法主要针对封闭集,依赖大量标注数据和复杂模型结构,难以泛化到开放词汇场景。现有方法在扩展到开放词汇时,需要对预训练的视觉-语言模型进行大量参数调整,容易过拟合到已知的动作类别,导致对新类别识别能力不足。
核心思路:论文的核心思路是减少对大规模标注数据和复杂模型结构的依赖,通过设计一个更轻量级的模型结构和有效的弱监督训练策略,提升模型在开放词汇场景下的泛化能力。同时,设计新的评估基准,更真实地反映模型在开放词汇场景下的性能。
技术框架:论文提出的方法主要包含以下几个模块:1) 一个仅编码器的多模态模型,用于提取视频特征和文本特征;2) 一个弱监督训练策略,利用现有的封闭集动作检测数据集进行预训练;3) 一个新的评估基准,用于评估模型在开放词汇场景下的性能。整体流程是先使用弱监督训练策略在封闭集数据集上预训练模型,然后在新的评估基准上评估模型的性能。
关键创新:论文的关键创新点在于:1) 提出了一个仅编码器的多模态模型,减少了模型参数量,降低了过拟合的风险;2) 提出了一个弱监督训练策略,利用现有的封闭集数据集进行预训练,缓解了缺乏大规模标注数据的问题;3) 设计了一个新的评估基准,更真实地反映了模型在开放词汇场景下的性能。
关键设计:论文的关键设计包括:1) 模型结构:采用仅编码器的多模态模型,避免了复杂的解码器结构,降低了模型参数量;2) 弱监督训练策略:利用现有的封闭集数据集,通过某种方式(具体细节未知)进行预训练,提升模型在开放词汇场景下的泛化能力;3) 评估基准:设计新的评估指标和数据集划分方式,更真实地反映模型在开放词汇场景下的性能。
🖼️ 关键图片


📊 实验亮点
论文提出了新的评估基准,并在该基准上进行了实验,展示了新的结果,为未来的开放词汇动作检测研究提供了基线。具体的性能数据和对比基线未知,但论文强调了其结果是 novel 的,表明其性能具有一定的竞争力。
🎯 应用场景
该研究成果可应用于智能监控、视频内容分析、人机交互等领域。例如,在智能监控中,可以检测视频中出现的异常行为,并进行预警。在视频内容分析中,可以自动识别视频中的动作,并生成相应的标签。在人机交互中,可以识别用户的动作,并根据用户的动作做出相应的反应。未来,该研究可以进一步扩展到更复杂的场景,例如自动驾驶、机器人等。
📄 摘要(原文)
In this work, we focus on scaling open-vocabulary action detection. Existing approaches for action detection are predominantly limited to closed-set scenarios and rely on complex, parameter-heavy architectures. Extending these models to the open-vocabulary setting poses two key challenges: (1) the lack of large-scale datasets with many action classes for robust training, and (2) parameter-heavy adaptations to a pretrained vision-language contrastive model to convert it for detection, risking overfitting the additional non-pretrained parameters to base action classes. Firstly, we introduce an encoder-only multimodal model for video action detection, reducing the reliance on parameter-heavy additions for video action detection. Secondly, we introduce a simple weakly supervised training strategy to exploit an existing closed-set action detection dataset for pretraining. Finally, we depart from the ill-posed base-to-novel benchmark used by prior works in open-vocabulary action detection and devise a new benchmark to evaluate on existing closed-set action detection datasets without ever using them for training, showing novel results to serve as baselines for future work. Our code is available at https://siatheindochinese.github.io/sia_act_page/ .