Sparse Autoencoders Learn Monosemantic Features in Vision-Language Models
作者: Mateusz Pach, Shyamgopal Karthik, Quentin Bouniot, Serge Belongie, Zeynep Akata
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-04-03 (更新: 2025-11-27)
备注: Accepted at NeurIPS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于稀疏自编码器的视觉-语言模型单义性特征学习方法,提升可解释性和可控性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 稀疏自编码器 视觉-语言模型 可解释性 单义性特征 AI安全
📋 核心要点
- 现有视觉-语言模型的可解释性和可控性不足,限制了其在安全关键领域的应用。
- 利用稀疏自编码器学习视觉表征的单义性特征,从而提升模型的可解释性和可控性。
- 实验表明,该方法显著增强了神经元的单义性,并能直接引导多模态LLM的输出。
📝 摘要(中文)
本文提出了一种利用稀疏自编码器(SAEs)提升视觉-语言模型(VLMs)可解释性和可控性的方法,这对于AI安全至关重要。我们将SAEs的应用扩展到诸如CLIP等VLMs,并引入了一个全面的框架,用于评估视觉表示中神经元级别的单义性。为了确保评估与人类感知对齐,我们提出了一个源自大规模用户研究的基准。实验结果表明,在VLMs上训练的SAEs显著增强了单个神经元的单义性,其中稀疏性和宽潜在空间是最具影响力的因素。此外,我们证明了对CLIP视觉编码器应用SAE干预可以直接引导多模态LLM输出(例如LLaVA),而无需修改底层语言模型。这些发现强调了SAEs作为一种无监督工具在增强VLMs的可解释性和控制方面的实用性和有效性。
🔬 方法详解
问题定义:现有视觉-语言模型(VLMs)的可解释性较差,难以理解模型内部神经元表示的含义,同时也缺乏有效的控制手段,难以按照预期的方式引导模型的行为。这限制了VLMs在安全敏感领域的应用,例如自动驾驶、医疗诊断等。现有方法通常依赖于事后分析或有监督的微调,难以实现对模型内部表征的直接干预和控制。
核心思路:本文的核心思路是利用稀疏自编码器(SAEs)学习VLMs视觉编码器中更具单义性的特征表示。SAEs通过引入稀疏性约束,鼓励每个神经元只对少数几个概念或特征做出响应,从而提高神经元表示的语义纯度。通过对学习到的单义性特征进行干预,可以实现对VLMs行为的精确控制。
技术框架:整体框架包括以下几个主要步骤:1) 使用CLIP等VLM提取视觉特征;2) 在提取的视觉特征上训练稀疏自编码器;3) 设计评估指标,衡量SAEs学习到的特征的单义性;4) 通过干预SAEs的激活,控制VLM的行为,例如引导多模态LLM的输出。
关键创新:最重要的创新点在于将SAEs应用于VLMs,并提出了一种评估视觉表示单义性的综合框架。与以往主要关注LLMs的SAEs研究不同,本文专注于视觉模态,并设计了专门针对视觉特征的评估指标和干预策略。此外,本文还提出了一个基于用户研究的基准,用于评估单义性与人类感知的对齐程度。
关键设计:关键设计包括:1) 稀疏自编码器的结构,包括编码器和解码器的层数、神经元数量等;2) 稀疏性约束的强度,通常通过L1正则化实现;3) 损失函数的设计,除了重构损失外,还可能包含其他正则化项;4) 评估单义性的指标,例如神经元激活与特定概念的相关性;5) 干预策略,例如直接修改SAEs的激活值或使用SAEs的输出来引导其他模型的行为。
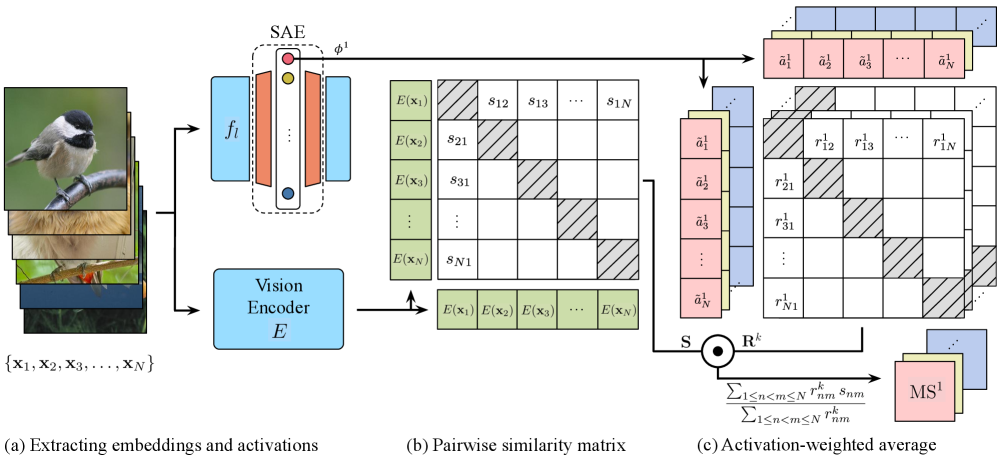
🖼️ 关键图片


📊 实验亮点
实验结果表明,在VLMs上训练的SAEs显著增强了单个神经元的单义性。通过对CLIP视觉编码器应用SAE干预,可以直接引导多模态LLM(例如LLaVA)的输出,而无需修改底层语言模型。研究还发现,稀疏性和宽潜在空间是影响单义性的最关键因素。该研究提供了一个评估视觉表示单义性的基准,并开源了代码和数据。
🎯 应用场景
该研究成果可应用于提升视觉-语言模型在图像理解、目标检测、图像生成等任务中的可解释性和可控性。例如,在自动驾驶领域,可以利用该方法理解模型对场景的判断依据,并避免模型做出错误的决策。在医疗诊断领域,可以帮助医生理解模型对病灶的识别过程,提高诊断的准确性和可靠性。此外,该方法还可以用于开发更安全、更可靠的人工智能系统。
📄 摘要(原文)
Sparse Autoencoders (SAEs) have recently gained attention as a means to improve the interpretability and steerability of Large Language Models (LLMs), both of which are essential for AI safety. In this work, we extend the application of SAEs to Vision-Language Models (VLMs), such as CLIP, and introduce a comprehensive framework for evaluating monosemanticity at the neuron-level in visual representations. To ensure that our evaluation aligns with human perception, we propose a benchmark derived from a large-scale user study. Our experimental results reveal that SAEs trained on VLMs significantly enhance the monosemanticity of individual neurons, with sparsity and wide latents being the most influential factors. Further, we demonstrate that applying SAE interventions on CLIP's vision encoder directly steers multimodal LLM outputs (e.g., LLaVA), without any modifications to the underlying language model. These findings emphasize the practicality and efficacy of SAEs as an unsupervised tool for enhancing both interpretability and control of VLMs. Code and benchmark data are available at https://github.com/ExplainableML/sae-for-vlm.