Learning Phase Distortion with Selective State Space Models for Video Turbulence Mitigation
作者: Xingguang Zhang, Nicholas Chimitt, Xijun Wang, Yu Yuan, Stanley H. Chan
分类: cs.CV, eess.IV
发布日期: 2025-04-03 (更新: 2025-05-13)
备注: CVPR 2025 Highlight (extended), project page: https://xg416.github.io/MambaTM/
💡 一句话要点
提出基于选择性状态空间模型的视频湍流抑制方法,提升长距离成像质量。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视频湍流抑制 选择性状态空间模型 Mamba 潜在相位畸变 长距离成像 图像恢复 深度学习
📋 核心要点
- 现有基于卷积的方法感受野有限,难以处理湍流引起的大范围空间依赖;基于自注意力的方法复杂度高,难以扩展到多帧。
- 论文提出基于选择性状态空间模型(MambaTM)的湍流抑制网络,利用学习到的潜在相位畸变(LPD)指导模型,提升湍流退化估计能力。
- 实验结果表明,该方法在合成和真实数据集上均超越了现有最优方法,并显著提升了推理速度。
📝 摘要(中文)
本文提出了一种新的视频湍流抑制(TM)方法,该方法基于两个核心概念:(1)基于选择性状态空间模型(MambaTM)的湍流抑制网络。MambaTM在空间和时间维度上,在每一层都提供了全局感受野,同时保持了线性计算复杂度。(2)学习到的潜在相位畸变(LPD)。LPD用于指导状态空间模型。与传统的基于Zernike的相位畸变表示不同,新的LPD图能够独特地捕捉湍流的实际影响,通过减少病态性,显著提高模型估计退化的能力。在各种合成和真实世界的TM基准测试中,我们提出的方法超过了当前最先进的网络,并且具有明显更快的推理速度。
🔬 方法详解
问题定义:长距离成像系统中,大气湍流是图像质量下降的主要原因。现有的基于深度学习的湍流抑制方法存在速度慢、内存消耗大、泛化能力差等问题。空间域方法受限于卷积算子的感受野,无法处理湍流引起的大范围空间依赖;时间域方法如自注意力机制,虽然理论上可以利用湍流的“幸运效应”,但其二次复杂度使其难以扩展到大量帧。传统的循环聚合方法则面临并行化挑战。
核心思路:论文的核心思路是利用选择性状态空间模型(Selective State Space Model, Mamba)来建模视频中的时空依赖关系,并引入学习到的潜在相位畸变(Learned Latent Phase Distortion, LPD)来指导状态空间模型的学习。Mamba模型具有线性复杂度,可以处理长序列,而LPD则可以更准确地捕捉湍流的实际影响,从而提高模型的性能。
技术框架:该方法主要包含两个核心模块:MambaTM网络和LPD模块。MambaTM网络是基于Mamba架构构建的湍流抑制网络,用于从湍流视频中恢复清晰的图像。LPD模块用于学习潜在的相位畸变,并将这些畸变信息传递给MambaTM网络,以指导其学习过程。整体流程是:输入湍流视频帧,LPD模块提取潜在相位畸变,MambaTM网络利用LPD信息进行湍流抑制,输出清晰图像。
关键创新:该方法最重要的创新点在于将选择性状态空间模型(Mamba)应用于视频湍流抑制任务,并结合学习到的潜在相位畸变(LPD)来指导模型的学习。与传统的卷积或循环神经网络相比,Mamba具有全局感受野和线性复杂度,可以更好地处理长时序依赖关系。与基于Zernike多项式的相位畸变表示相比,LPD能够更准确地捕捉湍流的实际影响。
关键设计:LPD模块的具体实现细节(例如网络结构、损失函数等)以及MambaTM网络的具体参数设置(例如层数、通道数等)在论文中可能有所描述,但此处未知。选择合适的损失函数来训练LPD模块,使其能够准确地捕捉湍流的相位畸变信息至关重要。MambaTM网络的设计需要充分考虑湍流抑制任务的特点,例如如何有效地利用LPD信息,如何平衡模型的复杂度和性能等。
🖼️ 关键图片
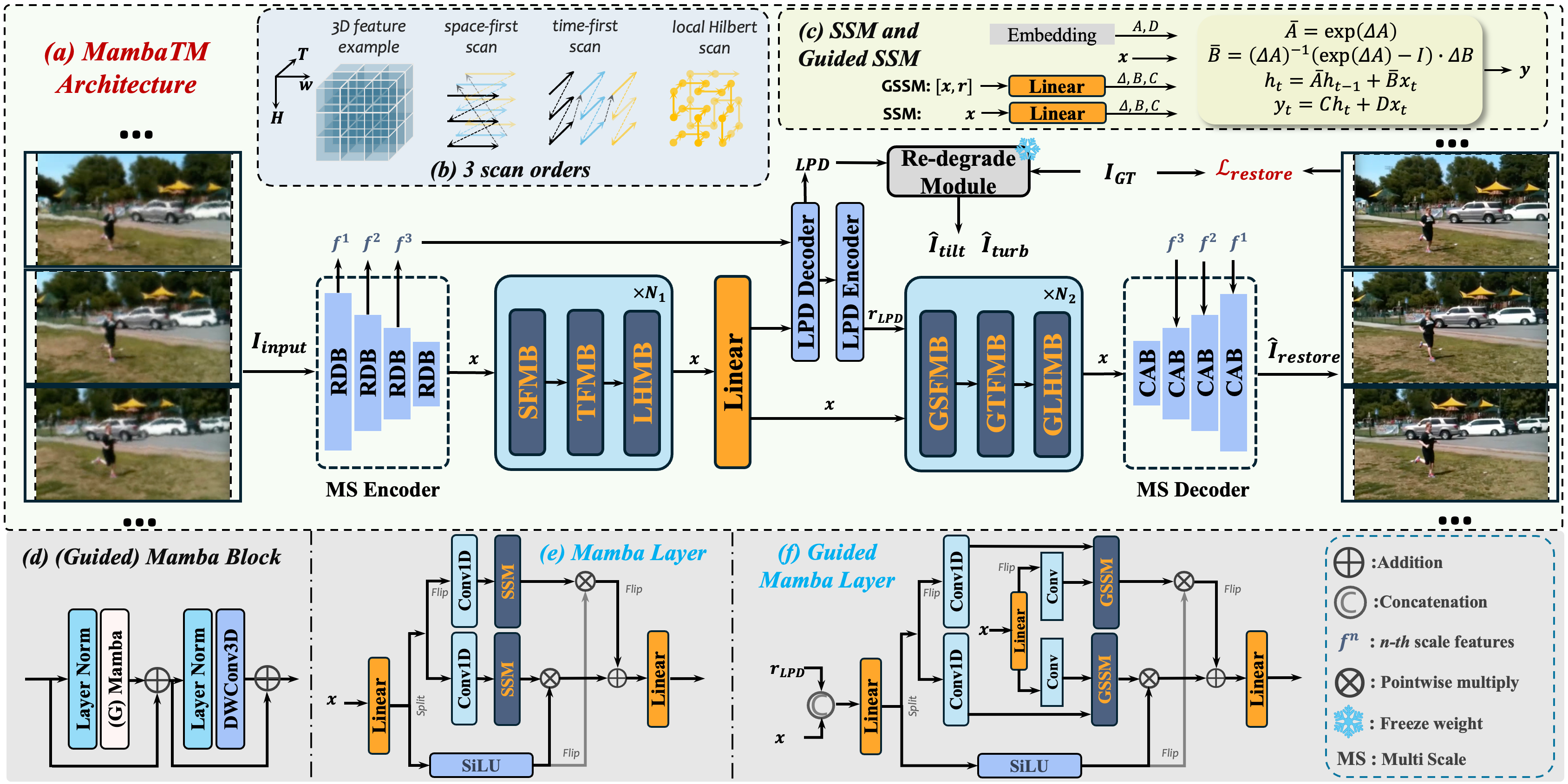


📊 实验亮点
该方法在合成和真实世界的湍流抑制基准测试中均取得了显著的性能提升,超越了当前最先进的网络。此外,该方法具有更快的推理速度,使其更适用于实时应用场景。具体的性能数据和对比基线需要在论文中查找。
🎯 应用场景
该研究成果可应用于各种长距离成像系统,例如远程监控、天文观测、军事侦察等领域。通过有效抑制大气湍流,可以显著提高成像质量,从而提升目标识别、跟踪和分析的准确性。未来,该技术有望在智能交通、安防监控等领域发挥重要作用。
📄 摘要(原文)
Atmospheric turbulence is a major source of image degradation in long-range imaging systems. Although numerous deep learning-based turbulence mitigation (TM) methods have been proposed, many are slow, memory-hungry, and do not generalize well. In the spatial domain, methods based on convolutional operators have a limited receptive field, so they cannot handle a large spatial dependency required by turbulence. In the temporal domain, methods relying on self-attention can, in theory, leverage the lucky effects of turbulence, but their quadratic complexity makes it difficult to scale to many frames. Traditional recurrent aggregation methods face parallelization challenges. In this paper, we present a new TM method based on two concepts: (1) A turbulence mitigation network based on the Selective State Space Model (MambaTM). MambaTM provides a global receptive field in each layer across spatial and temporal dimensions while maintaining linear computational complexity. (2) Learned Latent Phase Distortion (LPD). LPD guides the state space model. Unlike classical Zernike-based representations of phase distortion, the new LPD map uniquely captures the actual effects of turbulence, significantly improving the model's capability to estimate degradation by reducing the ill-posedness. Our proposed method exceeds current state-of-the-art networks on various synthetic and real-world TM benchmarks with significantly faster inference speed.