SelfMedHPM: Self Pre-training With Hard Patches Mining Masked Autoencoders For Medical Image Segmentation
作者: Yunhao Lv, Lingyu Chen, Jian Wang, Yangxi Li, Fang Chen
分类: cs.CV
发布日期: 2025-04-03
备注: arXiv admin note: text overlap with arXiv:2304.05919 by other authors
💡 一句话要点
SelfMedHPM:基于难样本挖掘掩码自编码器的医学图像分割自监督预训练
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 医学图像分割 自监督学习 掩码图像建模 难样本挖掘 CT图像 多器官分割 ViT 预训练
📋 核心要点
- 现有基于掩码图像建模的CT多器官分割方法有限,且未能有效识别和利用最难重建的区域。
- SelfMedHPM通过引入辅助损失预测器,挖掘难样本区域,指导掩码策略,从而提升模型重建能力。
- 在BTCV和SMWB数据集上的实验表明,SelfMedHPM在腹部和全身CT多器官分割任务中均优于现有方法。
📝 摘要(中文)
近年来,卷积神经网络(CNN)和Transformer等深度学习方法在CT多器官分割方面取得了显著进展。然而,基于掩码图像建模(MIM)的CT多器官分割方法仍然非常有限。虽然已经有方法使用MAE进行CT多器官分割任务,但我们认为现有方法未能识别出最难重建的区域。为此,我们提出了一种MIM自训练框架,该框架采用难样本挖掘掩码自编码器用于CT多器官分割任务(selfMedHPM)。该方法在目标数据的训练集上执行ViT自预训练,并引入一个辅助损失预测器,该预测器首先预测patch损失,然后确定下一个掩码的位置。在腹部CT多器官分割和全身CT多器官分割中,SelfMedHPM的实现优于各种具有竞争力的算法。我们已经在用于腹部多器官分割的Multi Atlas Labeling Beyond The Cranial Vault (BTCV)数据集和用于全身多器官分割任务的SinoMed Whole Body (SMWB)数据集上验证了我们方法的性能。
🔬 方法详解
问题定义:论文旨在解决CT多器官分割中,现有基于掩码图像建模方法未能有效利用难样本的问题。现有方法通常采用随机掩码策略,忽略了不同区域重建难度的差异,导致模型学习效率不高,分割精度受限。
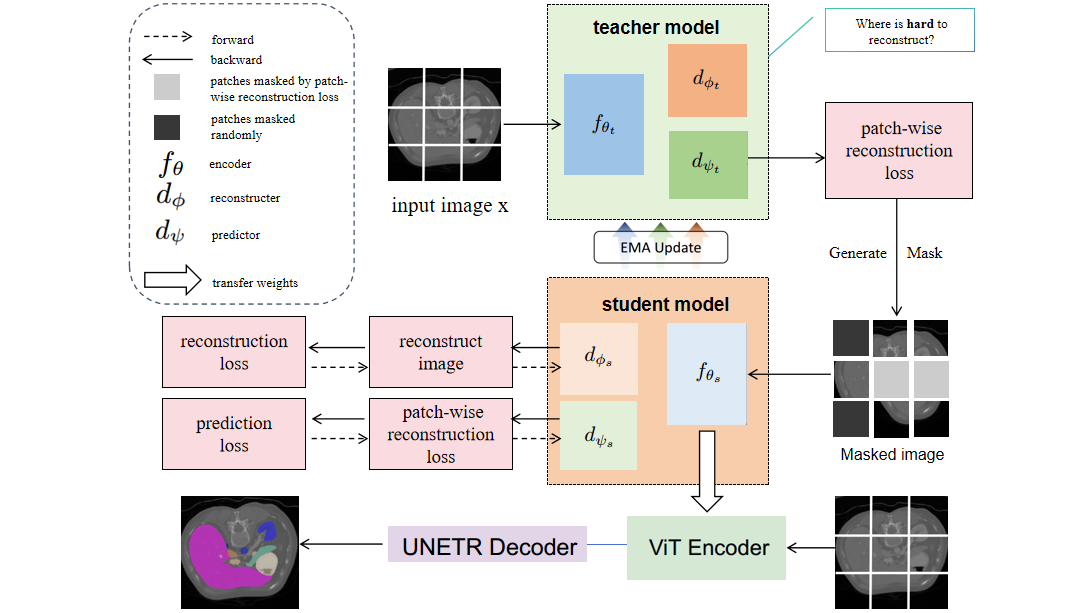
核心思路:论文的核心思路是通过难样本挖掘来指导掩码策略,使模型更多地关注难以重建的区域。具体来说,引入一个辅助损失预测器,用于预测每个patch的重建损失,并根据预测的损失值来确定下一个要掩码的区域。
技术框架:SelfMedHPM框架主要包含三个阶段:1) ViT自预训练:使用ViT作为主干网络,在目标数据集上进行自监督预训练;2) 难样本挖掘:引入辅助损失预测器,预测每个patch的重建损失;3) 掩码策略优化:根据预测的损失值,选择损失较高的patch进行掩码,从而使模型更多地关注难样本区域。
关键创新:论文的关键创新在于提出了基于难样本挖掘的掩码策略。与传统的随机掩码策略不同,SelfMedHPM能够自适应地选择难以重建的区域进行掩码,从而提高模型的学习效率和分割精度。
关键设计:辅助损失预测器采用一个简单的神经网络结构,输入为ViT编码后的patch特征,输出为该patch的重建损失预测值。损失函数采用均方误差损失。掩码比例与MAE保持一致,但掩码位置由损失预测器决定,优先掩码预测损失高的区域。
🖼️ 关键图片
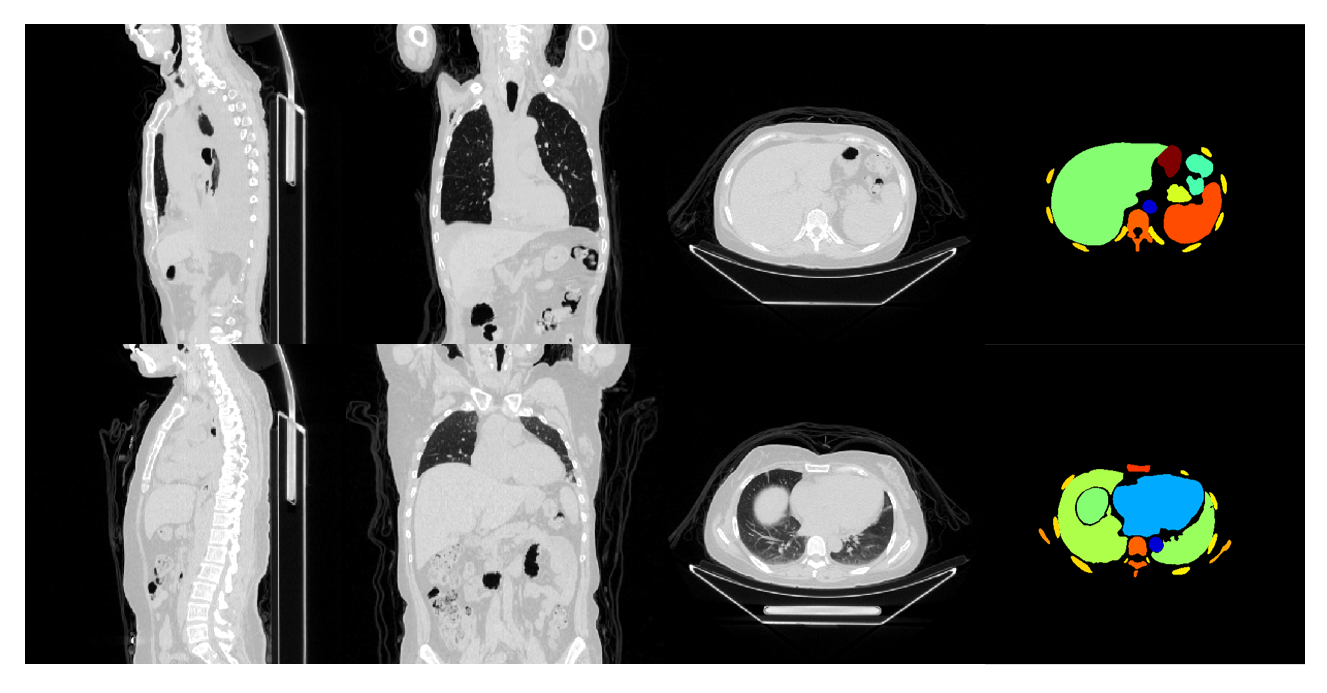

📊 实验亮点
SelfMedHPM在BTCV和SMWB数据集上进行了验证,实验结果表明,该方法在腹部和全身CT多器官分割任务中均优于现有方法。具体性能提升数据未知,但摘要中明确指出优于“各种具有竞争力的算法”。
🎯 应用场景
SelfMedHPM在医学图像分割领域具有广泛的应用前景,可用于辅助医生进行疾病诊断、治疗计划制定和手术导航。通过提高CT多器官分割的精度,可以更准确地识别病灶,评估疾病进展,并为患者提供更个性化的治疗方案。该方法还可推广到其他医学影像模态和分割任务中。
📄 摘要(原文)
In recent years, deep learning methods such as convolutional neural network (CNN) and transformers have made significant progress in CT multi-organ segmentation. However, CT multi-organ segmentation methods based on masked image modeling (MIM) are very limited. There are already methods using MAE for CT multi-organ segmentation task, we believe that the existing methods do not identify the most difficult areas to reconstruct. To this end, we propose a MIM self-training framework with hard patches mining masked autoencoders for CT multi-organ segmentation tasks (selfMedHPM). The method performs ViT self-pretraining on the training set of the target data and introduces an auxiliary loss predictor, which first predicts the patch loss and determines the location of the next mask. SelfMedHPM implementation is better than various competitive methods in abdominal CT multi-organ segmentation and body CT multi-organ segmentation. We have validated the performance of our method on the Multi Atlas Labeling Beyond The Cranial Vault (BTCV) dataset for abdomen mult-organ segmentation and the SinoMed Whole Body (SMWB) dataset for body multi-organ segmentation tasks.