Towards Generalizing Temporal Action Segmentation to Unseen Views
作者: Emad Bahrami, Olga Zatsarynna, Gianpiero Francesca, Juergen Gall
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-04-03
💡 一句话要点
提出一种时序动作分割方法,提升模型在未见视角下的泛化能力
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 时序动作分割 视角泛化 共享表示 序列损失 动作损失
📋 核心要点
- 现有时序动作分割方法难以泛化到未见过的视角,限制了其在实际场景中的应用。
- 该方法通过学习序列和动作的共享表示,减小视角差异带来的影响,提升泛化能力。
- 实验结果表明,该方法在多个数据集上显著提升了未见视角下的时序动作分割性能。
📝 摘要(中文)
本文针对时序动作分割任务中模型在未见视角下的泛化性问题,提出了一个新协议,即在模型评估时使用的相机视角在训练阶段是不可见的。这包括从顶部正面视角到侧视角的转变,甚至更具挑战性的从外部视角到自我中心视角的转变。此外,本文还提出了一种时序动作分割方法来应对这一挑战。该方法利用序列和片段级别的共享表示,以减少训练期间视角差异的影响。通过引入序列损失和动作损失,共同促进不同视角下视频和动作表示的一致性。在Assembly101、IkeaASM和EgoExoLearn数据集上的评估表明,该方法取得了显著的改进,在未见外部视角下的F1@50指标提升了12.8%,在未见自我中心视角下的F1@50指标提升了54%。
🔬 方法详解
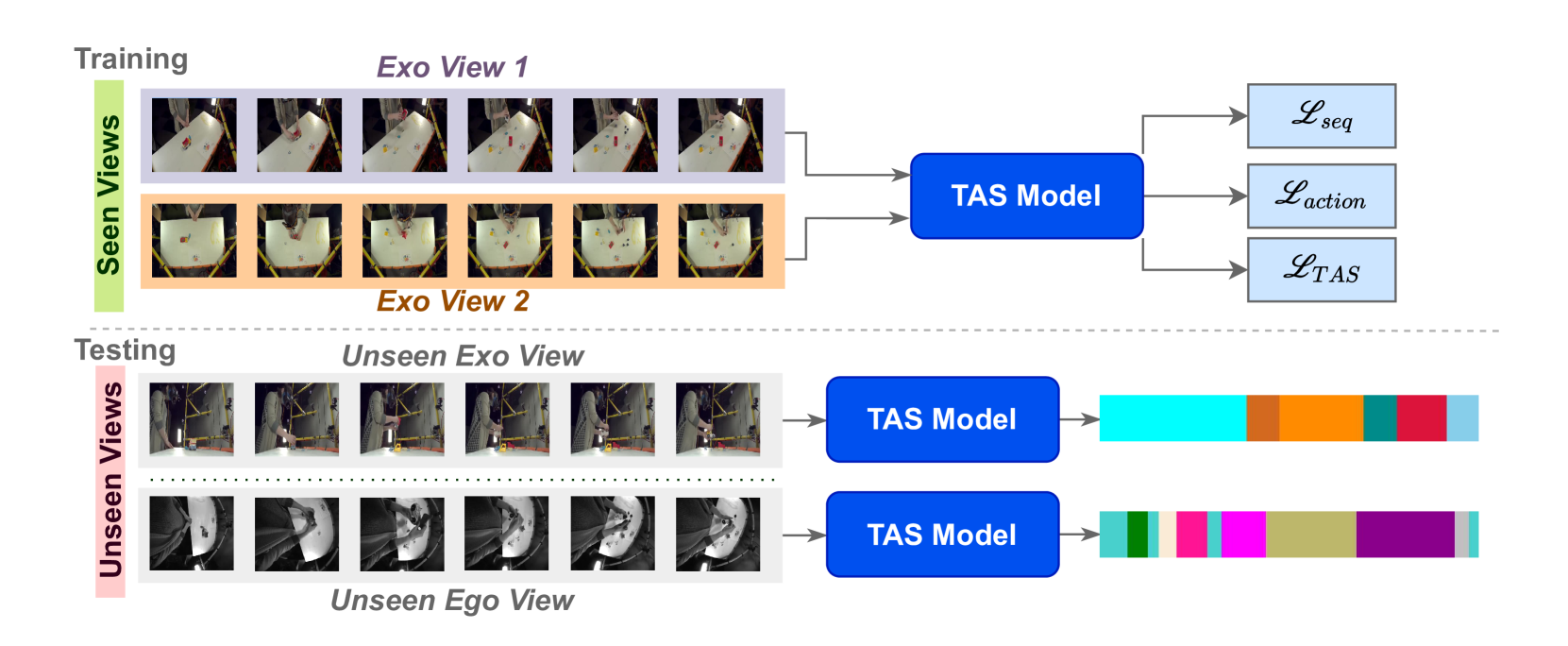
问题定义:现有的时序动作分割方法在训练和测试时通常使用相同的视角,导致模型对特定视角产生过拟合,难以泛化到未见过的视角。这限制了模型在实际应用中的可用性,因为真实场景中视角变化是不可避免的。因此,论文旨在解决时序动作分割模型在未见视角下的泛化性问题。
核心思路:论文的核心思路是学习一种视角不变的视频和动作表示。通过在序列和片段级别上强制模型学习共享表示,从而减少视角差异对模型性能的影响。具体来说,模型需要学习在不同视角下,相同动作的表示尽可能相似,从而提高泛化能力。
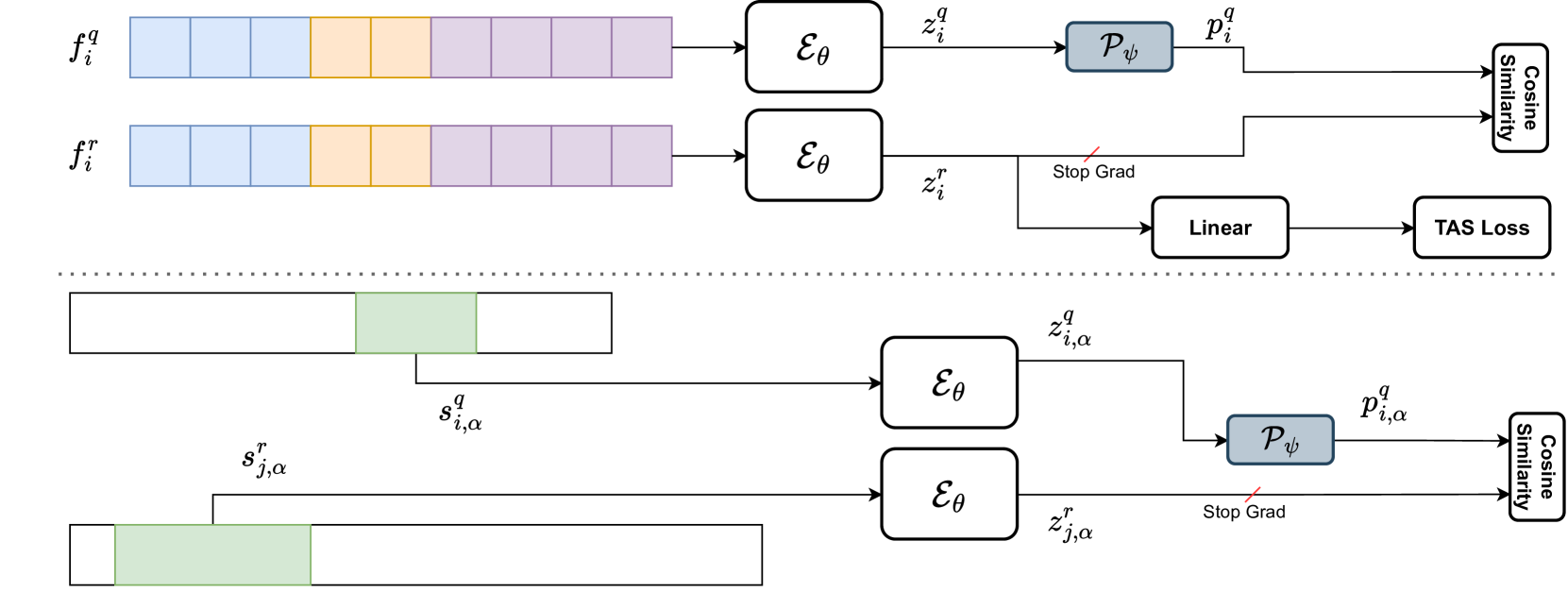
技术框架:该方法包含一个时序动作分割模型,并在此基础上引入了序列损失和动作损失。整体流程如下:首先,输入视频序列经过特征提取器得到视频特征。然后,将视频特征输入到时序动作分割模型中,得到动作类别的预测。同时,利用序列损失和动作损失来约束模型的学习过程,使得模型学习到视角不变的表示。
关键创新:该方法最重要的创新点在于引入了序列损失和动作损失,从而显式地约束模型学习视角不变的表示。序列损失旨在保证同一视频在不同视角下的表示尽可能相似,而动作损失旨在保证同一动作类别在不同视角下的表示尽可能相似。这种显式的约束方式能够有效地提高模型在未见视角下的泛化能力。
关键设计:序列损失采用余弦相似度损失,用于衡量同一视频在不同视角下的表示的相似程度。动作损失采用交叉熵损失,用于衡量同一动作类别在不同视角下的预测结果的相似程度。此外,模型还使用了注意力机制来关注视频序列中与动作相关的关键帧,从而提高动作分割的准确性。
🖼️ 关键图片

📊 实验亮点
该方法在Assembly101、IkeaASM和EgoExoLearn数据集上进行了评估,结果表明该方法在未见视角下的时序动作分割性能得到了显著提升。具体来说,在未见外部视角下的F1@50指标提升了12.8%,在未见自我中心视角下的F1@50指标提升了54%。这些结果表明该方法能够有效地提高模型在未见视角下的泛化能力。
🎯 应用场景
该研究成果可应用于机器人辅助、智能监控、自动驾驶等领域。例如,在机器人辅助任务中,机器人可以从不同的视角观察人类的行为,并进行准确的动作分割,从而更好地理解人类的意图并提供帮助。在智能监控中,可以对不同摄像头拍摄的视频进行分析,识别异常行为。在自动驾驶中,可以分析行人的动作,预测其行为意图,提高驾驶安全性。
📄 摘要(原文)
While there has been substantial progress in temporal action segmentation, the challenge to generalize to unseen views remains unaddressed. Hence, we define a protocol for unseen view action segmentation where camera views for evaluating the model are unavailable during training. This includes changing from top-frontal views to a side view or even more challenging from exocentric to egocentric views. Furthermore, we present an approach for temporal action segmentation that tackles this challenge. Our approach leverages a shared representation at both the sequence and segment levels to reduce the impact of view differences during training. We achieve this by introducing a sequence loss and an action loss, which together facilitate consistent video and action representations across different views. The evaluation on the Assembly101, IkeaASM, and EgoExoLearn datasets demonstrate significant improvements, with a 12.8% increase in F1@50 for unseen exocentric views and a substantial 54% improvement for unseen egocentric views.