MG-MotionLLM: A Unified Framework for Motion Comprehension and Generation across Multiple Granularities
作者: Bizhu Wu, Jinheng Xie, Keming Shen, Zhe Kong, Jianfeng Ren, Ruibin Bai, Rong Qu, Linlin Shen
分类: cs.CV
发布日期: 2025-04-03
💡 一句话要点
提出MG-MotionLLM,用于多粒度运动理解与生成,解决现有方法在细粒度运动任务上的局限性。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 运动理解 运动生成 多粒度学习 大型语言模型 运动-文本建模
📋 核心要点
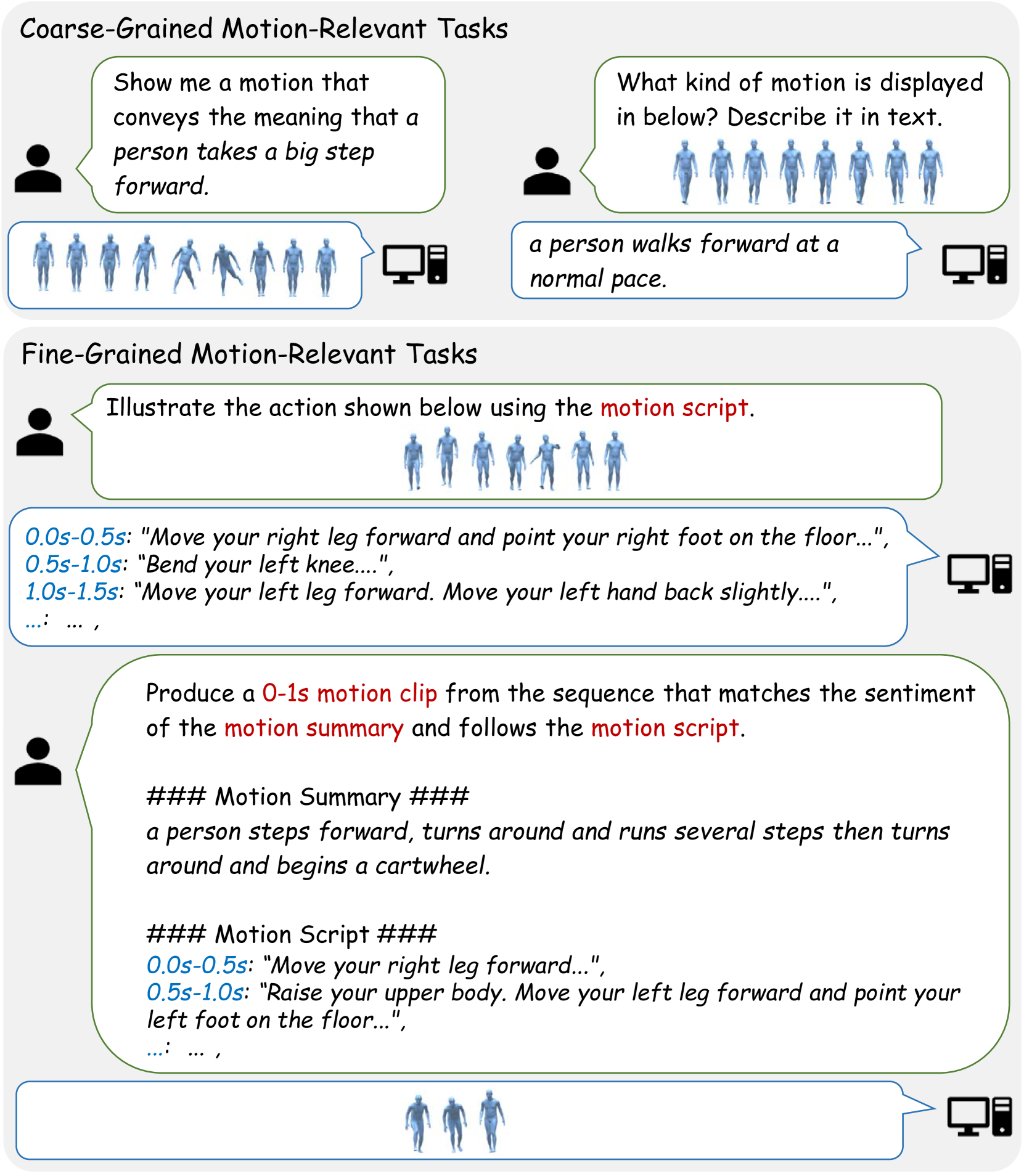
- 现有运动感知大语言模型主要关注粗粒度运动-文本建模,无法处理细粒度的运动理解和控制任务。
- MG-MotionLLM通过统一的框架实现多粒度运动理解和生成,提升模型对运动细节的感知能力。
- 引入多粒度训练方案,包含时间边界定位和运动细节描述等辅助任务,促进不同粒度间的相互增强。
📝 摘要(中文)
本文提出了MG-MotionLLM,一个统一的运动-语言模型,用于多粒度运动理解和生成。现有基于运动的大型语言模型主要集中在粗粒度的运动-文本建模上,文本仅用几个词描述整个运动序列的整体语义,这限制了它们处理细粒度运动相关任务的能力,例如理解和控制特定身体部位的运动。为了克服这个限制,我们引入了MG-MotionLLM。此外,我们通过整合一系列新的辅助任务,例如通过详细文本定位运动片段的时间边界以及运动详细描述,引入了一个全面的多粒度训练方案,以促进跨各种粒度级别的运动-文本建模的相互增强。大量实验表明,我们的MG-MotionLLM在经典的文本到运动和运动到文本任务上取得了优异的性能,并在新的细粒度运动理解和编辑任务中展现了潜力。
🔬 方法详解
问题定义:现有运动感知大语言模型主要关注粗粒度的运动-文本建模,即用简短的文本描述整个运动序列。这种方法无法处理需要理解和控制特定身体部位运动的细粒度任务,例如,无法根据文本指令精确地编辑手臂的运动轨迹。因此,需要一个能够理解和生成多粒度运动信息的模型,以支持更复杂的运动相关任务。
核心思路:MG-MotionLLM的核心思路是构建一个统一的运动-语言模型,使其能够同时处理粗粒度和细粒度的运动信息。通过引入多粒度训练方案,模型可以学习到不同粒度级别运动-文本之间的对应关系,从而提升其在各种运动相关任务上的性能。这种设计允许模型在理解整体运动语义的同时,也能关注到运动的细节部分。
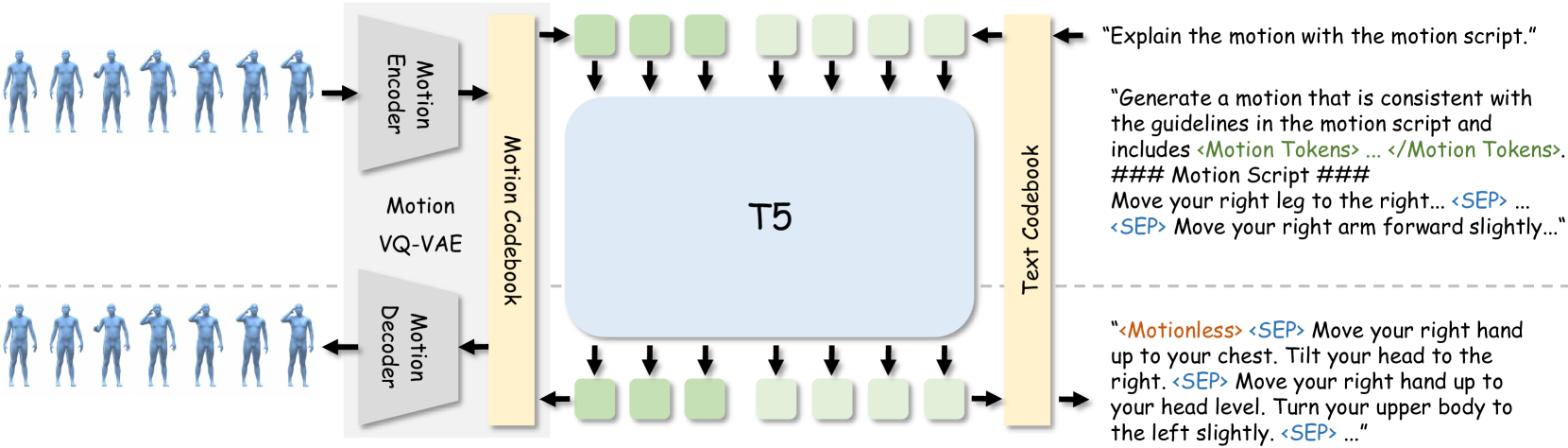
技术框架:MG-MotionLLM的整体框架包含运动编码器、文本编码器和一个大型语言模型(LLM)。运动编码器将运动序列转换为特征表示,文本编码器将文本描述转换为特征表示。然后,LLM将运动和文本的特征表示作为输入,进行运动理解和生成。多粒度训练方案包含多个辅助任务,例如,通过详细文本定位运动片段的时间边界,以及生成运动的详细描述。这些辅助任务可以帮助模型学习到不同粒度级别运动-文本之间的对应关系。
关键创新:MG-MotionLLM的关键创新在于其多粒度训练方案。该方案通过引入一系列新的辅助任务,例如时间边界定位和运动细节描述,使得模型能够学习到不同粒度级别运动-文本之间的对应关系。这与现有方法仅关注粗粒度运动-文本建模形成了鲜明对比。通过这种多粒度训练,MG-MotionLLM能够更好地理解和生成运动信息,从而在各种运动相关任务上取得更好的性能。
关键设计:在多粒度训练方案中,时间边界定位任务使用交叉熵损失函数来训练模型预测运动片段的时间边界。运动细节描述任务使用文本生成损失函数来训练模型生成运动的详细描述。此外,模型还使用了对比学习损失函数来增强运动和文本特征表示之间的对齐。具体的网络结构细节和参数设置在论文中有详细描述,但摘要中未提供具体数值。
🖼️ 关键图片

📊 实验亮点
MG-MotionLLM在经典的文本到运动和运动到文本任务上取得了优异的性能,并且在新的细粒度运动理解和编辑任务中展现了潜力。具体性能数据和对比基线需要在论文中查找,摘要中未提供。
🎯 应用场景
MG-MotionLLM具有广泛的应用前景,例如在虚拟现实、游戏开发、机器人控制等领域。它可以用于生成逼真的角色动画,实现自然的人机交互,以及控制机器人执行复杂的运动任务。该研究的未来影响在于推动运动智能的发展,使得机器能够更好地理解和生成运动信息。
📄 摘要(原文)
Recent motion-aware large language models have demonstrated promising potential in unifying motion comprehension and generation. However, existing approaches primarily focus on coarse-grained motion-text modeling, where text describes the overall semantics of an entire motion sequence in just a few words. This limits their ability to handle fine-grained motion-relevant tasks, such as understanding and controlling the movements of specific body parts. To overcome this limitation, we pioneer MG-MotionLLM, a unified motion-language model for multi-granular motion comprehension and generation. We further introduce a comprehensive multi-granularity training scheme by incorporating a set of novel auxiliary tasks, such as localizing temporal boundaries of motion segments via detailed text as well as motion detailed captioning, to facilitate mutual reinforcement for motion-text modeling across various levels of granularity. Extensive experiments show that our MG-MotionLLM achieves superior performance on classical text-to-motion and motion-to-text tasks, and exhibits potential in novel fine-grained motion comprehension and editing tasks. Project page: CVI-SZU/MG-MotionLLM