Agglomerating Large Vision Encoders via Distillation for VFSS Segmentation
作者: Chengxi Zeng, Yuxuan Jiang, Fan Zhang, Alberto Gambaruto, Tilo Burghardt
分类: cs.CV, cs.AI
发布日期: 2025-04-03
期刊: IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR) 2025, 2nd Efficient Large Vision Models Workshop
💡 一句话要点
提出基于知识蒸馏的视觉编码器聚合方法,用于提升医学图像分割性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学图像分割 知识蒸馏 模型压缩 视觉编码器 基础模型
📋 核心要点
- 医学图像分割依赖大型视觉编码器,但其训练和推理成本高昂,轻量级模型性能受限。
- 提出一种知识蒸馏框架,将多个医学基础模型的知识聚合到低复杂度模型中。
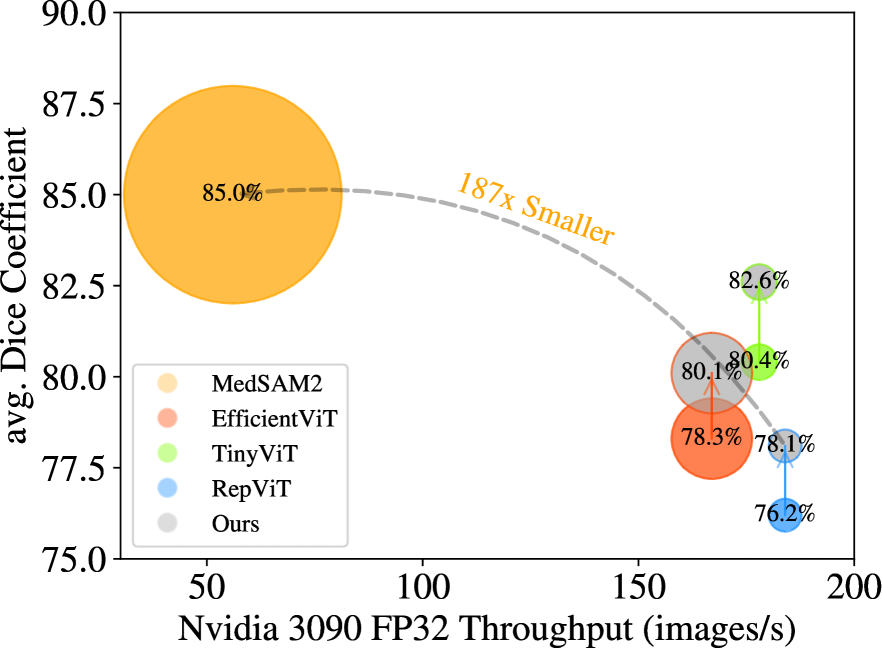
- 实验表明,该方法在多个分割任务上具有更好的泛化能力,Dice系数平均提升2%。
📝 摘要(中文)
医学影像领域的基础模型已经取得了显著的成功。然而,由于所使用的图像编码器尺寸庞大,其下游任务的训练开销仍然很大,并且推理复杂度也显著偏高。虽然已经获得了这些基础模型的轻量级变体,但它们的性能受到有限的模型容量和次优训练策略的限制。为了在复杂度和性能之间实现更好的权衡,我们提出了一种新的框架,通过从多个大型医学基础模型(例如,MedSAM、RAD-DINO、MedCLIP)进行知识蒸馏来提高低复杂度模型的性能,每个模型都专注于不同的视觉任务,目标是有效弥合医学图像分割任务的性能差距。聚合模型在12个分割任务中表现出卓越的泛化能力,而专用模型需要针对每个任务进行显式训练。与简单的蒸馏相比,我们的方法在Dice系数方面平均提高了2%。
🔬 方法详解
问题定义:医学图像分割任务中,直接使用大型预训练模型(如MedSAM, RAD-DINO, MedCLIP等)虽然效果好,但计算资源消耗巨大,难以部署。而轻量级模型由于模型容量有限,性能往往不如大型模型。因此,如何在保证性能的前提下,降低模型的复杂度,是该论文要解决的核心问题。现有方法通常是直接训练轻量级模型,但效果提升有限。
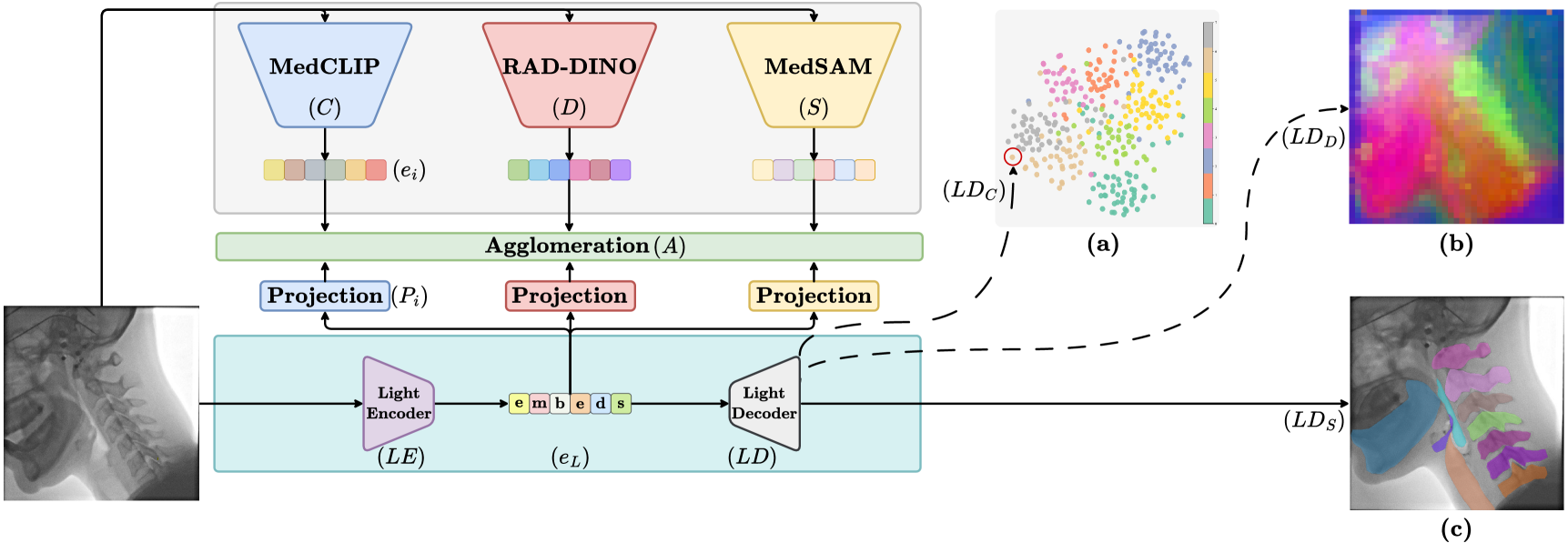
核心思路:该论文的核心思路是通过知识蒸馏,将多个大型医学图像基础模型的知识迁移到一个轻量级模型中。每个大型模型擅长不同的视觉任务,通过聚合它们的知识,可以使轻量级模型获得更强的泛化能力和分割性能。这种方法避免了直接训练轻量级模型带来的性能瓶颈。
技术框架:该框架包含以下主要步骤:1) 选择多个预训练好的大型医学图像基础模型作为教师模型。2) 设计一个轻量级的学生模型。3) 使用知识蒸馏技术,将教师模型的知识迁移到学生模型中。具体而言,学生模型学习模仿教师模型的输出(例如,分割结果的概率分布)。4) 在多个医学图像分割数据集上评估学生模型的性能。
关键创新:该论文的关键创新在于:1) 提出了一种聚合多个大型医学图像基础模型知识的方法,而不是仅仅依赖于单个教师模型。2) 证明了这种聚合方法可以显著提高轻量级模型的泛化能力和分割性能。3) 将该方法应用于医学图像分割领域,并取得了显著的成果。
关键设计:具体的知识蒸馏过程可能涉及多种损失函数,例如,KL散度损失用于衡量学生模型和教师模型输出概率分布的差异。此外,还可以使用特征匹配损失,使学生模型学习模仿教师模型中间层的特征表示。学生模型的网络结构可以根据具体的任务和资源限制进行选择,例如,可以使用轻量级的卷积神经网络或Transformer模型。具体的参数设置(例如,学习率、batch size等)需要根据实验结果进行调整。
🖼️ 关键图片
📊 实验亮点
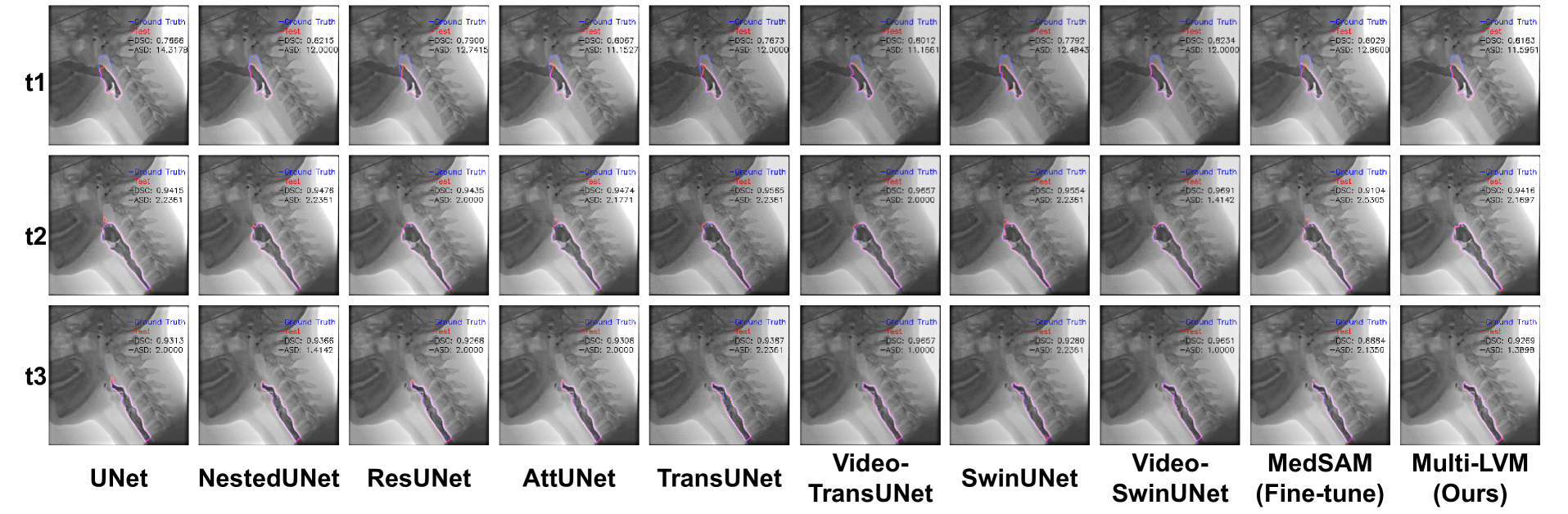
实验结果表明,该方法在12个医学图像分割任务上取得了显著的性能提升,平均Dice系数提高了2%,优于简单的知识蒸馏方法。这表明该方法能够有效地聚合多个大型模型的知识,并将其迁移到轻量级模型中,从而提高模型的泛化能力和分割性能。该方法在降低模型复杂度的同时,保证了较高的分割精度。
🎯 应用场景
该研究成果可广泛应用于医学图像分析领域,例如辅助医生进行疾病诊断、手术规划和疗效评估。通过降低模型复杂度和提高分割精度,可以加速医学影像分析流程,提高诊断效率,并降低医疗成本。未来,该方法有望推广到其他医学影像任务,例如病灶检测、器官分割等。
📄 摘要(原文)
The deployment of foundation models for medical imaging has demonstrated considerable success. However, their training overheads associated with downstream tasks remain substantial due to the size of the image encoders employed, and the inference complexity is also significantly high. Although lightweight variants have been obtained for these foundation models, their performance is constrained by their limited model capacity and suboptimal training strategies. In order to achieve an improved tradeoff between complexity and performance, we propose a new framework to improve the performance of low complexity models via knowledge distillation from multiple large medical foundation models (e.g., MedSAM, RAD-DINO, MedCLIP), each specializing in different vision tasks, with the goal to effectively bridge the performance gap for medical image segmentation tasks. The agglomerated model demonstrates superior generalization across 12 segmentation tasks, whereas specialized models require explicit training for each task. Our approach achieved an average performance gain of 2\% in Dice coefficient compared to simple distillation.