LPA3D: 3D Room-Level Scene Generation from In-the-Wild Images
作者: Ming-Jia Yang, Yu-Xiao Guo, Yang Liu, Bin Zhou, Xin Tong
分类: cs.CV
发布日期: 2025-04-03
💡 一句话要点
提出LPA-GAN,从单张图像生成逼真、语义合理的3D室内场景。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D场景生成 NeRF 局部位姿对齐 单视图重建 生成对抗网络
📋 核心要点
- 现有场景级NeRF方法依赖多视角、深度或语义信息,难以仅从单张RGB图像生成室内场景。
- 论文提出基于局部位姿对齐(LPA)的LPA-GAN,通过锚点坐标系估计相机位姿先验。
- 实验表明,LPA-GAN在视角一致性和语义合理性方面优于其他方法,验证了其有效性。
📝 摘要(中文)
本文旨在解决从单张真实图像生成逼真、房间级室内场景的问题,这对于VR、AR和机器人等应用至关重要。基于NeRF的生成方法在该领域展现出潜力。然而,与物体级别的成功不同,现有的场景级生成方法需要额外的输入信息,如多视角、深度图像或语义引导,而不能仅依赖RGB图像。这是因为基于NeRF的方法需要相机位姿的先验知识,而室内场景的相机位姿难以估计,原因在于对齐的复杂性以及从单张图像进行全局位姿估计的困难,尤其是在存在相机不可见区域的情况下。为了解决这个问题,本文重新定义了局部位姿对齐(LPA)框架下的全局位姿,即基于锚点的多局部坐标系,使用选定的锚点作为坐标系的根。在此基础上,本文提出了一种新的基于NeRF的生成方法LPA-GAN,该方法通过特定的修改来估计LPA下的相机位姿先验,并共同优化位姿预测器和场景生成过程。消融实验和与NeRF物体生成方法的比较验证了本文方法的有效性。与其他技术的视觉比较表明,本文方法实现了卓越的视角间一致性和语义合理性。
🔬 方法详解
问题定义:现有基于NeRF的场景生成方法,在室内场景中,需要多视角图像、深度信息或语义信息等辅助,无法仅从单张RGB图像生成高质量的3D场景。主要痛点在于相机位姿的估计,室内场景结构复杂,单张图像难以提供足够的几何信息进行全局位姿估计。
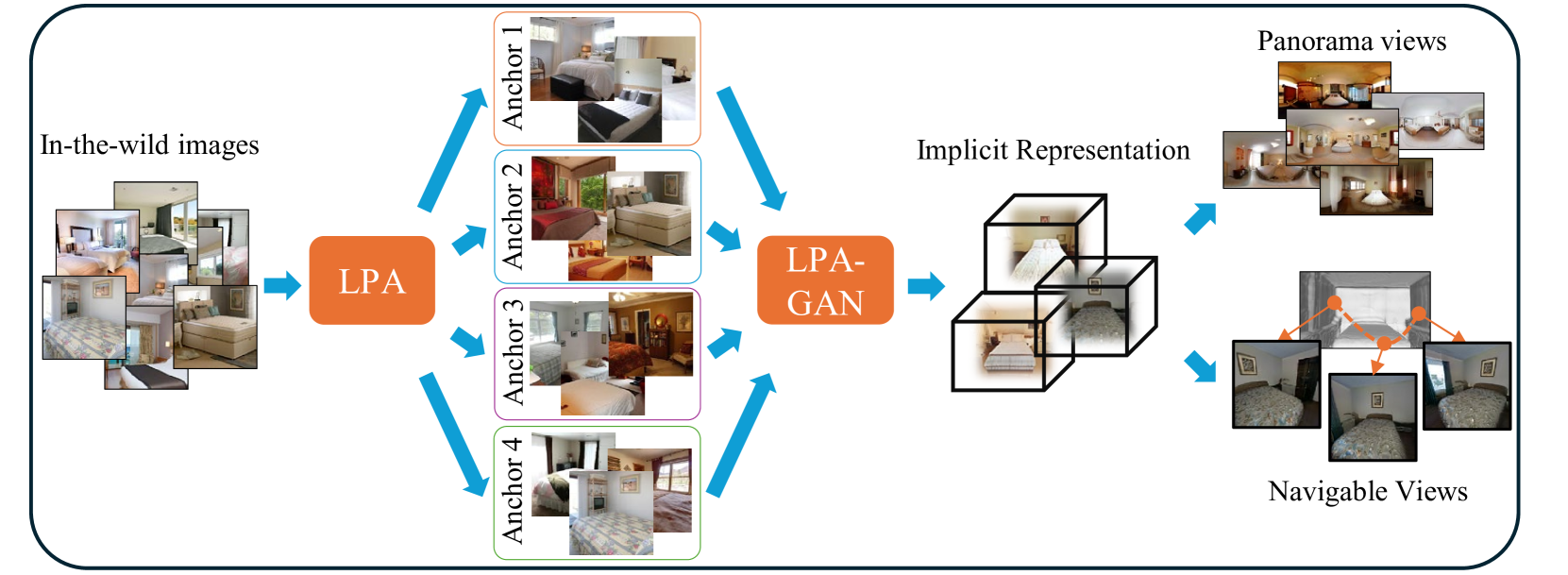
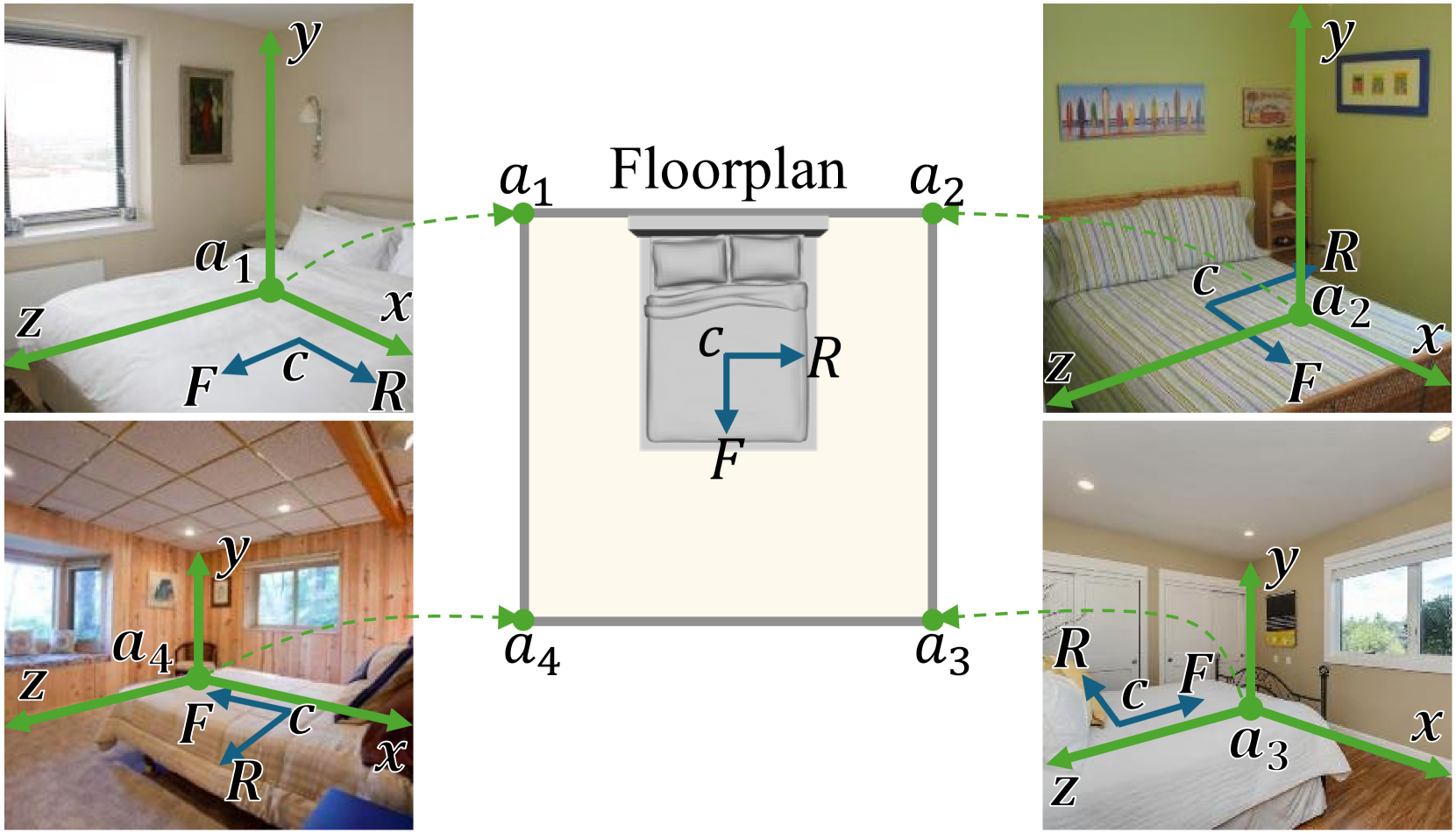
核心思路:论文的核心思路是引入局部位姿对齐(LPA)框架,将全局位姿估计问题分解为多个局部坐标系下的位姿估计。通过选择若干锚点,构建基于锚点的多局部坐标系,从而简化位姿估计的难度。这样,模型只需要预测相对于这些锚点的局部位姿,再通过LPA框架整合为全局场景表示。
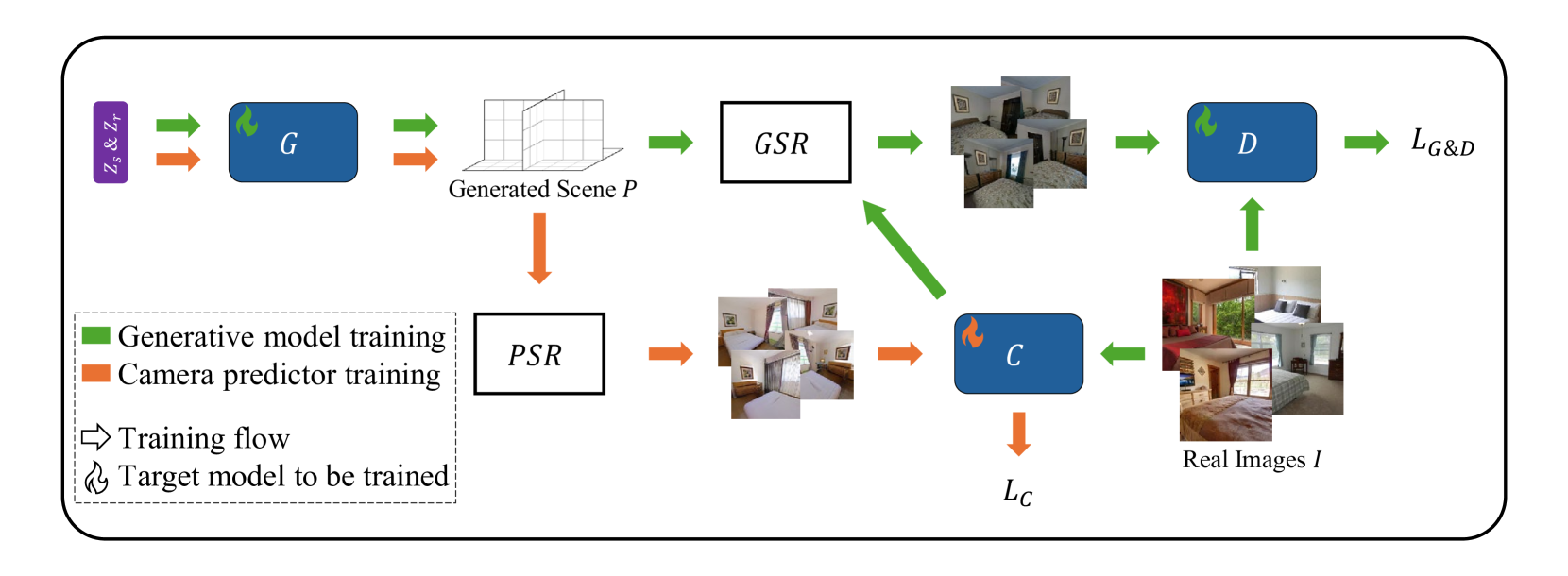
技术框架:LPA-GAN的整体框架包含两个主要模块:位姿预测器和NeRF场景生成器。首先,位姿预测器根据输入图像,预测相机相对于各个锚点的局部位姿。然后,这些局部位姿通过LPA框架转换为全局位姿。最后,NeRF场景生成器利用这些全局位姿,生成3D场景的体渲染图像。整个框架采用对抗训练的方式,共同优化位姿预测器和场景生成器。
关键创新:论文的关键创新在于提出了局部位姿对齐(LPA)框架,将全局位姿估计分解为多个局部坐标系下的位姿估计。这种分解方式降低了位姿估计的难度,使得模型能够仅从单张图像中学习到有效的位姿先验。此外,LPA-GAN通过共同优化位姿预测器和场景生成器,进一步提升了生成场景的质量和一致性。
关键设计:LPA框架的关键设计在于锚点的选择和局部坐标系的构建。论文中锚点的数量和位置是预先设定的,可以根据具体场景进行调整。损失函数方面,除了标准的GAN损失外,还引入了位姿一致性损失,用于约束预测位姿的合理性。网络结构方面,位姿预测器通常采用卷积神经网络,场景生成器则采用标准的NeRF结构。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LPA-GAN在视角一致性和语义合理性方面显著优于其他基于NeRF的场景生成方法。通过与直接扩展的NeRF物体生成方法进行比较,LPA-GAN能够生成更逼真、更连贯的室内场景。消融实验验证了LPA框架和共同优化策略的有效性。视觉效果上,LPA-GAN生成的场景在不同视角下保持了高度的一致性,并且场景中的物体摆放符合常理。
🎯 应用场景
该研究成果可广泛应用于虚拟现实(VR)、增强现实(AR)和机器人等领域。例如,可以根据用户上传的室内照片,快速生成逼真的3D场景,用于VR游戏或AR导航。此外,该技术还可以用于机器人场景理解,帮助机器人更好地理解和导航室内环境。未来,该技术有望进一步发展,实现更精细、更真实的3D场景生成。
📄 摘要(原文)
Generating realistic, room-level indoor scenes with semantically plausible and detailed appearances from in-the-wild images is crucial for various applications in VR, AR, and robotics. The success of NeRF-based generative methods indicates a promising direction to address this challenge. However, unlike their success at the object level, existing scene-level generative methods require additional information, such as multiple views, depth images, or semantic guidance, rather than relying solely on RGB images. This is because NeRF-based methods necessitate prior knowledge of camera poses, which is challenging to approximate for indoor scenes due to the complexity of defining alignment and the difficulty of globally estimating poses from a single image, given the unseen parts behind the camera. To address this challenge, we redefine global poses within the framework of Local-Pose-Alignment (LPA) -- an anchor-based multi-local-coordinate system that uses a selected number of anchors as the roots of these coordinates. Building on this foundation, we introduce LPA-GAN, a novel NeRF-based generative approach that incorporates specific modifications to estimate the priors of camera poses under LPA. It also co-optimizes the pose predictor and scene generation processes. Our ablation study and comparisons with straightforward extensions of NeRF-based object generative methods demonstrate the effectiveness of our approach. Furthermore, visual comparisons with other techniques reveal that our method achieves superior view-to-view consistency and semantic normality.