Refining CLIP's Spatial Awareness: A Visual-Centric Perspective
作者: Congpei Qiu, Yanhao Wu, Wei Ke, Xiuxiu Bai, Tong Zhang
分类: cs.CV
发布日期: 2025-04-03
备注: ICLR 2025
💡 一句话要点
提出空间相关性蒸馏框架,提升CLIP在密集预测任务中的空间感知能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: CLIP 空间感知 密集预测 知识蒸馏 视觉-语言模型 空间相关性 开放词汇 图像分割
📋 核心要点
- 现有方法通过区域-语言对齐(RLA)微调CLIP,但在密集预测任务中损失了空间感知能力。
- 论文提出空间相关性蒸馏(SCD)框架,旨在保留CLIP固有的空间结构,缓解空间感知能力的退化。
- 实验结果表明,该方法在各种开放词汇密集预测基准上取得了最先进的性能。
📝 摘要(中文)
对比语言-图像预训练(CLIP)在全局语言对齐方面表现出色,但在空间信息敏感性方面存在局限,导致其在零样本分类任务中表现出色,但在需要精确空间理解的任务中表现不佳。最近的方法引入了区域-语言对齐(RLA)来增强CLIP在密集多模态任务中的性能,通过将区域视觉表示与相应的文本输入对齐。然而,我们发现使用RLA微调的CLIP ViT在空间感知方面存在显著损失,这对于密集预测任务至关重要。为了解决这个问题,我们提出了空间相关性蒸馏(SCD)框架,该框架保留了CLIP固有的空间结构,并减轻了上述退化。为了进一步增强空间相关性,我们引入了一个轻量级的Refiner,它直接从CLIP中提取精细的相关性,然后将其输入到SCD中,这是基于一个有趣的发现,即CLIP自然地捕获高质量的密集特征。这些组件共同构成了一个强大的蒸馏框架,使CLIP ViT能够整合视觉-语言和以视觉为中心的改进,从而在各种开放词汇密集预测基准上实现最先进的结果。
🔬 方法详解
问题定义:CLIP虽然在全局视觉-语言对齐上表现出色,但在需要精细空间理解的密集预测任务中表现不佳。使用区域-语言对齐(RLA)微调CLIP ViT虽然可以提升性能,但会显著降低其空间感知能力,这对于密集预测任务至关重要。因此,如何提升CLIP在密集预测任务中的空间感知能力,同时避免微调过程中的空间信息损失,是本文要解决的核心问题。
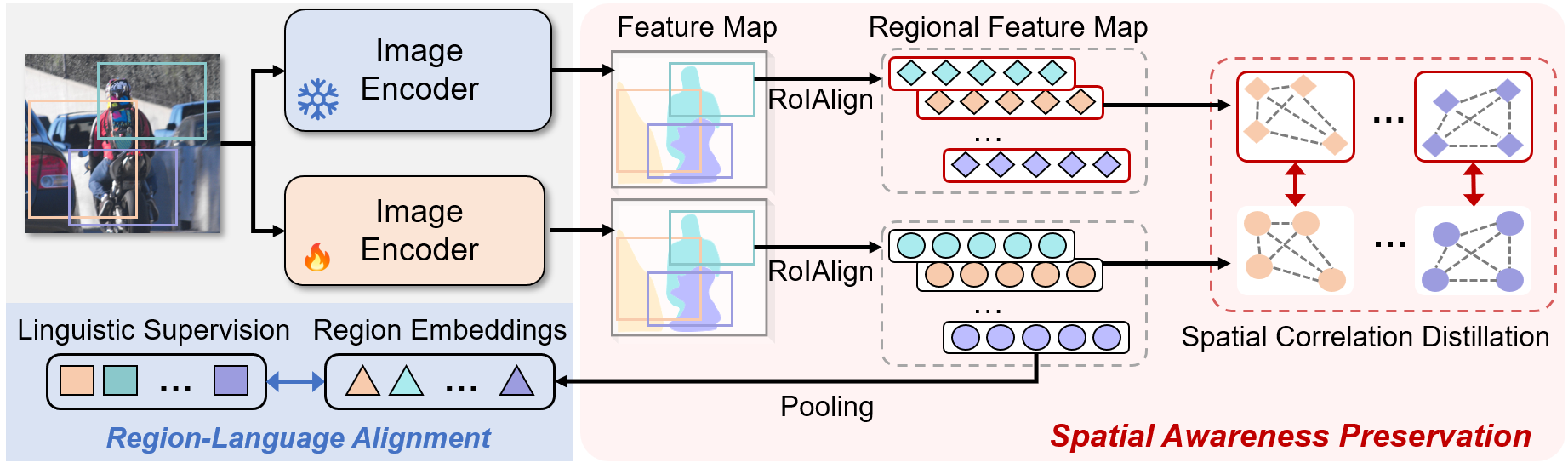
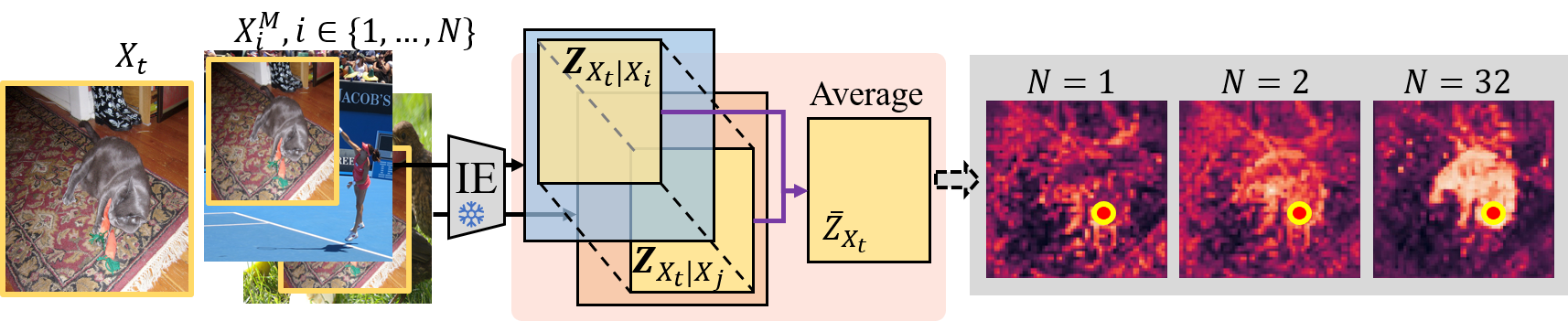
核心思路:论文的核心思路是通过空间相关性蒸馏(SCD)来保留CLIP预训练模型中固有的空间结构。SCD框架利用CLIP模型本身已经具备的优秀密集特征,通过蒸馏的方式将这些特征的空间相关性传递给微调后的模型,从而避免或减轻空间感知能力的退化。此外,还引入了一个轻量级的Refiner模块,进一步增强空间相关性。
技术框架:整体框架包含两个主要部分:空间相关性蒸馏(SCD)和Refiner模块。首先,Refiner模块从CLIP模型中提取精细的空间相关性特征。然后,SCD框架利用这些特征,通过蒸馏的方式,指导微调后的CLIP模型学习原始CLIP模型的空间结构。整个框架可以看作是一个知识蒸馏的过程,其中预训练的CLIP模型是教师模型,微调后的CLIP模型是学生模型。
关键创新:论文的关键创新在于提出了空间相关性蒸馏(SCD)框架,该框架能够有效地保留CLIP预训练模型中固有的空间结构,避免了微调过程中的空间信息损失。此外,Refiner模块的引入进一步增强了空间相关性,提升了模型的性能。与现有方法相比,SCD框架更加注重保留原始模型的空间信息,而不是简单地进行区域-语言对齐。
关键设计:Refiner模块是一个轻量级的网络,用于提取CLIP模型中的空间相关性特征。SCD框架使用KL散度作为蒸馏损失函数,用于衡量学生模型和教师模型在空间相关性上的差异。具体的网络结构和参数设置在论文中有详细描述。损失函数的设计目标是最小化学生模型和教师模型在空间相关性上的差异,从而使学生模型能够学习到教师模型的空间结构。
🖼️ 关键图片

📊 实验亮点
论文在多个开放词汇密集预测基准上取得了最先进的结果,证明了所提出方法的有效性。具体的性能数据和对比基线在论文中有详细展示,表明SCD框架能够显著提升CLIP模型在密集预测任务中的性能,并且优于现有的区域-语言对齐方法。实验结果还验证了Refiner模块的有效性,表明其能够进一步增强空间相关性。
🎯 应用场景
该研究成果可广泛应用于需要精细空间理解的视觉任务,例如:图像分割、目标检测、场景理解、视觉定位等。在自动驾驶、机器人导航、医学图像分析等领域具有重要的应用价值。通过提升模型对空间信息的感知能力,可以提高相关应用系统的准确性和鲁棒性,从而更好地服务于实际场景。
📄 摘要(原文)
Contrastive Language-Image Pre-training (CLIP) excels in global alignment with language but exhibits limited sensitivity to spatial information, leading to strong performance in zero-shot classification tasks but underperformance in tasks requiring precise spatial understanding. Recent approaches have introduced Region-Language Alignment (RLA) to enhance CLIP's performance in dense multimodal tasks by aligning regional visual representations with corresponding text inputs. However, we find that CLIP ViTs fine-tuned with RLA suffer from notable loss in spatial awareness, which is crucial for dense prediction tasks. To address this, we propose the Spatial Correlation Distillation (SCD) framework, which preserves CLIP's inherent spatial structure and mitigates the above degradation. To further enhance spatial correlations, we introduce a lightweight Refiner that extracts refined correlations directly from CLIP before feeding them into SCD, based on an intriguing finding that CLIP naturally captures high-quality dense features. Together, these components form a robust distillation framework that enables CLIP ViTs to integrate both visual-language and visual-centric improvements, achieving state-of-the-art results across various open-vocabulary dense prediction benchmarks.