ConsDreamer: Advancing Multi-View Consistency for Zero-Shot Text-to-3D Generation
作者: Yuan Zhou, Shilong Jin, Litao Hua, Wanjun Lv, Haoran Duan, Jungong Han
分类: cs.CV, cs.AI
发布日期: 2025-04-03 (更新: 2025-12-10)
备注: 13 pages, 14 figures, 3 tables
💡 一句话要点
ConsDreamer通过解耦视角偏差和几何一致性,提升零样本文本到3D生成的多视角一致性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱七:动作重定向 (Motion Retargeting)
关键词: 文本到3D生成 零样本学习 多视角一致性 视角解耦 分数蒸馏
📋 核心要点
- 现有零样本文本到3D生成方法受限于预训练T2I模型的视角偏差,导致生成结果在不同视角下不一致,出现“多面Janus”问题。
- ConsDreamer通过视角解耦模块消除条件提示中的视角偏差,并利用相似性偏序损失在无条件项中强制几何一致性,从而缓解视角偏差。
- 实验表明,ConsDreamer可以有效集成到不同的3D表示和分数蒸馏框架中,显著改善多视角一致性问题,减轻“多面Janus”现象。
📝 摘要(中文)
零样本文本到3D生成领域的最新进展通过直接从文本描述合成3D内容,彻底改变了3D内容创作。目前最先进的方法利用3D高斯溅射和分数蒸馏,通过预训练的文本到图像(T2I)模型来增强多视角渲染,但它们受到T2I先验中固有的先验视角偏差的影响。这些偏差导致不一致的3D生成,尤其表现为多面Janus问题,即对象在不同视角下表现出冲突的特征。为了解决这个根本性的挑战,我们提出ConsDreamer,一种通过细化分数蒸馏过程中的条件项和无条件项来减轻视角偏差的新方法:(1)视角解耦模块(VDM),通过解耦不相关的视角分量并注入精确的视角控制,消除条件提示中的视角偏差;(2)基于相似性的偏序损失,通过将余弦相似性与方位角关系对齐,在无条件项中强制执行几何一致性。大量实验表明,ConsDreamer可以无缝集成到各种3D表示和分数蒸馏范式中,有效地缓解多面Janus问题。
🔬 方法详解
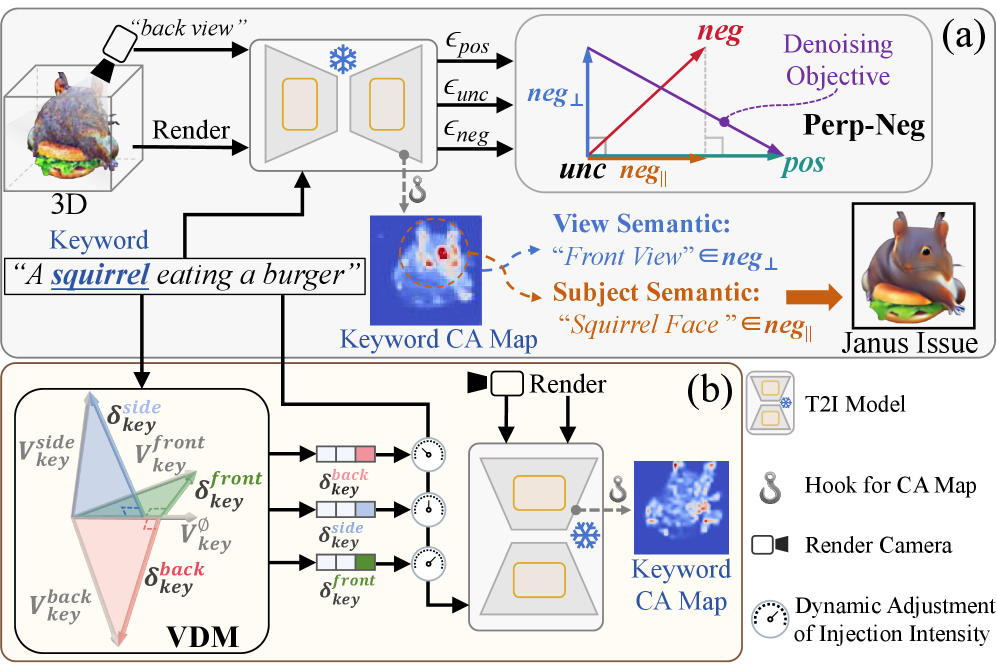
问题定义:论文旨在解决零样本文本到3D生成中,由于预训练文本到图像模型(T2I)的视角偏差导致的3D模型多视角不一致性问题,即“多面Janus”问题。现有方法直接利用T2I模型作为先验,缺乏对视角信息的有效控制,导致生成的3D模型在不同视角下呈现出不一致的特征。
核心思路:ConsDreamer的核心思路是通过解耦视角信息和强制几何一致性来缓解视角偏差。具体来说,它通过视角解耦模块(VDM)消除条件提示中的视角偏差,并利用相似性偏序损失在无条件项中强制执行几何一致性。这样可以确保生成的3D模型在不同视角下保持一致的特征。
技术框架:ConsDreamer可以集成到现有的基于分数蒸馏的文本到3D生成框架中。其主要包含两个核心模块:1) 视角解耦模块(VDM):用于处理条件提示,消除其中的视角偏差,并允许精确的视角控制。2) 相似性偏序损失:用于处理无条件项,通过对齐余弦相似性和方位角关系,强制执行几何一致性。整个流程是,首先使用VDM处理文本提示,然后利用分数蒸馏生成3D模型,并使用相似性偏序损失进行优化。
关键创新:ConsDreamer的关键创新在于:1) 提出了视角解耦模块(VDM),能够有效消除条件提示中的视角偏差,并允许精确的视角控制。2) 提出了相似性偏序损失,通过对齐余弦相似性和方位角关系,强制执行几何一致性。与现有方法相比,ConsDreamer能够更有效地缓解视角偏差,生成多视角一致的3D模型。
关键设计:视角解耦模块(VDM)的具体实现细节未知,但其目标是解耦视角信息并注入精确的视角控制。相似性偏序损失的关键在于如何定义和计算余弦相似性和方位角关系,以及如何设计损失函数来强制对齐它们。具体的参数设置和网络结构细节未知。
🖼️ 关键图片


📊 实验亮点
论文通过实验验证了ConsDreamer在缓解多视角不一致性问题上的有效性。实验结果表明,ConsDreamer能够显著减少“多面Janus”现象,生成更符合文本描述且多视角一致的3D模型。具体的性能数据和对比基线未知,但论文强调ConsDreamer可以无缝集成到各种3D表示和分数蒸馏范式中,具有良好的通用性和可扩展性。
🎯 应用场景
ConsDreamer的研究成果可应用于游戏开发、虚拟现实、增强现实、工业设计等领域,能够帮助用户更高效、更便捷地创建高质量的3D模型。通过文本描述直接生成3D模型,降低了3D内容创作的门槛,使得非专业人士也能参与到3D内容创作中来。未来,该技术有望进一步发展,实现更精细、更逼真的3D模型生成。
📄 摘要(原文)
Recent advances in zero-shot text-to-3D generation have revolutionized 3D content creation by enabling direct synthesis from textual descriptions. While state-of-the-art methods leverage 3D Gaussian Splatting with score distillation to enhance multi-view rendering through pre-trained text-to-image (T2I) models, they suffer from inherent prior view biases in T2I priors. These biases lead to inconsistent 3D generation, particularly manifesting as the multi-face Janus problem, where objects exhibit conflicting features across views. To address this fundamental challenge, we propose ConsDreamer, a novel method that mitigates view bias by refining both the conditional and unconditional terms in the score distillation process: (1) a View Disentanglement Module (VDM) that eliminates viewpoint biases in conditional prompts by decoupling irrelevant view components and injecting precise view control; and (2) a similarity-based partial order loss that enforces geometric consistency in the unconditional term by aligning cosine similarities with azimuth relationships. Extensive experiments demonstrate that ConsDreamer can be seamlessly integrated into various 3D representations and score distillation paradigms, effectively mitigating the multi-face Janus problem.