GMAI-VL-R1: Harnessing Reinforcement Learning for Multimodal Medical Reasoning
作者: Yanzhou Su, Tianbin Li, Jiyao Liu, Chenglong Ma, Junzhi Ning, Cheng Tang, Sibo Ju, Jin Ye, Pengcheng Chen, Ming Hu, Shixiang Tang, Lihao Liu, Bin Fu, Wenqi Shao, Xiaowei Hu, Xiangwen Liao, Yuanfeng Ji, Junjun He
分类: cs.CV
发布日期: 2025-04-02
🔗 代码/项目: GITHUB
💡 一句话要点
GMAI-VL-R1:利用强化学习提升多模态医学推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态医学推理 强化学习 医学图像诊断 视觉问答 推理数据合成 临床决策支持
📋 核心要点
- 现有医学AI模型缺乏复杂医学决策所需的推理能力,限制了其在临床实践中的应用。
- GMAI-VL-R1通过强化学习优化决策过程,并结合推理数据合成方法,提升模型泛化能力。
- 实验结果表明,强化学习训练显著提升了模型在医学图像诊断和视觉问答等任务中的性能。
📝 摘要(中文)
本文提出了GMAI-VL-R1,一个通过强化学习(RL)增强的多模态医学推理模型,旨在提升复杂医学决策所需的推理能力。通过迭代训练,GMAI-VL-R1优化决策过程,显著提高了诊断准确性和临床支持能力。此外,我们还开发了一种推理数据合成方法,通过拒绝采样生成逐步推理数据,进一步增强了模型的泛化能力。实验结果表明,经过RL训练后,GMAI-VL-R1在医学图像诊断和视觉问答等任务中表现出色。虽然监督微调可以使模型具备基本的记忆能力,但RL对于实现真正的泛化至关重要。我们的工作为医学推理模型建立了新的评估基准,并为未来的发展铺平了道路。
🔬 方法详解
问题定义:现有医学AI模型在处理复杂医学问题时,缺乏有效的推理能力,难以进行准确的诊断和决策。仅仅依靠监督学习进行微调的模型,虽然具备一定的记忆能力,但泛化能力不足,无法应对真实场景中复杂多变的医学问题。
核心思路:本文的核心思路是利用强化学习(RL)来训练模型,使其能够通过与环境的交互,学习到更有效的推理策略。通过奖励正确的诊断和惩罚错误的诊断,模型可以逐步优化其决策过程,从而提高诊断准确性和泛化能力。此外,还通过推理数据合成方法,生成逐步推理数据,进一步增强模型的泛化能力。
技术框架:GMAI-VL-R1的整体框架包含多模态输入处理模块、推理模块和强化学习训练模块。多模态输入处理模块负责处理医学图像和文本信息,推理模块负责进行诊断和决策,强化学习训练模块则通过与环境的交互,优化推理模块的参数。具体流程为:首先,模型接收医学图像和文本信息作为输入;然后,推理模块根据输入进行诊断和决策;最后,强化学习训练模块根据诊断结果的正确性,调整推理模块的参数。
关键创新:该论文的关键创新在于将强化学习应用于多模态医学推理任务,并提出了一种推理数据合成方法。与传统的监督学习方法相比,强化学习能够更好地训练模型进行决策,提高诊断准确性和泛化能力。推理数据合成方法则可以生成更多的训练数据,进一步增强模型的泛化能力。
关键设计:在强化学习训练中,使用了奖励函数来评估模型的诊断结果。奖励函数的设计至关重要,需要能够准确地反映诊断结果的正确性。此外,还使用了拒绝采样方法来生成推理数据,以保证数据的质量和多样性。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片

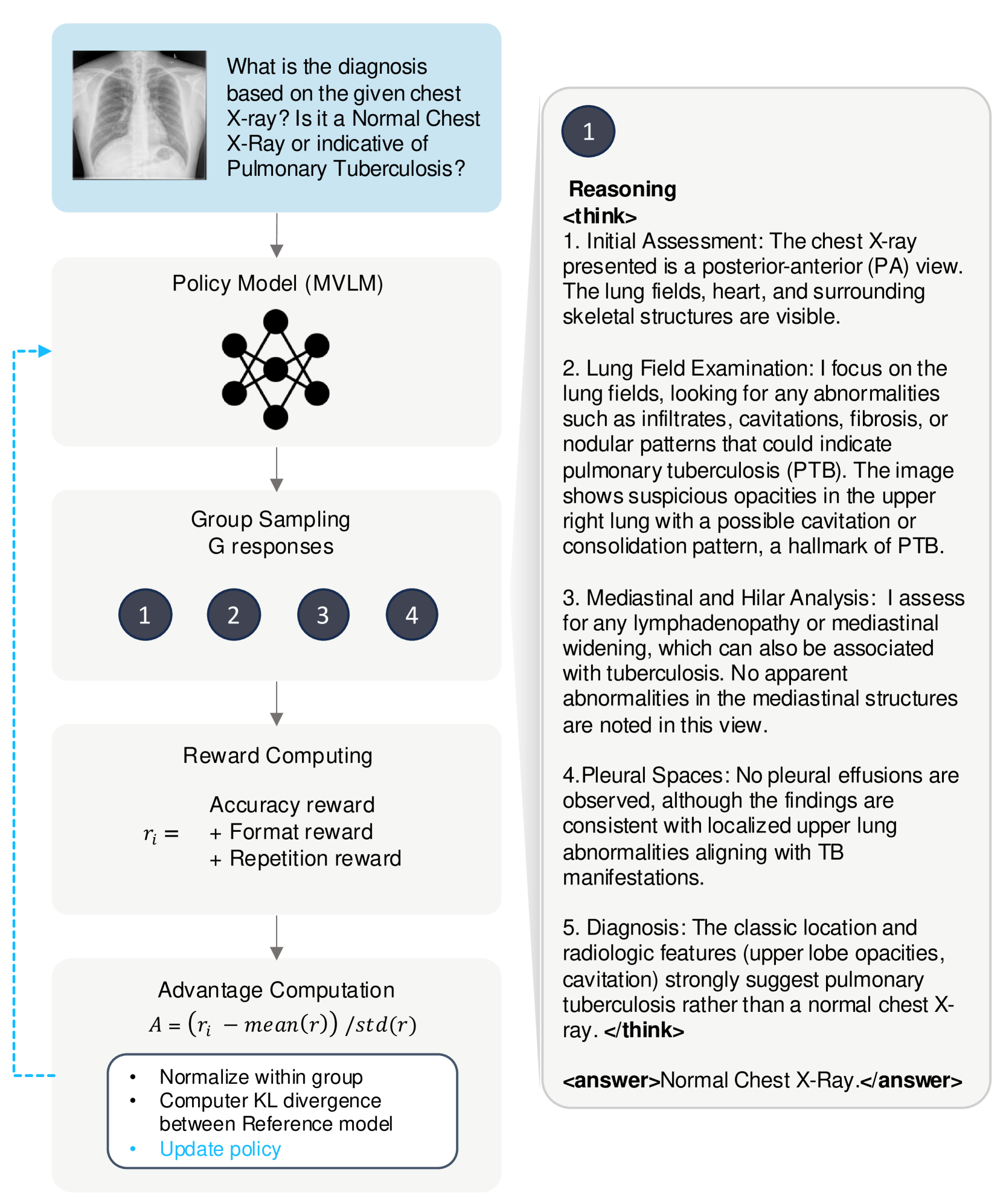
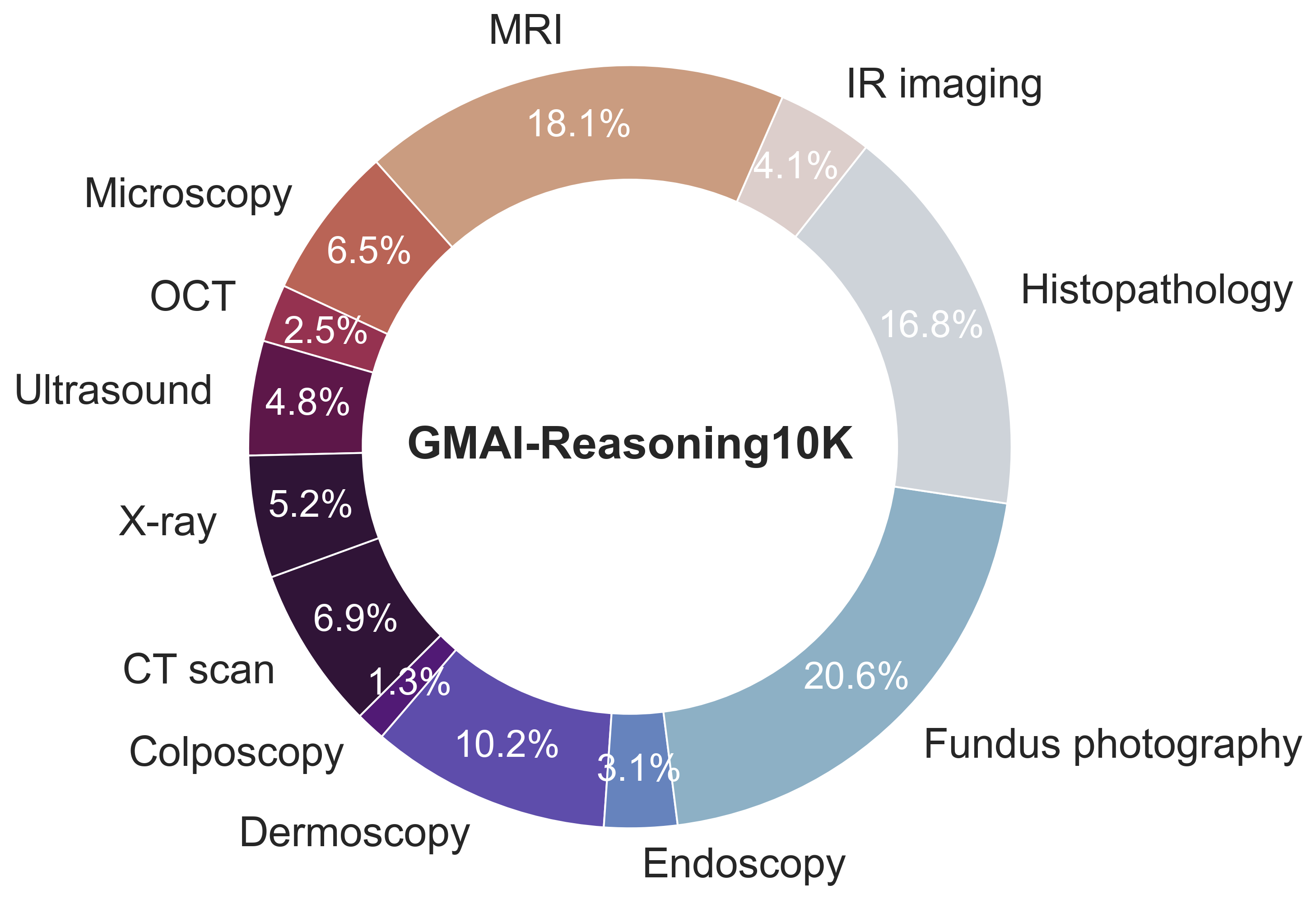
📊 实验亮点
实验结果表明,经过强化学习训练后,GMAI-VL-R1在医学图像诊断和视觉问答等任务中表现出色,显著提高了诊断准确性和临床支持能力。与传统的监督学习方法相比,强化学习能够更好地训练模型进行决策,提高诊断准确性和泛化能力。具体性能数据和对比基线在论文中有详细展示。
🎯 应用场景
GMAI-VL-R1具有广泛的应用前景,可用于辅助医生进行疾病诊断、制定治疗方案和提供临床决策支持。该模型可以处理多种模态的医学数据,包括图像、文本等,能够更全面地了解患者的病情。未来,该模型有望应用于远程医疗、智能健康管理等领域,提高医疗服务的效率和质量。
📄 摘要(原文)
Recent advances in general medical AI have made significant strides, but existing models often lack the reasoning capabilities needed for complex medical decision-making. This paper presents GMAI-VL-R1, a multimodal medical reasoning model enhanced by reinforcement learning (RL) to improve its reasoning abilities. Through iterative training, GMAI-VL-R1 optimizes decision-making, significantly boosting diagnostic accuracy and clinical support. We also develop a reasoning data synthesis method, generating step-by-step reasoning data via rejection sampling, which further enhances the model's generalization. Experimental results show that after RL training, GMAI-VL-R1 excels in tasks such as medical image diagnosis and visual question answering. While the model demonstrates basic memorization with supervised fine-tuning, RL is crucial for true generalization. Our work establishes new evaluation benchmarks and paves the way for future advancements in medical reasoning models. Code, data, and model will be released at \href{https://github.com/uni-medical/GMAI-VL-R1}{this link}.