SpaceR: Reinforcing MLLMs in Video Spatial Reasoning
作者: Kun Ouyang, Yuanxin Liu, Haoning Wu, Yi Liu, Hao Zhou, Jie Zhou, Fandong Meng, Xu Sun
分类: cs.CV
发布日期: 2025-04-02 (更新: 2025-05-21)
🔗 代码/项目: GITHUB
💡 一句话要点
SpaceR:通过强化学习提升MLLM在视频空间推理中的能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频空间推理 多模态大语言模型 强化学习 可验证奖励 地图想象 数据集构建 机器人导航
📋 核心要点
- 现有MLLM在视频空间推理方面表现不足,主要原因是缺乏高质量数据集和有效的训练策略。
- 论文提出SpaceR框架,利用可验证奖励的强化学习(RLVR)范式,提升MLLM的空间推理能力。
- 实验表明,SpaceR在多个空间推理基准测试中达到SOTA,甚至超越GPT-4o,证明了其有效性。
📝 摘要(中文)
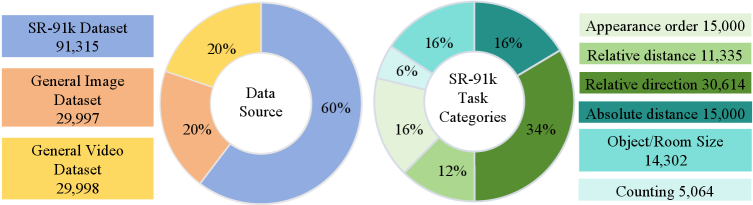
现有的多模态大型语言模型(MLLM)在视频空间推理方面面临重大挑战,即从观察到的视频帧中推断潜在的空间结构。这种局限性主要源于两个方面:缺乏高质量的用于该任务的数据集,以及缺乏有效的训练策略来发展空间推理能力。受到可验证奖励的强化学习(RLVR)在解锁LLM推理能力方面的成功的启发,本研究旨在通过RLVR范式来提高MLLM在视频空间推理方面的能力。为此,我们提出了SpaceR框架。首先,我们提出了SpaceR-151k,一个包含9.1万个问题的、涵盖各种具有可验证答案的空间推理场景的数据集,以及6万个用于维持通用多模态理解的样本。其次,我们提出了一种新的强化学习方法,即空间引导的RLVR(SG-RLVR),它通过一种新的地图想象机制扩展了群体相对策略优化(GRPO),鼓励模型在思考过程中推断空间布局,从而促进更有效的空间推理。大量的实验表明,SpaceR在空间推理基准测试(如VSI-Bench、STI-Bench和SPAR-Bench)上实现了最先进的性能,同时在视频理解基准测试(如Video-MME、TempCompass和LongVideoBench)上保持了有竞争力的结果。值得注意的是,SpaceR在VSI-Bench上的准确率超过了先进的GPT-4o 11.6%,并且与领先的专有模型Gemini-2.0-Flash相当,突出了我们的SpaceR-151k数据集和SG-RLVR在增强MLLM空间推理能力方面的有效性。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLM)在视频空间推理任务中的不足。现有方法缺乏高质量的数据集和有效的训练策略,导致模型无法准确理解和推断视频中的空间关系。这限制了MLLM在需要理解场景空间结构的应用中的表现。
核心思路:论文的核心思路是利用强化学习与可验证奖励(RLVR)范式,通过奖励机制引导模型学习空间推理能力。具体来说,模型通过与环境交互,生成空间布局的推断,并根据推断的正确性获得奖励。这种方法鼓励模型学习更准确的空间推理策略。
技术框架:SpaceR框架包含两个主要组成部分:SpaceR-151k数据集和空间引导的RLVR(SG-RLVR)算法。SpaceR-151k数据集提供了高质量的训练数据,涵盖了各种空间推理场景。SG-RLVR算法则在群体相对策略优化(GRPO)的基础上,引入了地图想象机制,鼓励模型在推理过程中构建空间布局的表征。整体流程是,模型首先接收视频帧作为输入,然后通过地图想象机制生成空间布局的推断,最后根据推断结果获得奖励,并更新模型参数。
关键创新:论文的关键创新在于提出了空间引导的RLVR(SG-RLVR)算法,该算法通过引入地图想象机制,显式地引导模型学习空间布局的表征。与传统的RLVR方法相比,SG-RLVR能够更有效地利用奖励信号,提高模型的空间推理能力。此外,SpaceR-151k数据集的构建也为该领域提供了宝贵的数据资源。
关键设计:SG-RLVR算法的关键设计包括:1) 地图想象机制,用于生成空间布局的表征;2) 基于GRPO的策略优化方法,用于更新模型参数;3) 可验证的奖励函数,用于评估模型推断的正确性。具体来说,地图想象机制可以采用各种神经网络结构实现,例如卷积神经网络或Transformer网络。奖励函数可以根据任务的具体要求进行设计,例如,可以根据模型推断的空间关系与真实空间关系的匹配程度来计算奖励。
🖼️ 关键图片

📊 实验亮点
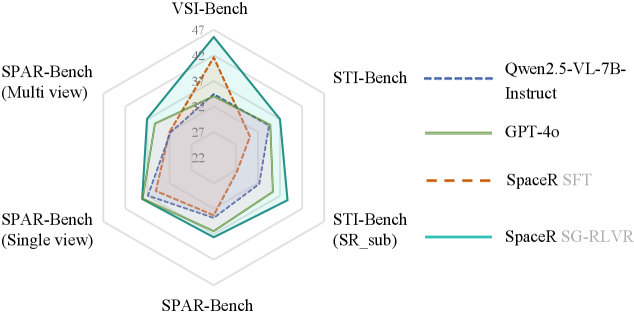
SpaceR在VSI-Bench、STI-Bench和SPAR-Bench等空间推理基准测试中取得了显著的性能提升,达到了state-of-the-art水平。尤其是在VSI-Bench上,SpaceR的准确率超过了GPT-4o 11.6%,并且与Gemini-2.0-Flash的性能相当,充分证明了SpaceR框架的有效性。
🎯 应用场景
该研究成果可广泛应用于机器人导航、自动驾驶、视频监控、智能家居等领域。通过提升模型对视频空间信息的理解能力,可以实现更智能化的场景感知和决策,例如,机器人可以根据视频信息自主规划路径,自动驾驶系统可以更准确地识别交通参与者的行为,视频监控系统可以自动检测异常事件。
📄 摘要(原文)
Video spatial reasoning, which involves inferring the underlying spatial structure from observed video frames, poses a significant challenge for existing Multimodal Large Language Models (MLLMs). This limitation stems primarily from 1) the absence of high-quality datasets for this task, and 2) the lack of effective training strategies to develop spatial reasoning capabilities. Motivated by the success of Reinforcement Learning with Verifiable Reward (RLVR) in unlocking LLM reasoning abilities, this work aims to improve MLLMs in video spatial reasoning through the RLVR paradigm. To this end, we introduce the $\textbf{SpaceR}$ framework. First, we present $\textbf{SpaceR-151k}$, a dataset with 91k questions spanning diverse spatial reasoning scenarios with verifiable answers, and 60k samples for maintaining general multimodal understanding. Second, we propose $\textbf{Spatially-Guided RLVR (SG-RLVR)}$, a novel reinforcement learning approach that extends Group Relative Policy Optimization (GRPO) with a novel map imagination mechanism, which encourages the model to infer spatial layouts in the thinking process, thereby facilitating more effective spatial reasoning. Extensive experiments demonstrate that SpaceR achieves state-of-the-art performance on spatial reasoning benchmarks (e.g., VSI-Bench, STI-Bench, and SPAR-Bench), while maintaining competitive results on video understanding benchmarks (e.g., Video-MME, TempCompass, and LongVideoBench). Remarkably, SpaceR surpasses the advanced GPT-4o by 11.6\% accuracy on VSI-Bench and is on par with the leading proprietary model Gemini-2.0-Flash, highlighting the effectiveness of our SpaceR-151k dataset and SG-RLVR in reinforcing spatial reasoning ability of MLLMs. Code, model, and dataset are available at https://github.com/OuyangKun10/SpaceR.