Beyond Wide-Angle Images: Structure-to-Detail Video Portrait Correction via Unsupervised Spatiotemporal Adaptation
作者: Wenbo Nie, Lang Nie, Chunyu Lin, Jingwen Chen, Ke Xing, Jiyuan Wang, Kang Liao
分类: cs.CV, cs.AI
发布日期: 2025-04-01 (更新: 2025-08-06)
💡 一句话要点
提出ImagePC和VideoPC模型,用于校正广角图像和视频中的人脸畸变。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱八:物理动画 (Physics-based Animation)
关键词: 人像校正 广角畸变 Transformer 扩散模型 无监督学习
📋 核心要点
- 广角相机易导致面部拉伸畸变,影响视觉效果,现有方法难以兼顾全局结构和局部细节。
- 提出ImagePC模型,结合Transformer和扩散模型,实现结构鲁棒性和细节优化;并扩展到无监督视频校正VideoPC。
- 构建了多样化的视频人像数据集,实验表明所提方法在人脸校正质量和时域稳定性上优于现有方法。
📝 摘要(中文)
本文提出了一种名为ImagePC的结构到细节的人像校正模型,用于解决广角相机造成的面部拉伸问题。该模型集成了Transformer的长程感知能力和扩散模型的多步去噪能力,实现了全局结构鲁棒性和局部细节优化。此外,考虑到视频标签的高昂成本,本文将ImagePC改造为适用于无标签广角视频的VideoPC模型,通过时空扩散自适应以及空间一致性和时间平滑约束来实现。VideoPC在保持高质量面部校正的同时,减轻了潜在的时间抖动。最后,本文构建了一个包含人数、光照条件和背景多样性的视频人像数据集,用于评估和训练模型。实验结果表明,所提出的方法在定量和定性方面均优于现有解决方案,有助于生成具有稳定和自然人像的高保真广角视频。代码和数据集将公开。
🔬 方法详解
问题定义:广角相机拍摄的人像,尤其是在镜头边缘,容易出现面部拉伸畸变,降低视觉吸引力。现有方法可能无法同时保证全局结构的准确性和局部细节的精细度,并且缺乏对无标签视频数据的有效处理方案。
核心思路:本文的核心思路是将Transformer的长程感知能力与扩散模型的多步去噪能力相结合,从而在校正人像畸变时,既能保证全局结构的合理性,又能恢复精细的局部细节。对于无标签视频,则通过时空自适应的方式,利用伪标签和时域一致性约束来训练模型。
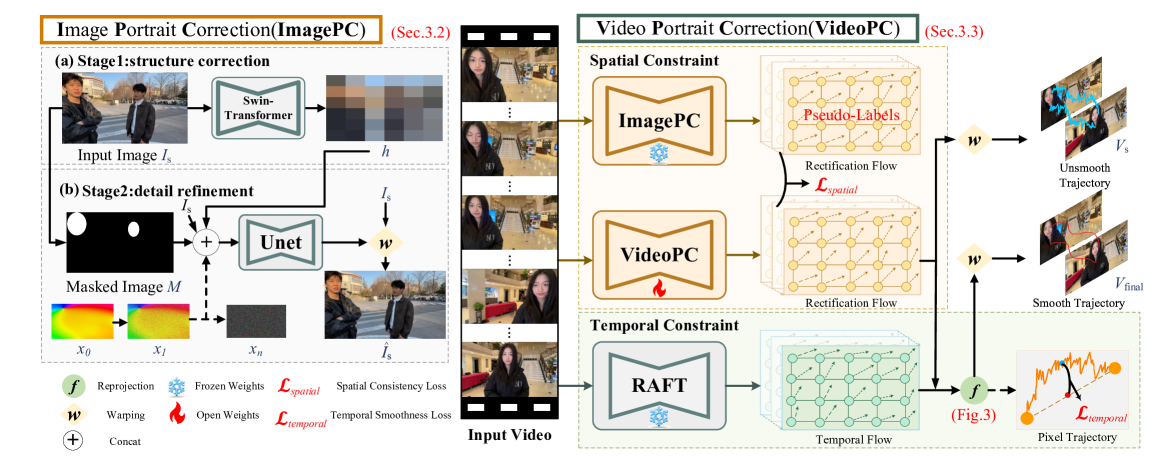
技术框架:ImagePC模型是一个统一的框架,包含Transformer模块用于捕捉图像的全局结构信息,以及扩散模型模块用于逐步去噪并恢复图像细节。VideoPC模型则在ImagePC的基础上,增加了时空自适应模块,包括空间一致性约束和时间平滑约束。空间一致性约束鼓励去噪后的图像逼近符合广角畸变分布模式的伪标签,时间平滑约束则通过反向光流估计校正轨迹并进行平滑处理。
关键创新:主要的创新点在于:1) 将Transformer和扩散模型集成到一个统一的框架中,实现全局结构和局部细节的协同优化;2) 提出了针对无标签视频的时空自适应方法,通过伪标签和时域一致性约束,实现了在盲场景下的高质量人像校正;3) 构建了一个大规模、多样化的视频人像数据集,为相关研究提供了基准。
关键设计:在ImagePC中,Transformer模块的具体结构和参数设置未知,扩散模型采用多步去噪的方式,具体步数未知。VideoPC中,空间一致性约束的具体损失函数形式未知,时间平滑约束中,反向光流估计的具体算法未知,平滑方法也未知。数据集的规模和多样性体现在人数、光照和背景上,具体指标未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,所提出的ImagePC和VideoPC模型在人像校正任务上取得了显著的性能提升。相较于现有方法,该方法在定量指标和视觉效果上均表现更优,尤其在处理无标签广角视频时,能够有效减轻时间抖动,生成稳定且自然的人像视频。具体性能数据和对比基线在论文中给出,此处未知。
🎯 应用场景
该研究成果可应用于视频会议、社交媒体、电影制作等领域,提升广角摄像头拍摄的人像视频质量,改善用户体验。通过减少面部畸变,使人像更加自然美观,具有广泛的应用前景和商业价值。未来可进一步探索在移动设备上的部署和优化。
📄 摘要(原文)
Wide-angle cameras, despite their popularity for content creation, suffer from distortion-induced facial stretching-especially at the edge of the lens-which degrades visual appeal. To address this issue, we propose a structure-to-detail portrait correction model named ImagePC. It integrates the long-range awareness of the transformer and multi-step denoising of diffusion models into a unified framework, achieving global structural robustness and local detail refinement. Besides, considering the high cost of obtaining video labels, we then repurpose ImagePC for unlabeled wide-angle videos (termed VideoPC), by spatiotemporal diffusion adaption with spatial consistency and temporal smoothness constraints. For the former, we encourage the denoised image to approximate pseudo labels following the wide-angle distortion distribution pattern, while for the latter, we derive rectification trajectories with backward optical flows and smooth them. Compared with ImagePC, VideoPC maintains high-quality facial corrections in space and mitigates the potential temporal shakes sequentially in blind scenarios. Finally, to establish an evaluation benchmark and train the framework, we establish a video portrait dataset with a large diversity in the number of people, lighting conditions, and background. Experiments demonstrate that the proposed methods outperform existing solutions quantitatively and qualitatively, contributing to high-fidelity wide-angle videos with stable and natural portraits. The codes and dataset will be available.