Hierarchical Flow Diffusion for Efficient Frame Interpolation
作者: Yang Hai, Guo Wang, Tan Su, Wenjie Jiang, Yinlin Hu
分类: cs.CV
发布日期: 2025-04-01
备注: Accepted by CVPR 2025
💡 一句话要点
提出基于分层光流扩散的视频帧插值方法,显著提升精度与效率。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视频帧插值 扩散模型 光流估计 分层扩散 图像合成
📋 核心要点
- 现有基于扩散模型的视频帧插值方法在精度和效率上与非扩散方法相比仍有较大差距,主要原因是直接在较大的潜在空间中进行去噪。
- 该论文提出通过分层扩散模型显式建模双向光流,减小去噪过程中的搜索空间,并使用光流引导的图像合成器生成最终插值帧。
- 实验结果表明,该方法在精度上达到了最先进水平,并且比其他基于扩散模型的方法快10倍以上,实现了显著的性能提升。
📝 摘要(中文)
本文提出了一种用于视频帧插值的分层光流扩散方法,旨在提高精度和效率,克服了现有基于扩散模型的方法在帧插值任务中与非扩散方法相比存在的差距。现有方法通常直接在潜在空间中进行去噪,由于潜在空间较大,效果欠佳。本文显式地建模双向光流,并采用分层扩散模型,从而在去噪过程中拥有更小的搜索空间。基于光流扩散模型,使用一个光流引导的图像合成器生成最终结果。光流扩散模型和图像合成器以端到端的方式进行训练。实验结果表明,该方法在精度上达到了最先进水平,并且比其他基于扩散模型的方法快10倍以上。
🔬 方法详解
问题定义:视频帧插值旨在生成两帧图像之间的中间帧,现有基于扩散模型的方法通常直接在图像的潜在空间进行去噪,但由于潜在空间维度过高,导致训练困难,效率低下,且精度提升有限。
核心思路:该论文的核心思路是将帧插值问题分解为光流估计和图像合成两个步骤,并利用扩散模型对光流进行建模。通过显式地建模光流,可以有效减小扩散模型需要处理的搜索空间,从而提高训练效率和插值精度。
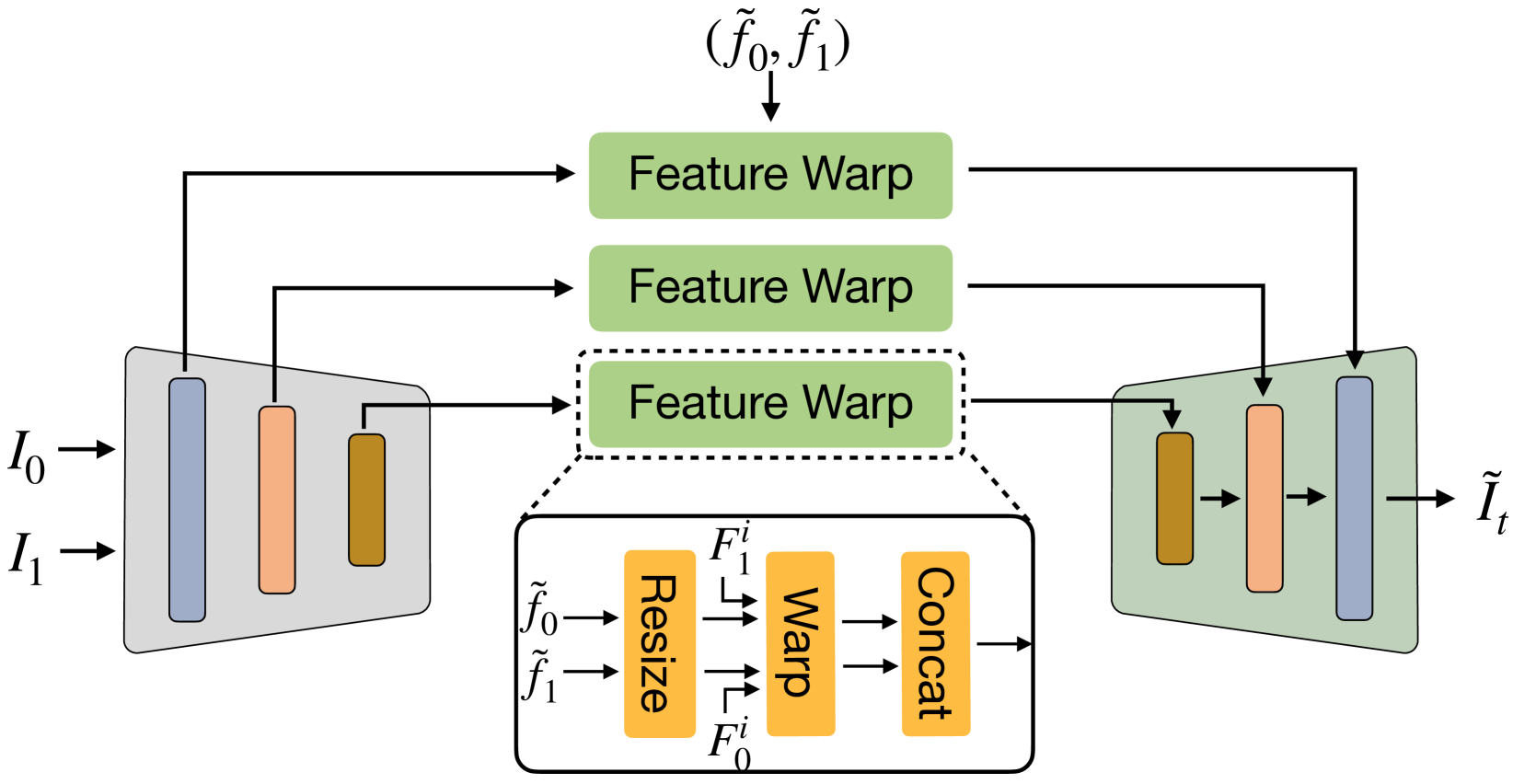
技术框架:该方法包含两个主要模块:光流扩散模型和图像合成器。首先,光流扩散模型学习生成双向光流。然后,图像合成器利用生成的光流信息,将输入帧warp到目标时间点,并进行融合,最终生成插值帧。这两个模块以端到端的方式进行训练。
关键创新:该方法最重要的创新点在于使用分层扩散模型显式地建模光流。与直接在图像潜在空间进行扩散的方法相比,光流的维度更低,结构更简单,因此更容易学习和生成。此外,分层扩散模型可以逐步细化光流的细节,从而提高光流的精度。
关键设计:光流扩散模型采用U-Net结构,并使用分层扩散过程逐步添加噪声。图像合成器使用光流引导的warp操作和融合网络,将输入帧的信息传递到目标时间点。损失函数包括光流重建损失和图像重建损失,用于约束光流的准确性和插值帧的质量。具体的网络结构和参数设置在论文中有详细描述(未知)。
🖼️ 关键图片


📊 实验亮点
该方法在视频帧插值任务上取得了state-of-the-art的精度,并且相比于其他基于扩散模型的方法,速度提升了10倍以上。这意味着该方法在保证精度的同时,显著提高了效率,使其更具实用价值。具体的量化指标(如PSNR、SSIM等)和对比实验结果可在论文中找到(未知)。
🎯 应用场景
该研究成果可广泛应用于视频编辑、慢动作视频生成、视频修复等领域。通过提高视频帧插值的精度和效率,可以改善用户观看体验,并为相关应用提供更强大的技术支持。未来,该方法有望应用于更高分辨率的视频处理,以及实时视频插值等场景。
📄 摘要(原文)
Most recent diffusion-based methods still show a large gap compared to non-diffusion methods for video frame interpolation, in both accuracy and efficiency. Most of them formulate the problem as a denoising procedure in latent space directly, which is less effective caused by the large latent space. We propose to model bilateral optical flow explicitly by hierarchical diffusion models, which has much smaller search space in the denoising procedure. Based on the flow diffusion model, we then use a flow-guided images synthesizer to produce the final result. We train the flow diffusion model and the image synthesizer end to end. Our method achieves state of the art in accuracy, and 10+ times faster than other diffusion-based methods. The project page is at: https://hfd-interpolation.github.io.