CamoSAM2: Motion-Appearance Induced Auto-Refining Prompts for Video Camouflaged Object Detection
作者: Xin Zhang, Keren Fu, Qijun Zhao
分类: cs.CV
发布日期: 2025-04-01
备注: 10 pages, 5 figures,
💡 一句话要点
CamoSAM2:利用运动-外观信息自动优化提示,用于视频伪装目标检测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频伪装目标检测 SAM2 运动信息 外观信息 提示学习 自适应多提示优化 目标分割
📋 核心要点
- 现有方法难以区分视频中与周围环境高度相似的伪装目标,导致SAM2在自动化视频伪装目标检测任务中面临挑战。
- CamoSAM2通过运动-外观提示诱导器(MAPI)和自适应多提示优化(AMPR)策略,自动生成和优化SAM2的提示,提升分割质量。
- 实验结果表明,CamoSAM2在mIoU指标上显著优于现有方法,并实现了更快的推理速度,证明了其有效性。
📝 摘要(中文)
本文提出CamoSAM2,一个运动-外观提示诱导与优化框架,旨在为Segment Anything Model 2 (SAM2) 自动生成和优化提示,从而实现高质量的视频伪装目标检测与分割。CamoSAM2包含一个提示诱导器,它同时整合运动和外观线索来检测伪装目标,产生比现有方法更准确的初始预测。此外,还提出了一个基于视频的自适应多提示优化(AMPR)策略,专门为SAM2设计,以减少初始粗糙掩码中的提示误差,并进一步生成良好的提示。AMPR包含一个三步过程,通过伪装目标确定、关键提示帧选择和多提示形成来生成可靠的提示。在两个基准数据集上的大量实验表明,CamoSAM2显著优于现有的最先进方法,在mIoU指标上提高了8.0%和10.1%。此外,该方法实现了比当前VCOD模型更快的推理速度。
🔬 方法详解
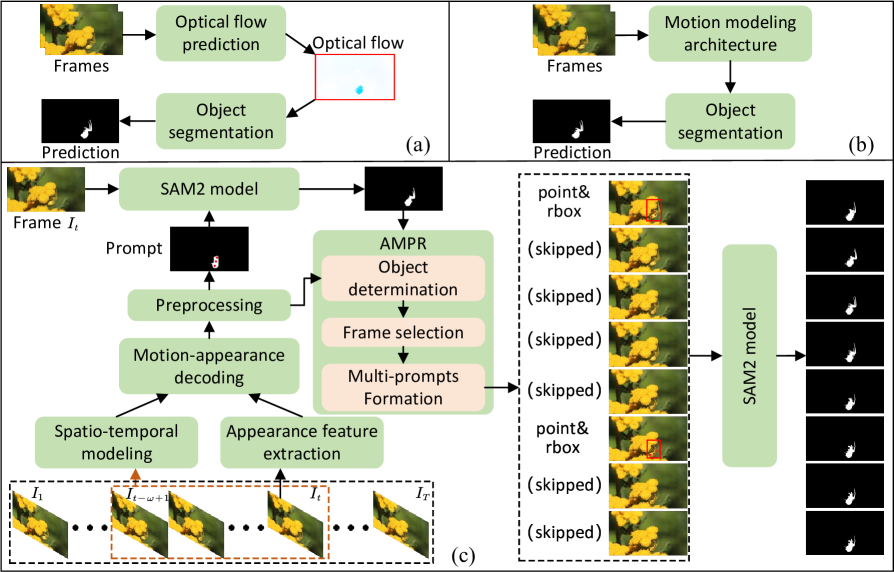
问题定义:视频伪装目标检测(VCOD)旨在识别并分割视频中与背景高度相似的目标。现有方法难以有效利用运动信息和外观信息,导致检测精度不高,且推理速度较慢。SAM2虽然在视频目标分割上表现出色,但其依赖人工提示,难以直接应用于自动化VCOD任务。
核心思路:CamoSAM2的核心思路是自动生成高质量的提示,并针对SAM2进行优化,从而克服伪装目标带来的挑战。通过融合运动和外观信息,可以更准确地定位伪装目标。自适应多提示优化策略则可以进一步减少提示误差,提高分割精度。
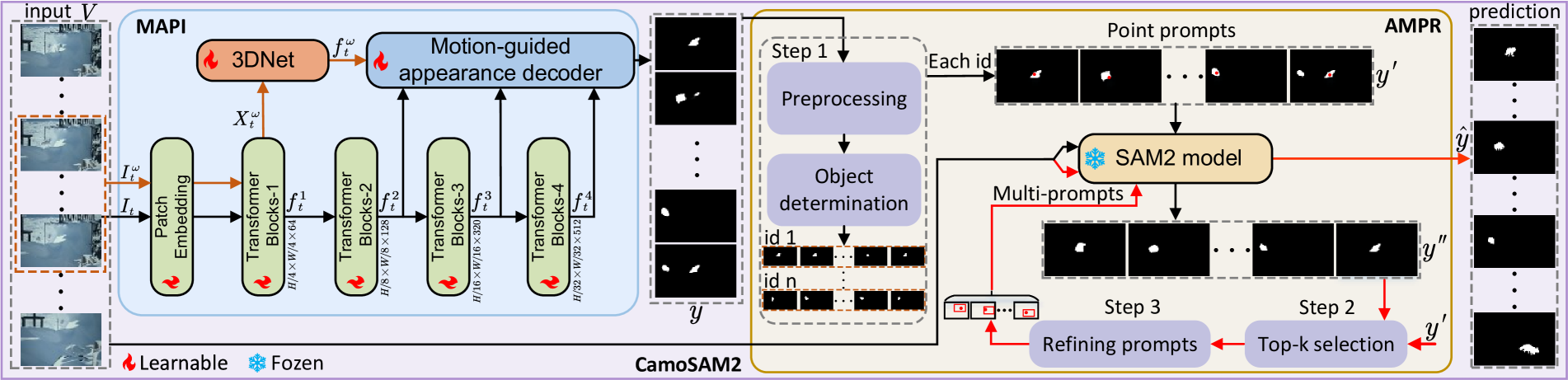
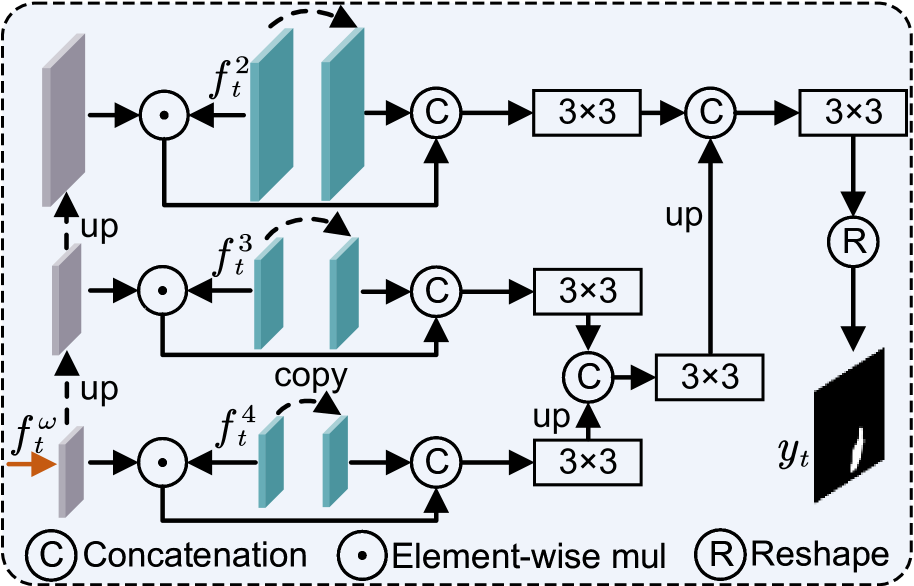
技术框架:CamoSAM2主要包含两个模块:运动-外观提示诱导器(MAPI)和自适应多提示优化(AMPR)。MAPI首先利用运动和外观信息生成初始提示。然后,AMPR通过伪装目标确定、关键提示帧选择和多提示形成三个步骤,对初始提示进行优化,生成更可靠的提示。最终,将优化后的提示输入SAM2,得到最终的分割结果。
关键创新:CamoSAM2的关键创新在于同时利用运动和外观信息生成初始提示,以及提出了一种针对SAM2的自适应多提示优化策略。与现有方法相比,CamoSAM2能够更准确地定位伪装目标,并减少提示误差,从而提高分割精度。AMPR策略中的三步过程,特别是关键提示帧选择,是保证提示质量的关键。
关键设计:MAPI的具体实现细节未知,但强调了运动和外观信息的融合。AMPR中的伪装目标确定方法未知。关键提示帧选择的具体算法未知,但其目的是选择信息量最大的帧来生成提示。多提示形成的具体方法未知,但其目的是利用多个提示来提高分割的鲁棒性。损失函数和网络结构等细节未在摘要中提及,因此未知。
🖼️ 关键图片
📊 实验亮点
CamoSAM2在两个基准数据集上取得了显著的性能提升,mIoU指标分别提高了8.0%和10.1%,表明其在视频伪装目标检测任务中的有效性。此外,CamoSAM2实现了比当前VCOD模型更快的推理速度,使其更具实用价值。这些实验结果证明了CamoSAM2在精度和效率方面的优势。
🎯 应用场景
CamoSAM2在野生动物保护、海洋生物研究、医学图像分析等领域具有广泛的应用前景。它可以帮助研究人员自动检测和分割伪装生物或病灶,提高研究效率和准确性。此外,该方法还可以应用于智能监控、自动驾驶等领域,提高系统对复杂环境的感知能力。
📄 摘要(原文)
The Segment Anything Model 2 (SAM2), a prompt-guided video foundation model, has remarkably performed in video object segmentation, drawing significant attention in the community. Due to the high similarity between camouflaged objects and their surroundings, which makes them difficult to distinguish even by the human eye, the application of SAM2 for automated segmentation in real-world scenarios faces challenges in camouflage perception and reliable prompts generation. To address these issues, we propose CamoSAM2, a motion-appearance prompt inducer (MAPI) and refinement framework to automatically generate and refine prompts for SAM2, enabling high-quality automatic detection and segmentation in VCOD task. Initially, we introduce a prompt inducer that simultaneously integrates motion and appearance cues to detect camouflaged objects, delivering more accurate initial predictions than existing methods. Subsequently, we propose a video-based adaptive multi-prompts refinement (AMPR) strategy tailored for SAM2, aimed at mitigating prompt error in initial coarse masks and further producing good prompts. Specifically, we introduce a novel three-step process to generate reliable prompts by camouflaged object determination, pivotal prompting frame selection, and multi-prompts formation. Extensive experiments conducted on two benchmark datasets demonstrate that our proposed model, CamoSAM2, significantly outperforms existing state-of-the-art methods, achieving increases of 8.0% and 10.1% in mIoU metric. Additionally, our method achieves the fastest inference speed compared to current VCOD models.