SuperEvent: Cross-Modal Learning of Event-based Keypoint Detection for SLAM
作者: Yannick Burkhardt, Simon Schaefer, Stefan Leutenegger
分类: cs.CV
发布日期: 2025-03-31 (更新: 2025-09-29)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
SuperEvent:提出一种基于跨模态学习的事件相机关键点检测方法,用于SLAM。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 事件相机 SLAM 关键点检测 自监督学习 跨模态学习 机器人导航 视觉里程计
📋 核心要点
- 现有事件相机SLAM方法在运动依赖性和噪声影响下,关键点匹配能力受限,影响了整体性能。
- SuperEvent利用帧相机数据进行自监督学习,预测事件流中的稳定关键点和表达性描述子。
- 实验表明,SuperEvent集成到SLAM框架后,显著超越了现有基于事件的SLAM技术水平。
📝 摘要(中文)
事件相机关键点检测与匹配具有巨大潜力,可以将事件传感器集成到为帧相机开发的高度优化的视觉SLAM系统中。然而,现有方法难以应对关键点对运动的依赖性外观以及事件流中普遍存在的复杂噪声,导致特征匹配能力严重受限,下游任务性能较差。为了缓解这个问题,我们提出SuperEvent,一种数据驱动的方法,用于预测具有表达性描述子的稳定关键点。由于缺乏带有ground truth关键点标签的事件数据集,我们利用现有的基于帧的关键点检测器,在易于获得的事件对齐和同步的灰度帧上进行自监督:考虑到事件是场景外观和相机运动的产物,我们生成时间上稀疏的关键点伪标签。结合我们新颖的、信息丰富的事件表示,SuperEvent能够有效地学习事件流中鲁棒的关键点检测和描述。最后,我们通过将SuperEvent集成到最初为传统相机开发的现代稀疏关键点和基于描述子的SLAM框架中,证明了SuperEvent的有效性,并在基于事件的SLAM中大幅超越了现有技术水平。源代码可在https://ethz-mrl.github.io/SuperEvent/ 获得。
🔬 方法详解
问题定义:现有基于事件相机的SLAM方法在关键点检测和匹配方面面临挑战。事件流的特性(如运动依赖性和噪声)使得传统的关键点检测器难以直接应用。此外,缺乏带有ground truth关键点标签的事件数据集,限制了有监督学习方法的应用。现有方法在复杂场景和快速运动下,特征匹配的准确性和鲁棒性不足,导致SLAM系统的性能下降。
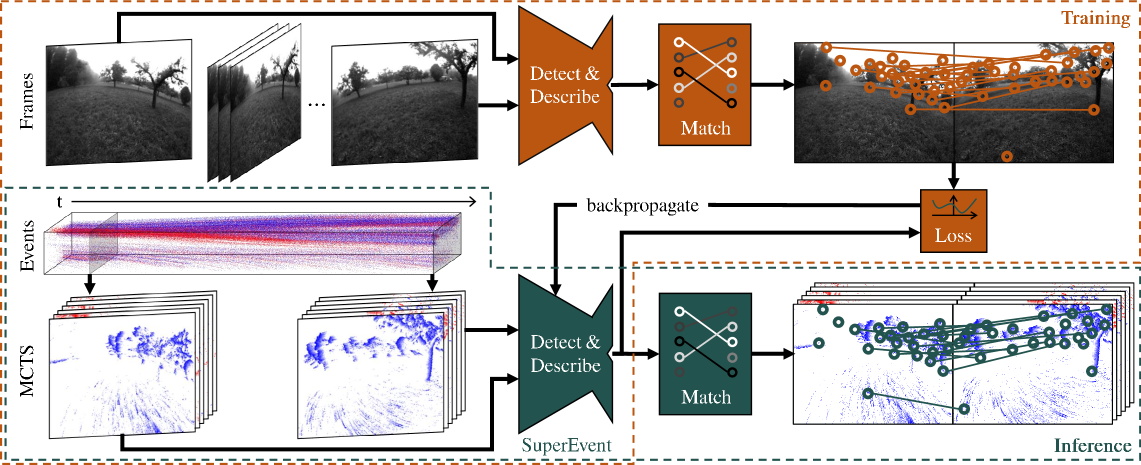
核心思路:SuperEvent的核心思路是利用 readily available 的帧相机数据进行自监督学习,从而克服事件数据缺乏标注的问题。通过将事件流与同步的灰度帧对齐,并使用帧相机上的成熟关键点检测器生成伪标签,SuperEvent可以在事件数据上学习到鲁棒的关键点检测和描述。这种跨模态学习的方法充分利用了帧相机数据的优势,避免了手动标注事件数据的困难。
技术框架:SuperEvent的整体框架包含以下几个主要阶段:1) 事件流和灰度帧的同步与对齐;2) 使用帧相机关键点检测器在灰度帧上生成关键点伪标签;3) 设计信息丰富的事件表示,用于输入到神经网络;4) 使用自监督学习方法训练神经网络,使其能够预测事件流中的关键点和描述子;5) 将训练好的关键点检测器和描述子集成到SLAM系统中进行验证。
关键创新:SuperEvent的关键创新在于:1) 提出了基于跨模态自监督学习的事件相机关键点检测方法,有效解决了事件数据缺乏标注的问题;2) 设计了信息丰富的事件表示,能够充分利用事件流中的时空信息;3) 将学习到的关键点检测器和描述子成功集成到SLAM系统中,并取得了显著的性能提升。与现有方法相比,SuperEvent能够更鲁棒地检测和描述事件流中的关键点,从而提高SLAM系统的整体性能。
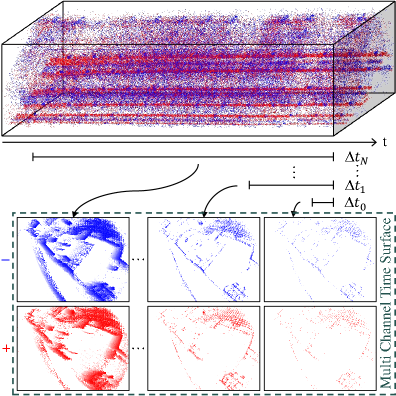
关键设计:SuperEvent的关键设计包括:1) 使用DVS-SLAM数据集,该数据集包含同步的事件流和灰度帧;2) 使用FAST角点检测器在灰度帧上生成关键点伪标签,并根据事件流的运动信息进行筛选;3) 设计了一种基于体素网格的事件表示,将事件流转换为三维体素网格,并对每个体素进行编码;4) 使用一个卷积神经网络来学习关键点检测和描述,该网络包含多个卷积层、池化层和全连接层;5) 使用一种基于对比损失的自监督学习方法,鼓励网络学习到具有区分性的关键点描述子。
🖼️ 关键图片

📊 实验亮点
SuperEvent在DVS-SLAM数据集上进行了评估,实验结果表明,SuperEvent在基于事件的SLAM中大幅超越了现有技术水平。具体而言,SuperEvent在定位精度和建图质量方面均取得了显著提升,并且在快速运动和光照变化剧烈的场景中表现出更强的鲁棒性。与现有的基于事件的SLAM方法相比,SuperEvent能够更准确地估计相机位姿,并构建更精确的环境地图。
🎯 应用场景
SuperEvent在机器人导航、自动驾驶、无人机等领域具有广泛的应用前景。事件相机具有高动态范围、低延迟和低功耗等优点,使其在光照条件恶劣或运动速度较快的场景中表现出色。SuperEvent的出现,使得事件相机能够更好地应用于SLAM系统,从而提高机器人在复杂环境中的定位和建图能力。未来,SuperEvent有望推动事件相机在更多实际场景中的应用。
📄 摘要(原文)
Event-based keypoint detection and matching holds significant potential, enabling the integration of event sensors into highly optimized Visual SLAM systems developed for frame cameras over decades of research. Unfortunately, existing approaches struggle with the motion-dependent appearance of keypoints and the complex noise prevalent in event streams, resulting in severely limited feature matching capabilities and poor performance on downstream tasks. To mitigate this problem, we propose SuperEvent, a data-driven approach to predict stable keypoints with expressive descriptors. Due to the absence of event datasets with ground truth keypoint labels, we leverage existing frame-based keypoint detectors on readily available event-aligned and synchronized gray-scale frames for self-supervision: we generate temporally sparse keypoint pseudo-labels considering that events are a product of both scene appearance and camera motion. Combined with our novel, information-rich event representation, we enable SuperEvent to effectively learn robust keypoint detection and description in event streams. Finally, we demonstrate the usefulness of SuperEvent by its integration into a modern sparse keypoint and descriptor-based SLAM framework originally developed for traditional cameras, surpassing the state-of-the-art in event-based SLAM by a wide margin. Source code is available at https://ethz-mrl.github.io/SuperEvent/.