Chapter-Llama: Efficient Chaptering in Hour-Long Videos with LLMs
作者: Lucas Ventura, Antoine Yang, Cordelia Schmid, Gül Varol
分类: cs.CV
发布日期: 2025-03-31
备注: CVPR 2025 Camera ready. Project page: https://imagine.enpc.fr/~lucas.ventura/chapter-llama/
💡 一句话要点
Chapter-Llama利用LLM高效处理长视频章节划分与标题生成任务
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长视频章节划分 大型语言模型 语音引导帧选择 视频理解 自然语言处理
📋 核心要点
- 现有长视频章节划分方法效率低或效果差,难以实现长视频的有效导航和内容检索。
- Chapter-Llama利用LLM处理语音转录和视频字幕,通过语音引导帧选择策略提升效率。
- 实验表明,Chapter-Llama在长视频章节划分任务上显著优于现有技术,F1值提升显著。
📝 摘要(中文)
本文提出了一种名为'Chapter-Llama'的框架,用于解决长视频章节划分问题,即把长视频时间线分割成语义单元并生成相应的章节标题。自动章节划分能够有效提升长视频的导航和内容检索效率。该框架利用预训练的大型语言模型(LLM)及其长上下文窗口,输入语音转录文本和描述视频帧的字幕及其对应的时间戳。考虑到详尽地为所有帧生成字幕效率低下,论文提出了一种基于语音转录内容的轻量级语音引导帧选择策略,实验证明该策略具有显著优势。通过训练LLM输出章节边界的时间戳以及自由形式的章节标题,该方法能够以单次前向传播的方式处理长达一小时的视频。在VidChapters-7M基准测试中,该方法取得了显著的性能提升(例如,F1 score从26.7提升到45.3)。为了促进进一步研究,作者公开了代码和模型。
🔬 方法详解
问题定义:论文旨在解决长视频章节划分问题,即自动将长视频分割成具有语义意义的章节,并为每个章节生成标题。现有方法要么效率低下,无法处理长视频,要么精度不足,无法准确划分章节。痛点在于如何在计算资源有限的情况下,有效利用视频信息进行章节划分。
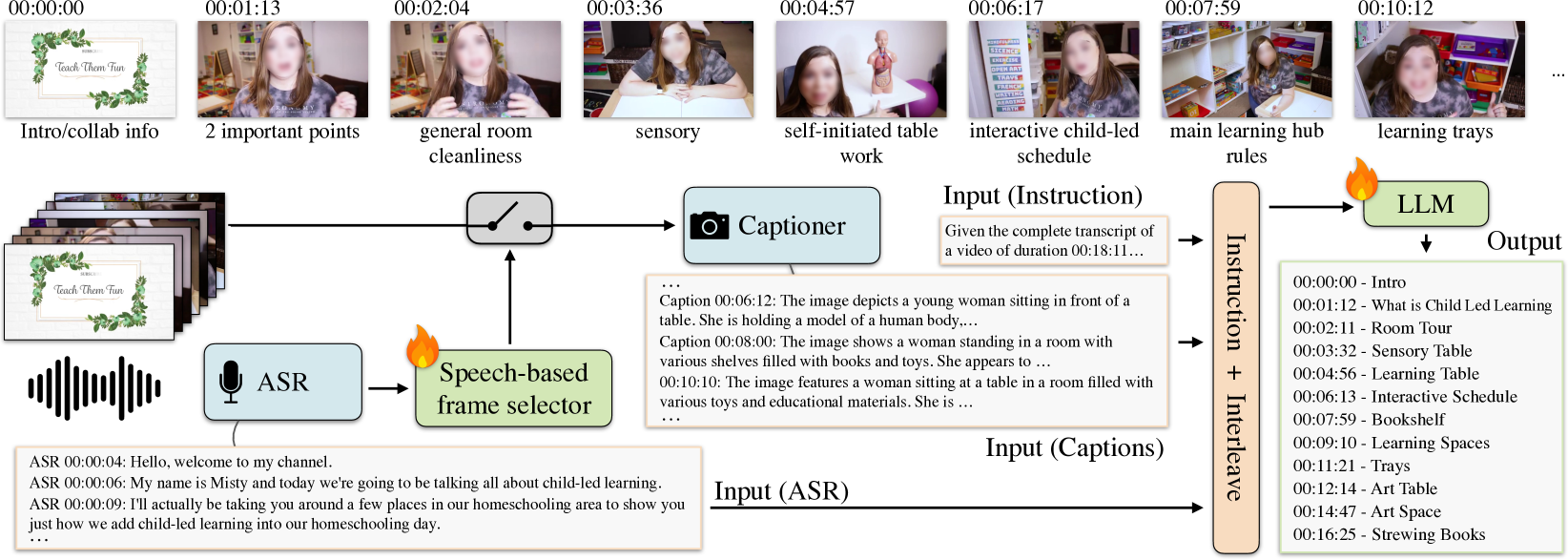
核心思路:论文的核心思路是利用大型语言模型(LLM)强大的文本理解和生成能力,将视频章节划分问题转化为文本处理问题。通过将视频的语音转录和关键帧字幕输入LLM,让LLM学习章节边界和标题的生成规则。这样可以避免直接处理视频像素,从而大大提高效率。
技术框架:Chapter-Llama框架主要包含以下几个阶段:1) 语音转录:将视频的音频转换为文本。2) 语音引导帧选择:根据语音转录的内容,选择与语音内容相关的关键帧。3) 视频字幕生成:为选定的关键帧生成字幕。4) LLM章节划分与标题生成:将语音转录和关键帧字幕及其时间戳输入LLM,LLM输出章节边界的时间戳和章节标题。
关键创新:论文最重要的技术创新点在于提出了语音引导帧选择策略。该策略能够根据语音内容选择与章节内容相关的关键帧,从而避免了对所有帧进行字幕生成,大大提高了效率。此外,利用LLM进行章节划分和标题生成也是一个创新点,充分利用了LLM的文本理解和生成能力。
关键设计:论文的关键设计包括:1) 使用预训练的LLM,并对其进行微调,以适应章节划分任务。2) 设计了语音引导帧选择策略,具体实现细节未知。3) 使用时间戳作为LLM的输入,以便LLM能够准确地确定章节边界。4) 损失函数的设计细节未知,但应该包含章节边界预测和标题生成的损失。
🖼️ 关键图片


📊 实验亮点
Chapter-Llama在VidChapters-7M基准测试中取得了显著的性能提升,F1 score从现有最佳方法的26.7提升到45.3,证明了该方法的有效性。该方法能够以单次前向传播的方式处理长达一小时的视频,展示了其高效性。语音引导帧选择策略能够有效减少计算量,同时保持较高的章节划分精度。
🎯 应用场景
该研究成果可广泛应用于视频平台、在线教育、新闻媒体等领域。通过自动章节划分,用户可以更方便地浏览和检索长视频内容,提高观看效率和用户体验。例如,用户可以快速找到感兴趣的知识点,或者跳过不感兴趣的部分。未来,该技术还可以应用于视频摘要生成、视频内容分析等任务。
📄 摘要(原文)
We address the task of video chaptering, i.e., partitioning a long video timeline into semantic units and generating corresponding chapter titles. While relatively underexplored, automatic chaptering has the potential to enable efficient navigation and content retrieval in long-form videos. In this paper, we achieve strong chaptering performance on hour-long videos by efficiently addressing the problem in the text domain with our 'Chapter-Llama' framework. Specifically, we leverage a pretrained large language model (LLM) with large context window, and feed as input (i) speech transcripts and (ii) captions describing video frames, along with their respective timestamps. Given the inefficiency of exhaustively captioning all frames, we propose a lightweight speech-guided frame selection strategy based on speech transcript content, and experimentally demonstrate remarkable advantages. We train the LLM to output timestamps for the chapter boundaries, as well as free-form chapter titles. This simple yet powerful approach scales to processing one-hour long videos in a single forward pass. Our results demonstrate substantial improvements (e.g., 45.3 vs 26.7 F1 score) over the state of the art on the recent VidChapters-7M benchmark. To promote further research, we release our code and models at our project page.