Easi3R: Estimating Disentangled Motion from DUSt3R Without Training
作者: Xingyu Chen, Yue Chen, Yuliang Xiu, Andreas Geiger, Anpei Chen
分类: cs.CV
发布日期: 2025-03-31 (更新: 2025-10-01)
备注: Page: https://easi3r.github.io/ Code: https://github.com/Inception3D/Easi3R
期刊: IEEE/CVF International Conference on Computer Vision (ICCV), 2025
💡 一句话要点
Easi3R:无需训练,从DUSt3R中解耦运动信息以实现动态场景重建
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 动态场景重建 免训练学习 注意力机制 运动解耦 4D重建
📋 核心要点
- 现有4D重建方法依赖大规模4D数据集训练或在动态数据上微调3D模型,数据规模和泛化性受限。
- Easi3R通过在推理时自适应调整DUSt3R的注意力层,无需训练即可解耦相机和物体运动信息。
- 实验表明,Easi3R在动态视频重建上显著优于需要大量动态数据训练或微调的现有方法。
📝 摘要(中文)
DUSt3R的最新进展通过Transformer网络架构和对大规模3D数据集的直接监督,实现了对静态场景的稠密点云和相机参数的鲁棒估计。相比之下,可用的4D数据集的有限规模和多样性成为训练高度泛化的4D模型的主要瓶颈。这种限制促使传统的4D方法在可扩展的动态视频数据上微调3D模型,并结合光流和深度等额外的几何先验。本文采取相反的路径,提出Easi3R,一种简单而有效的免训练4D重建方法。我们的方法在推理过程中应用注意力自适应,无需从头开始的预训练或网络微调。我们发现DUSt3R中的注意力层固有地编码了关于相机和物体运动的丰富信息。通过仔细解耦这些注意力图,我们实现了准确的动态区域分割、相机姿态估计和4D稠密点云重建。在真实动态视频上的大量实验表明,我们轻量级的注意力自适应显著优于之前在大量动态数据集上训练或微调的state-of-the-art方法。我们的代码已公开发布,供研究使用。
🔬 方法详解
问题定义:现有的动态场景4D重建方法通常需要大量的4D数据集进行训练,或者依赖于在动态视频数据上微调预训练的3D模型。这些方法受限于4D数据集的规模和多样性,导致泛化能力不足,并且微调过程也增加了计算成本。因此,如何在缺乏大规模4D训练数据的情况下,实现准确且高效的动态场景重建是一个关键问题。
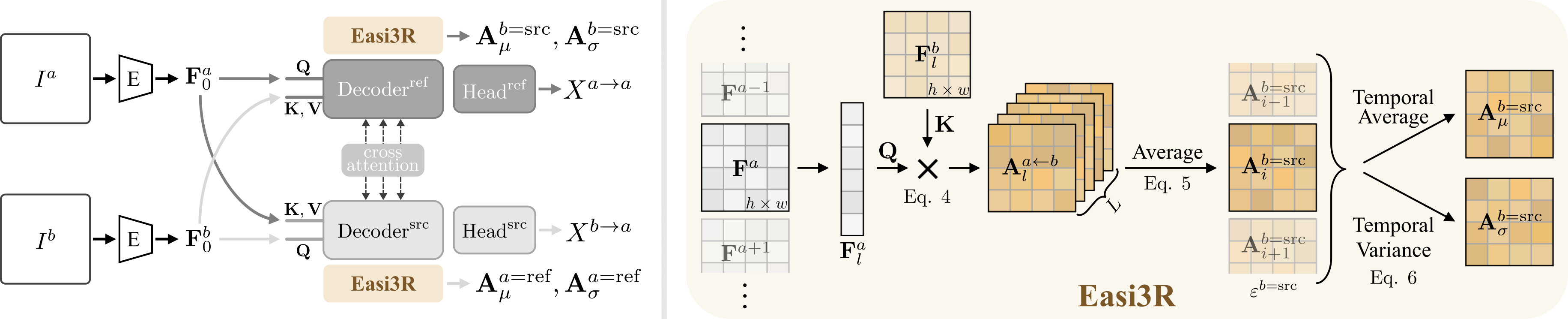
核心思路:Easi3R的核心思路是利用预训练的静态场景重建模型DUSt3R中注意力层所蕴含的运动信息。通过在推理阶段对注意力图进行解耦和自适应调整,从而提取出相机和物体的运动信息,实现动态场景的重建。这种方法避免了对动态数据的训练或微调,从而提高了效率和泛化能力。
技术框架:Easi3R的整体框架主要包括以下几个步骤:1) 使用预训练的DUSt3R模型提取特征和注意力图;2) 对注意力图进行解耦,分离出相机运动和物体运动相关的注意力;3) 基于解耦的注意力图进行动态区域分割、相机姿态估计和4D稠密点云重建。整个过程无需额外的训练或微调。
关键创新:Easi3R最关键的创新在于其免训练的注意力自适应方法。它通过分析和解耦预训练模型中的注意力图,直接提取动态场景中的运动信息,避免了对大规模动态数据集的依赖。这种方法不仅提高了效率,还可能更好地泛化到未见过的动态场景。
关键设计:Easi3R的关键设计包括:1) 注意力解耦策略,用于分离相机和物体运动相关的注意力;2) 基于解耦注意力的动态区域分割方法,用于区分静态和动态区域;3) 利用解耦注意力进行相机姿态估计和4D点云重建的具体算法。论文中可能还包含一些超参数的设置,例如注意力解耦的阈值等,但具体细节需要参考论文原文。
🖼️ 关键图片


📊 实验亮点
Easi3R在真实动态视频上的实验结果表明,其性能显著优于需要大量动态数据集训练或微调的state-of-the-art方法。具体的性能提升数据需要在论文中查找,但摘要中明确指出Easi3R通过轻量级的注意力自适应,实现了更准确的动态区域分割、相机姿态估计和4D稠密点云重建,证明了其有效性和优越性。
🎯 应用场景
Easi3R具有广泛的应用前景,例如在自动驾驶中,可以用于动态场景的感知和重建,提高车辆对周围环境的理解能力。在机器人领域,可以用于动态环境下的目标跟踪和操作。此外,该方法还可以应用于虚拟现实和增强现实等领域,提供更逼真的动态场景体验。由于其免训练的特性,Easi3R在数据稀缺的场景下具有独特的优势。
📄 摘要(原文)
Recent advances in DUSt3R have enabled robust estimation of dense point clouds and camera parameters of static scenes, leveraging Transformer network architectures and direct supervision on large-scale 3D datasets. In contrast, the limited scale and diversity of available 4D datasets present a major bottleneck for training a highly generalizable 4D model. This constraint has driven conventional 4D methods to fine-tune 3D models on scalable dynamic video data with additional geometric priors such as optical flow and depths. In this work, we take an opposite path and introduce Easi3R, a simple yet efficient training-free method for 4D reconstruction. Our approach applies attention adaptation during inference, eliminating the need for from-scratch pre-training or network fine-tuning. We find that the attention layers in DUSt3R inherently encode rich information about camera and object motion. By carefully disentangling these attention maps, we achieve accurate dynamic region segmentation, camera pose estimation, and 4D dense point map reconstruction. Extensive experiments on real-world dynamic videos demonstrate that our lightweight attention adaptation significantly outperforms previous state-of-the-art methods that are trained or finetuned on extensive dynamic datasets. Our code is publicly available for research purpose at https://easi3r.github.io/