Any2Caption:Interpreting Any Condition to Caption for Controllable Video Generation
作者: Shengqiong Wu, Weicai Ye, Jiahao Wang, Quande Liu, Xintao Wang, Pengfei Wan, Di Zhang, Kun Gai, Shuicheng Yan, Hao Fei, Tat-Seng Chua
分类: cs.CV, cs.AI
发布日期: 2025-03-31 (更新: 2025-12-12)
备注: Project Page: https://sqwu.top/Any2Cap/
💡 一句话要点
Any2Caption:提出一种条件可控的视频生成框架,通过多模态大语言模型将任意条件转化为详细描述。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频生成 条件控制 多模态大语言模型 指令调优 Any2CapIns数据集
📋 核心要点
- 现有视频生成方法在准确理解用户意图方面存在瓶颈,难以实现精细化的条件控制。
- Any2Caption通过多模态大语言模型将各种输入条件转化为详细的结构化描述,解耦条件理解和视频合成。
- Any2Caption在可控性和视频质量方面均有显著提升,并构建了大规模Any2CapIns数据集用于指令调优。
📝 摘要(中文)
为了解决当前视频生成领域中精确用户意图理解的瓶颈,我们提出了Any2Caption,这是一个新颖的框架,用于在任何条件下进行可控视频生成。其核心思想是将各种条件解释步骤与视频合成步骤解耦。通过利用现代多模态大型语言模型(MLLM),Any2Caption将各种输入(文本、图像、视频以及区域、运动和相机姿势等专业线索)解释为密集的、结构化的描述,从而为骨干视频生成器提供更好的指导。我们还引入了Any2CapIns,这是一个大规模数据集,包含337K个实例和407K个条件,用于任何条件到描述的指令调优。全面的评估表明,我们的系统在现有视频生成模型的各个方面的可控性和视频质量方面都有显著提高。
🔬 方法详解
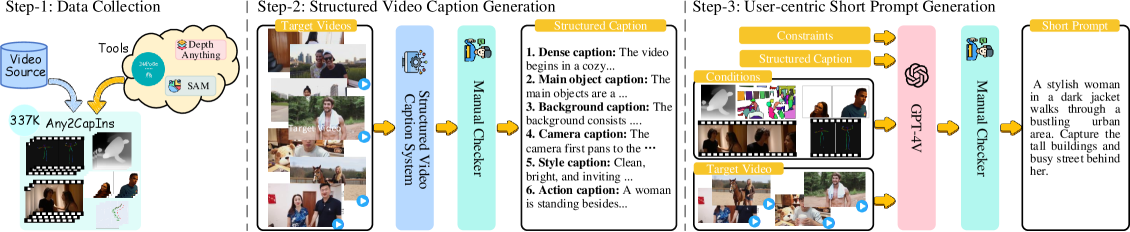
问题定义:当前视频生成模型难以准确理解用户通过各种条件(如文本、图像、视频、区域、运动等)表达的意图,导致生成结果与用户期望不符,缺乏精细的可控性。现有方法通常将条件理解和视频生成耦合在一起,难以针对不同类型的条件进行优化。
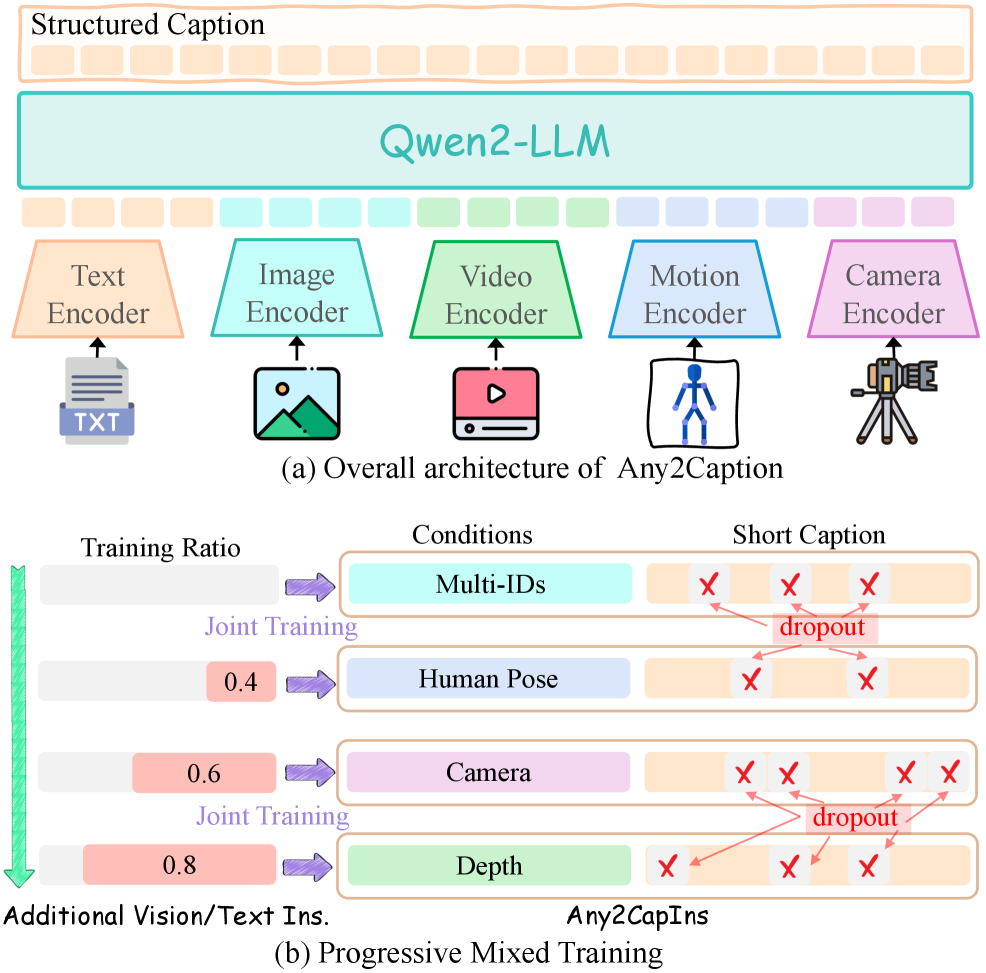
核心思路:Any2Caption的核心思路是将条件理解和视频生成解耦。利用多模态大语言模型(MLLM)强大的理解和生成能力,将各种复杂的输入条件转化为详细的、结构化的文本描述(caption),然后将这些描述作为视频生成器的输入,从而实现更精确的条件控制。这种解耦的设计使得可以独立地优化条件理解和视频生成两个模块。
技术框架:Any2Caption框架主要包含两个阶段:条件理解阶段和视频生成阶段。在条件理解阶段,使用多模态大语言模型(MLLM)将各种输入条件(文本、图像、视频等)转化为详细的文本描述。MLLM接收输入条件,并生成包含场景、对象、动作等信息的结构化描述。在视频生成阶段,使用现有的视频生成模型,例如基于扩散模型的模型,将MLLM生成的文本描述作为输入,生成相应的视频。
关键创新:Any2Caption的关键创新在于利用多模态大语言模型(MLLM)进行条件理解,并将条件理解和视频生成解耦。与直接将条件输入到视频生成器相比,Any2Caption通过MLLM将条件转化为更丰富、更结构化的描述,从而为视频生成器提供更明确的指导。此外,Any2CapIns数据集的构建也为训练和评估Any2Caption模型提供了支持。
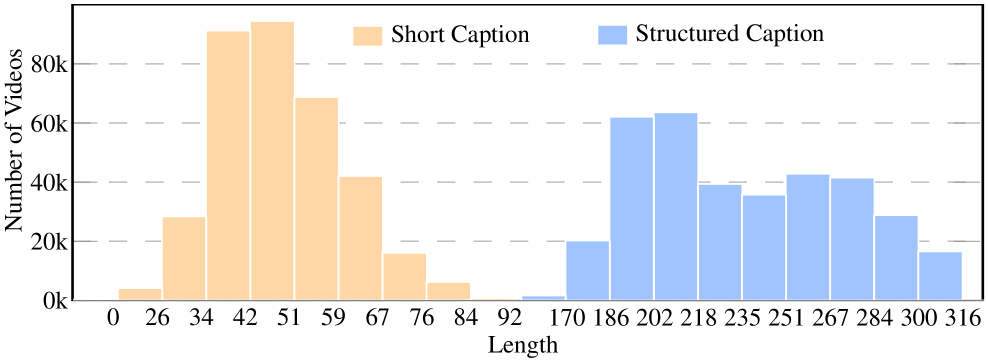
关键设计:Any2Caption的关键设计包括:1) 选择合适的多模态大语言模型(MLLM),并进行指令调优,使其能够准确地理解各种输入条件并生成详细的描述。2) 设计合适的描述结构,使其能够包含场景、对象、动作等关键信息,并能够被视频生成器有效利用。3) 构建大规模Any2CapIns数据集,用于训练和评估Any2Caption模型。数据集包含多种类型的输入条件和对应的描述,以及生成的视频。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Any2Caption在可控性和视频质量方面均优于现有方法。通过将Any2Caption应用于现有的视频生成模型,例如基于扩散模型的模型,可以显著提高生成视频的质量和与输入条件的一致性。Any2CapIns数据集的构建也为Any2Caption的训练和评估提供了重要支持。
🎯 应用场景
Any2Caption可应用于各种需要条件控制的视频生成场景,例如:根据文本描述生成视频、根据图像生成视频、根据视频片段生成后续视频、根据用户指定的区域、运动轨迹等生成视频。该技术可用于电影制作、游戏开发、广告设计、教育等领域,具有广泛的应用前景。
📄 摘要(原文)
To address the bottleneck of accurate user intent interpretation within the current video generation community, we present Any2Caption, a novel framework for controllable video generation under any condition. The key idea is to decouple various condition interpretation steps from the video synthesis step. By leveraging modern multimodal large language models (MLLMs), Any2Caption interprets diverse inputs--text, images, videos, and specialized cues such as region, motion, and camera poses--into dense, structured captions that offer backbone video generators with better guidance. We also introduce Any2CapIns, a large-scale dataset with 337K instances and 407K conditions for any-condition-to-caption instruction tuning. Comprehensive evaluations demonstrate significant improvements of our system in controllability and video quality across various aspects of existing video generation models. Project Page: https://sqwu.top/Any2Cap/