Exploring the Effect of Reinforcement Learning on Video Understanding: Insights from SEED-Bench-R1
作者: Yi Chen, Yuying Ge, Rui Wang, Yixiao Ge, Lu Qiu, Ying Shan, Xihui Liu
分类: cs.CV, cs.AI, cs.CL, cs.LG
发布日期: 2025-03-31
备注: Technical Report (In Progress); Code released at: https://github.com/TencentARC/SEED-Bench-R1
💡 一句话要点
SEED-Bench-R1:探索强化学习在视频理解多模态大模型后训练中的有效性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频理解 多模态大语言模型 强化学习 后训练 基准测试 泛化能力 视觉感知 逻辑推理
📋 核心要点
- 多模态大语言模型在感知和逻辑推理结合的任务中潜力巨大,但后训练方法的研究尚不充分。
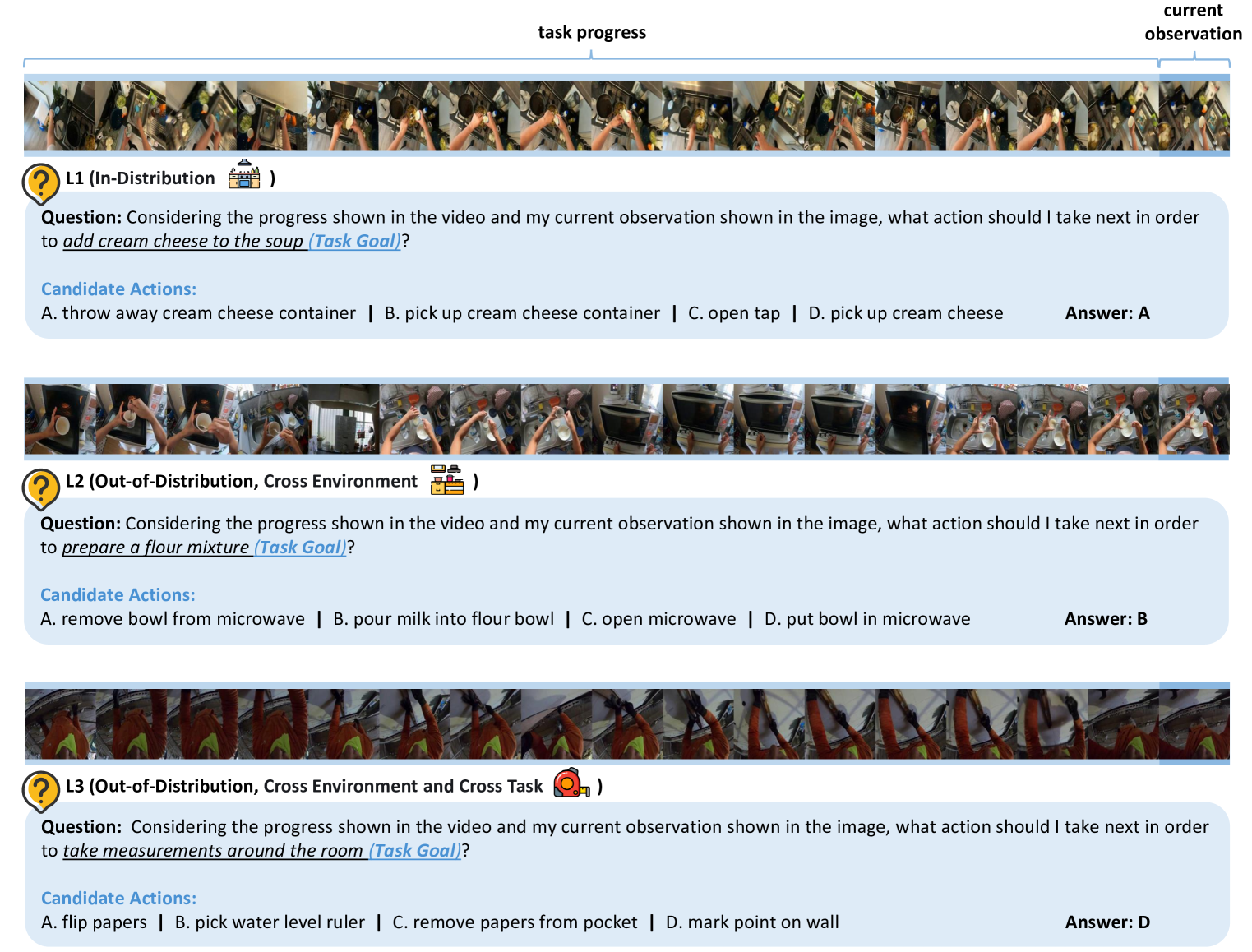
- 论文提出SEED-Bench-R1基准,用于系统评估MLLM在视频理解任务中后训练方法的有效性,侧重复杂推理和泛化能力。
- 实验表明,强化学习在视频理解任务中,相比监督微调,具有更高的数据效率和更好的泛化性能,尤其是在异分布场景下。
📝 摘要(中文)
本文提出了SEED-Bench-R1,一个旨在系统评估多模态大语言模型(MLLM)在视频理解中后训练方法的基准。该基准包含复杂的真实世界视频和日常规划任务,以多项选择题的形式呈现,需要模型具备精细的感知和推理能力。SEED-Bench-R1通过三级层次结构评估泛化能力:同分布、跨环境和跨环境-任务场景,并配备了大规模的、易于验证的ground-truth答案的训练数据集。使用Qwen2-VL-Instruct-7B作为基础模型,论文比较了强化学习(RL)与监督微调(SFT),结果表明RL在数据效率和同分布及异分布任务的性能上均优于SFT,甚至在通用视频理解基准(如LongVideoBench)上也超越了SFT。详细分析表明,RL增强了视觉感知,但往往产生逻辑连贯性较差的推理链。论文指出了诸如推理不一致和忽略视觉线索等关键局限性,并建议未来改进基础模型的推理能力、奖励建模以及RL对噪声信号的鲁棒性。
🔬 方法详解
问题定义:现有的大语言模型(LLM)在思维链(COT)生成方面取得了显著进展,但多模态大语言模型(MLLM)在需要感知和逻辑推理的任务中仍有待探索。现有的视频理解基准可能无法充分评估MLLM的推理能力和泛化能力,尤其是在复杂的真实世界场景中。
核心思路:论文的核心思路是通过构建一个专门的基准测试集SEED-Bench-R1,来系统地评估MLLM在视频理解任务中,使用强化学习(RL)进行后训练的效果。通过设计具有挑战性的视频理解任务和评估不同泛化场景,来揭示RL在提升MLLM感知和推理能力方面的潜力和局限性。
技术框架:整体框架包括以下几个关键部分:1) 构建SEED-Bench-R1基准测试集,包含真实世界视频和复杂的日常规划任务,以多项选择题形式呈现。2) 使用Qwen2-VL-Instruct-7B作为基础模型。3) 对基础模型进行强化学习(RL)后训练。4) 在SEED-Bench-R1上评估RL后训练模型的性能,并与监督微调(SFT)进行比较。5) 在通用视频理解基准(如LongVideoBench)上进行评估。
关键创新:该论文的关键创新在于:1) 提出了SEED-Bench-R1基准测试集,专门用于评估MLLM在视频理解任务中的后训练方法,特别是强化学习。2) 系统地比较了强化学习和监督微调在视频理解任务中的性能,揭示了RL在数据效率和泛化能力方面的优势。3) 对RL在视频理解中的局限性进行了深入分析,并提出了未来改进方向。
关键设计:SEED-Bench-R1基准测试集包含三个层次的泛化能力评估:同分布、跨环境和跨环境-任务。奖励建模的具体细节(例如,如何设计奖励函数来鼓励模型生成逻辑连贯的推理链)未知。强化学习算法的具体选择(例如,PPO、DQN等)未知。论文中使用了Qwen2-VL-Instruct-7B作为基础模型,这是一个70亿参数的视觉语言模型。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在SEED-Bench-R1基准测试集上,强化学习(RL)后训练的MLLM在同分布和异分布任务上的性能均优于监督微调(SFT)。此外,RL模型在通用视频理解基准LongVideoBench上也超越了SFT模型,验证了RL在提升视频理解能力方面的有效性。具体性能提升数据未知。
🎯 应用场景
该研究成果可应用于智能视频分析、机器人导航、智能家居等领域。通过强化学习提升多模态大语言模型在视频理解方面的能力,可以使机器更好地理解真实世界的视频内容,从而实现更智能化的决策和行为。未来的影响包括提升机器人在复杂环境中的适应性和交互能力。
📄 摘要(原文)
Recent advancements in Chain of Thought (COT) generation have significantly improved the reasoning capabilities of Large Language Models (LLMs), with reinforcement learning (RL) emerging as an effective post-training approach. Multimodal Large Language Models (MLLMs) inherit this reasoning potential but remain underexplored in tasks requiring both perception and logical reasoning. To address this, we introduce SEED-Bench-R1, a benchmark designed to systematically evaluate post-training methods for MLLMs in video understanding. It includes intricate real-world videos and complex everyday planning tasks in the format of multiple-choice questions, requiring sophisticated perception and reasoning. SEED-Bench-R1 assesses generalization through a three-level hierarchy: in-distribution, cross-environment, and cross-environment-task scenarios, equipped with a large-scale training dataset with easily verifiable ground-truth answers. Using Qwen2-VL-Instruct-7B as a base model, we compare RL with supervised fine-tuning (SFT), demonstrating RL's data efficiency and superior performance on both in-distribution and out-of-distribution tasks, even outperforming SFT on general video understanding benchmarks like LongVideoBench. Our detailed analysis reveals that RL enhances visual perception but often produces less logically coherent reasoning chains. We identify key limitations such as inconsistent reasoning and overlooked visual cues, and suggest future improvements in base model reasoning, reward modeling, and RL robustness against noisy signals.