Style Quantization for Data-Efficient GAN Training
作者: Jian Wang, Xin Lan, Jizhe Zhou, Yuxin Tian, Jiancheng Lv
分类: cs.CV
发布日期: 2025-03-31
💡 一句话要点
提出SQ-GAN,通过风格量化提升数据稀缺场景下的GAN训练效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 生成对抗网络 数据高效学习 风格量化 一致性正则化 最优传输 图像生成 潜在空间学习
📋 核心要点
- 在数据量有限的情况下,GAN难以充分利用潜在空间,导致生成图像质量不稳定,一致性正则化效果不佳。
- SQ-GAN通过风格空间量化,将连续潜在空间转化为离散代理空间,使每个码字对应一个真实数据点,从而提升一致性正则化效果。
- 实验结果表明,SQ-GAN显著提升了鉴别器的鲁棒性和生成图像的质量,验证了该方法的有效性。
📝 摘要(中文)
在数据有限的情况下,GAN通常难以有效探索和利用输入潜在空间。这导致从稀疏潜在空间中相邻变量生成的图像在真实感上存在显著差异,从而影响一致性正则化(CR)的效果。为了解决这个问题,我们提出了一种新的方法SQ-GAN,通过引入风格空间量化方案来增强CR。该方法将稀疏、连续的输入潜在空间转换为紧凑、结构化的离散代理空间,使每个元素对应于一个特定的真实数据点,从而提高CR性能。我们没有直接量化,而是首先将输入潜在变量映射到一个解耦的“风格”空间,并使用可学习的码本进行量化。这使得每个量化的代码能够控制不同的变异因素。此外,我们优化最优传输距离,以对齐码本代码与由基础模型从训练数据中提取的特征,将外部知识嵌入到码本中,并建立一个语义丰富的词汇表,准确地描述训练数据集。大量实验表明,我们的方法在鉴别器鲁棒性和生成质量方面都有显著提高。
🔬 方法详解
问题定义:在数据量有限的情况下,GAN的训练面临挑战,尤其是在探索和利用潜在空间方面。由于潜在空间的稀疏性,相邻潜在变量生成的图像可能在真实感上存在很大差异,导致传统的一致性正则化方法效果不佳。现有方法难以在有限数据下建立潜在空间与生成图像之间的稳定映射关系。
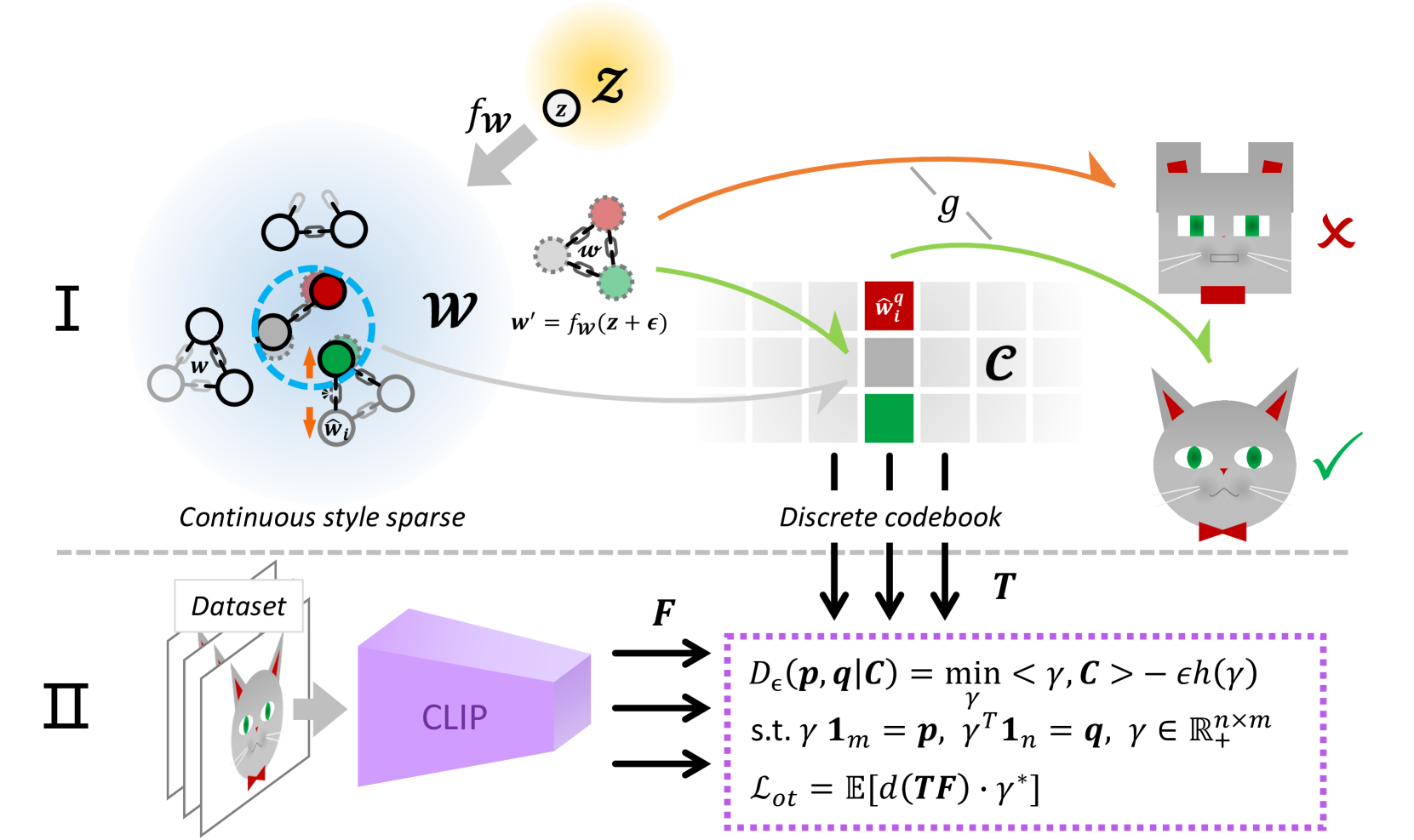
核心思路:SQ-GAN的核心思路是将连续的潜在空间通过风格空间量化转化为离散的代理空间。通过学习一个码本,将潜在变量映射到风格空间中的离散码字,每个码字代表一种特定的风格。这种量化过程使得相邻的潜在变量更有可能映射到相似的风格,从而提高生成图像的一致性,并增强一致性正则化的效果。
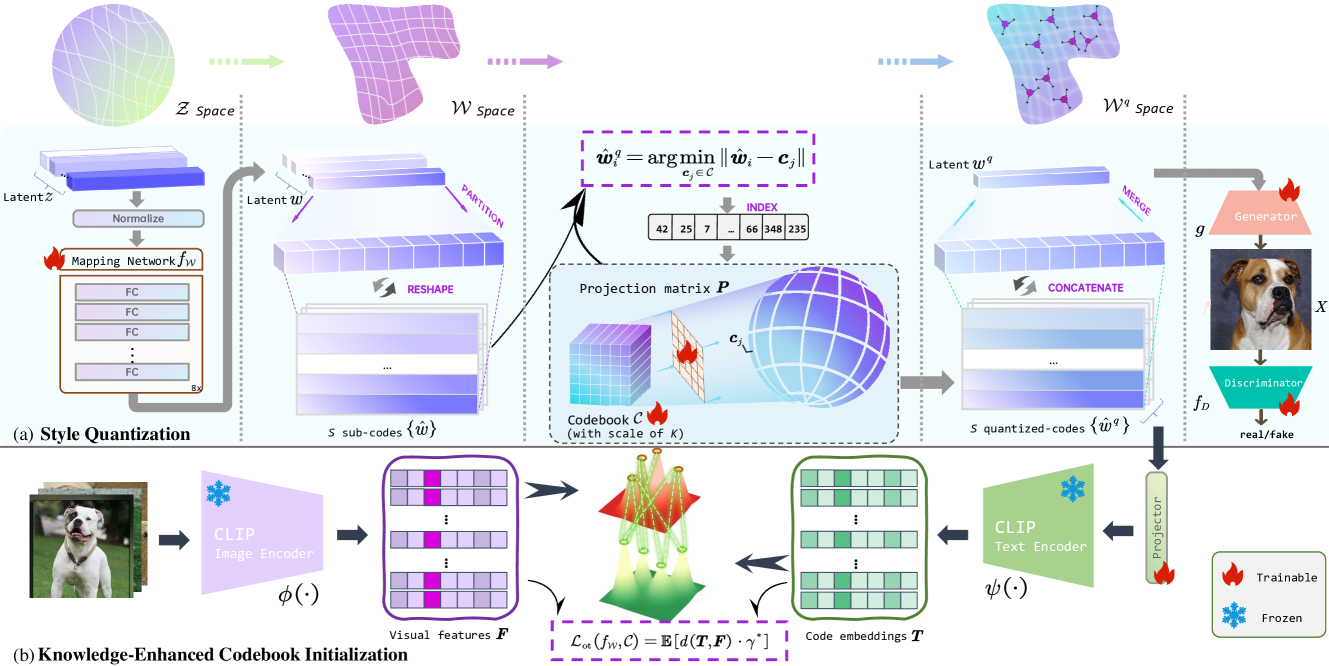
技术框架:SQ-GAN的整体框架包括以下几个主要模块:1) 潜在变量编码器:将输入潜在变量映射到风格空间。2) 风格空间量化器:使用可学习的码本对风格空间进行量化,将风格向量映射到离散的码字。3) 生成器:根据量化后的码字生成图像。4) 鉴别器:判断生成图像的真伪。此外,还使用了最优传输损失来对齐码本代码与训练数据特征,以嵌入外部知识。
关键创新:SQ-GAN的关键创新在于引入了风格空间量化。与直接量化潜在空间相比,风格空间量化能够更好地解耦不同的变异因素,使得每个码字控制特定的风格属性。此外,通过最优传输损失将外部知识嵌入到码本中,使得码本能够更好地描述训练数据集的特征。
关键设计:SQ-GAN的关键设计包括:1) 可学习的码本:码本中的每个码字代表一种风格,通过训练学习得到。2) 最优传输损失:用于对齐码本代码与训练数据特征,确保码本能够捕捉到训练数据的关键信息。3) 风格空间:通过编码器将潜在变量映射到风格空间,该空间的设计旨在解耦不同的变异因素。4) 一致性正则化:利用量化后的风格空间,提升一致性正则化的效果。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SQ-GAN在数据稀缺的场景下,显著提升了GAN的生成性能。与基线方法相比,SQ-GAN在FID指标上取得了显著的改进,表明生成图像的质量和多样性得到了有效提升。此外,SQ-GAN还提高了鉴别器的鲁棒性,使得GAN的训练更加稳定。
🎯 应用场景
SQ-GAN在数据稀缺的图像生成任务中具有广泛的应用前景,例如人脸生成、艺术风格迁移、医学图像合成等。该方法可以有效提升生成图像的质量和多样性,尤其是在训练数据有限的情况下。此外,通过嵌入外部知识,SQ-GAN还可以用于生成具有特定属性的图像,例如生成特定年龄、性别或表情的人脸图像。
📄 摘要(原文)
Under limited data setting, GANs often struggle to navigate and effectively exploit the input latent space. Consequently, images generated from adjacent variables in a sparse input latent space may exhibit significant discrepancies in realism, leading to suboptimal consistency regularization (CR) outcomes. To address this, we propose \textit{SQ-GAN}, a novel approach that enhances CR by introducing a style space quantization scheme. This method transforms the sparse, continuous input latent space into a compact, structured discrete proxy space, allowing each element to correspond to a specific real data point, thereby improving CR performance. Instead of direct quantization, we first map the input latent variables into a less entangled ``style'' space and apply quantization using a learnable codebook. This enables each quantized code to control distinct factors of variation. Additionally, we optimize the optimal transport distance to align the codebook codes with features extracted from the training data by a foundation model, embedding external knowledge into the codebook and establishing a semantically rich vocabulary that properly describes the training dataset. Extensive experiments demonstrate significant improvements in both discriminator robustness and generation quality with our method.