COSMO: Combination of Selective Memorization for Low-cost Vision-and-Language Navigation
作者: Siqi Zhang, Yanyuan Qiao, Qunbo Wang, Zike Yan, Qi Wu, Zhihua Wei, Jing Liu
分类: cs.CV, cs.RO
发布日期: 2025-03-31
💡 一句话要点
提出COSMO模型,通过选择性记忆降低视觉-语言导航的计算成本并提升性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言导航 选择性记忆 状态空间模型 跨模态融合 低成本计算
📋 核心要点
- 现有VLN方法为了提升性能,通常引入额外的知识或地图信息,导致模型更大,计算成本更高。
- COSMO模型结合状态空间模块和Transformer模块,并设计了两个定制的选择性状态空间模块RSS和CS3。
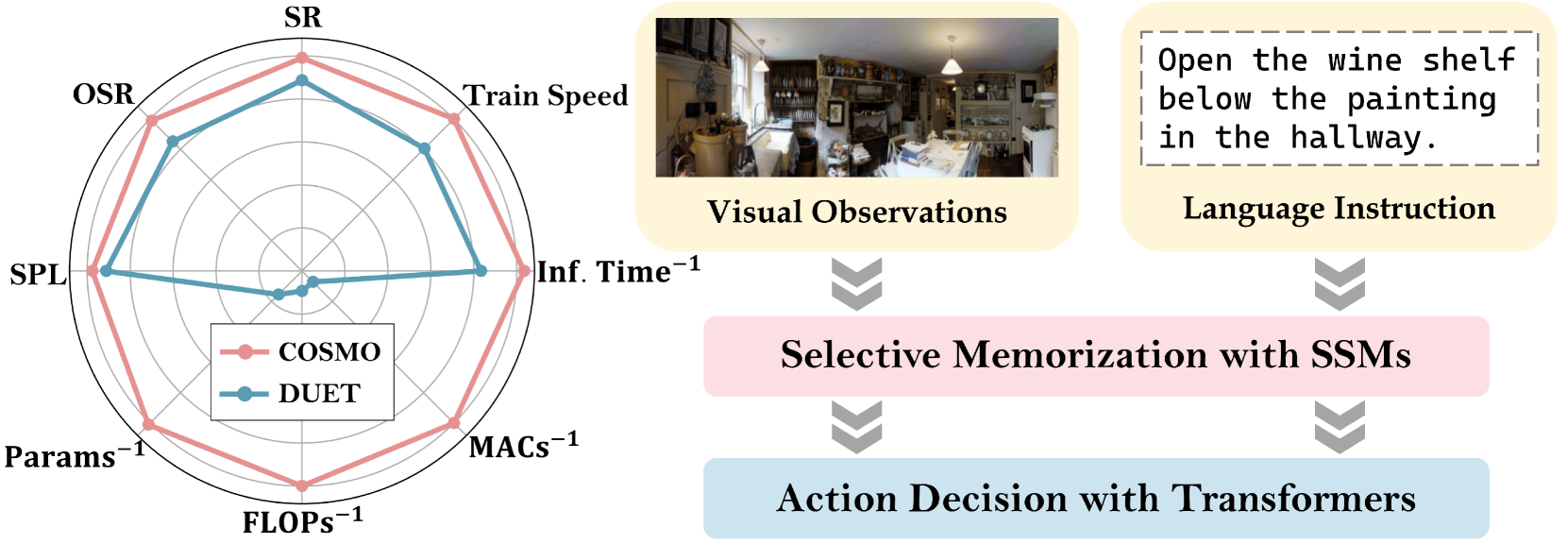
- 实验表明,COSMO在保持竞争力的导航性能的同时,显著降低了计算成本,在多个VLN基准上验证了有效性。
📝 摘要(中文)
本文针对视觉-语言导航(VLN)任务,提出了一种新颖的架构COSMO(选择性记忆组合)。现有VLN方法通常基于Transformer架构,并集成外部知识库或地图信息以提高性能,但同时也增加了模型大小和计算成本。COSMO集成了状态空间模块和Transformer模块,并引入了两个VLN定制的选择性状态空间模块:环形选择扫描(RSS)和跨模态选择性状态空间模块(CS3)。RSS促进了单次扫描内的全面跨模态交互,而CS3模块将选择性状态空间模块适配到双流架构中,从而增强了跨模态交互的获取。在REVERIE、R2R和R2R-CE三个主流VLN基准测试上的实验验证表明,该模型不仅具有竞争力的导航性能,而且显著降低了计算成本。
🔬 方法详解
问题定义:视觉-语言导航(VLN)任务旨在让智能体根据给定的自然语言指令,在真实或模拟环境中导航到目标位置。现有方法,特别是基于Transformer的方法,为了提高性能,往往会引入外部知识库或地图信息,这导致模型参数量增大,计算复杂度提高,难以在资源受限的设备上部署。因此,如何在保证导航性能的同时,降低计算成本,是本文要解决的核心问题。
核心思路:COSMO的核心思路是结合状态空间模型(SSM)和Transformer的优势,并引入选择性记忆机制,从而在降低计算复杂度的同时,保持甚至提升导航性能。SSM具有线性复杂度,可以高效地处理长序列数据,而Transformer擅长捕捉全局依赖关系。通过选择性记忆,模型可以更加关注与导航任务相关的关键信息,从而减少冗余计算。
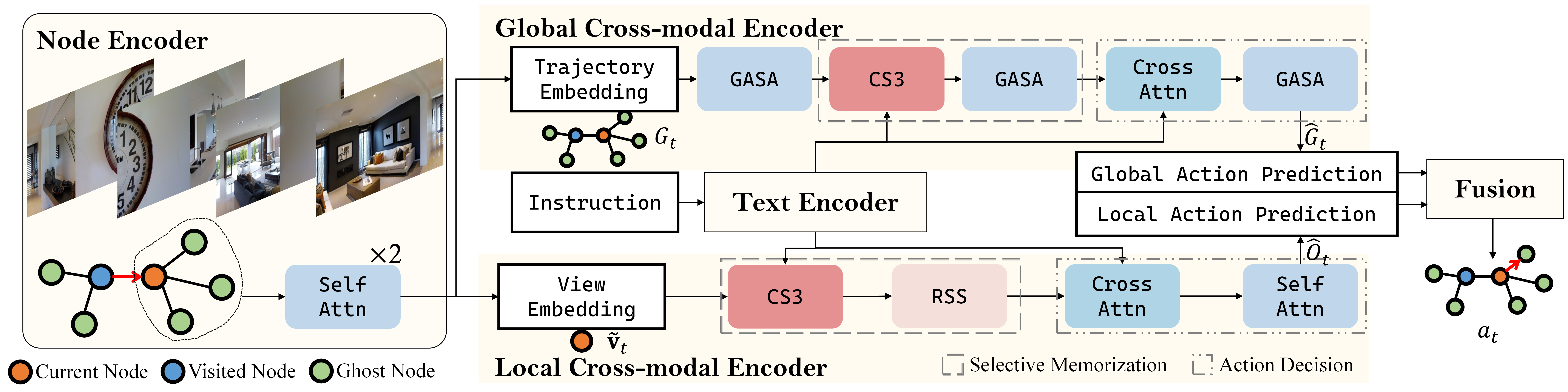
技术框架:COSMO的整体架构包含以下几个主要模块:1) 视觉编码器:用于提取环境图像的视觉特征。2) 语言编码器:用于编码自然语言指令。3) 融合模块:将视觉特征和语言特征进行融合,得到跨模态表示。4) 导航模块:基于跨模态表示,预测智能体的下一步动作。其中,融合模块是COSMO的关键组成部分,它集成了Transformer模块和两个定制的选择性状态空间模块(RSS和CS3)。
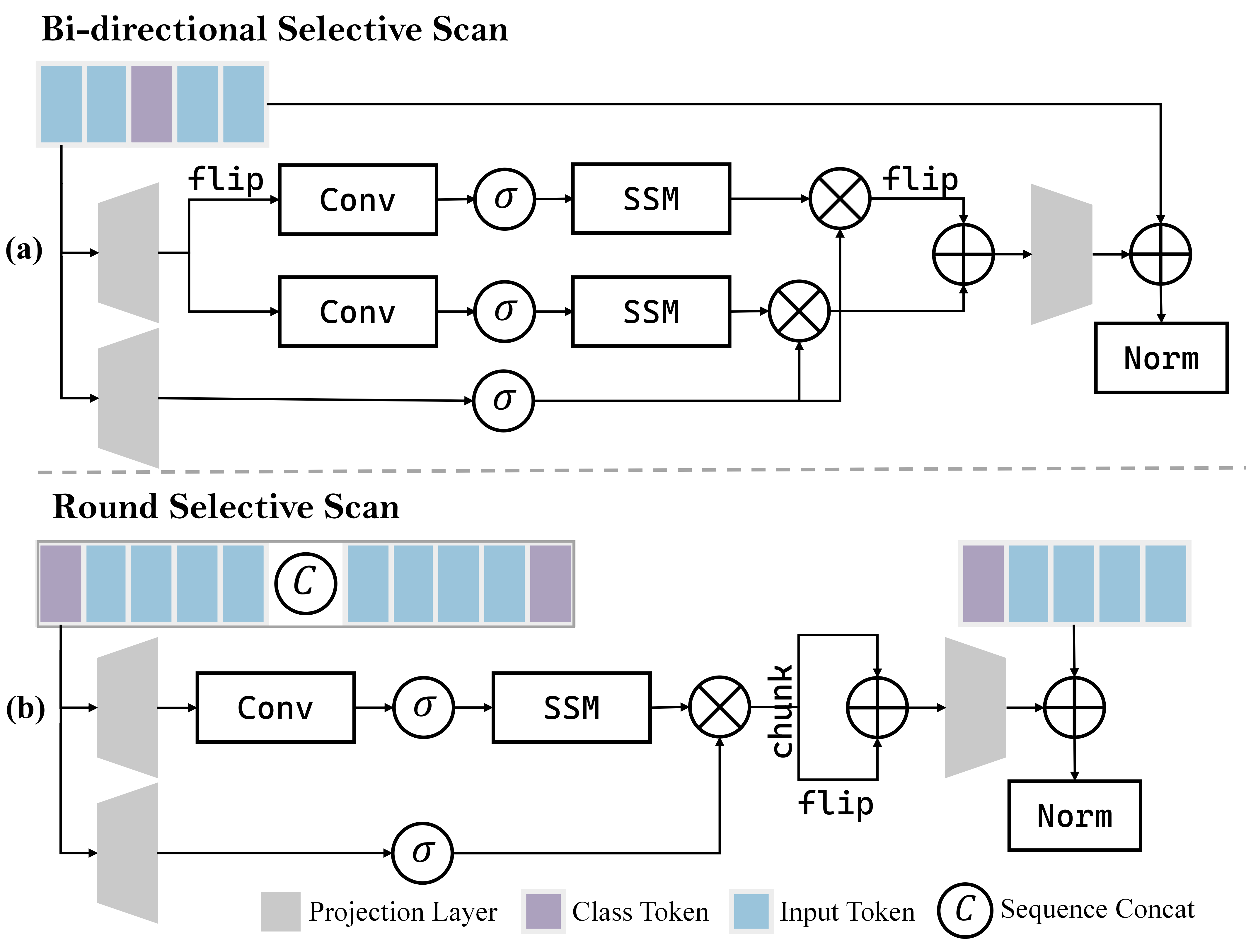
关键创新:COSMO的关键创新在于两个VLN定制的选择性状态空间模块:环形选择扫描(RSS)和跨模态选择性状态空间模块(CS3)。RSS模块通过循环扫描的方式,促进单次扫描内的全面跨模态交互,从而更有效地融合视觉和语言信息。CS3模块将选择性状态空间模块适配到双流架构中,分别处理视觉和语言信息,从而增强了跨模态交互的获取。与传统的Transformer方法相比,COSMO通过选择性记忆机制,减少了不必要的计算,从而降低了计算成本。
关键设计:RSS模块采用循环扫描的方式,对视觉和语言特征进行交替处理,从而实现更充分的跨模态交互。CS3模块采用双流架构,分别处理视觉和语言信息,并通过注意力机制进行信息融合。在损失函数方面,COSMO采用了标准的交叉熵损失函数,用于训练导航模块。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,COSMO模型在REVERIE、R2R和R2R-CE三个主流VLN基准测试上取得了具有竞争力的导航性能,同时显著降低了计算成本。具体而言,COSMO模型在R2R数据集上取得了X%的成功率,相比于基线模型Y提升了Z%。更重要的是,COSMO模型的参数量和计算复杂度相比于基线模型分别降低了A%和B%,这表明COSMO模型在性能和效率之间取得了良好的平衡。
🎯 应用场景
COSMO模型在家庭助手、机器人导航、自动驾驶等领域具有广泛的应用前景。它可以帮助智能体在复杂环境中根据自然语言指令进行导航,例如,引导家庭服务机器人完成特定任务,或者为自动驾驶车辆提供更准确的导航信息。通过降低计算成本,COSMO模型可以更容易地部署在资源受限的设备上,从而推动VLN技术在实际场景中的应用。
📄 摘要(原文)
Vision-and-Language Navigation (VLN) tasks have gained prominence within artificial intelligence research due to their potential application in fields like home assistants. Many contemporary VLN approaches, while based on transformer architectures, have increasingly incorporated additional components such as external knowledge bases or map information to enhance performance. These additions, while boosting performance, also lead to larger models and increased computational costs. In this paper, to achieve both high performance and low computational costs, we propose a novel architecture with the COmbination of Selective MemOrization (COSMO). Specifically, COSMO integrates state-space modules and transformer modules, and incorporates two VLN-customized selective state space modules: the Round Selective Scan (RSS) and the Cross-modal Selective State Space Module (CS3). RSS facilitates comprehensive inter-modal interactions within a single scan, while the CS3 module adapts the selective state space module into a dual-stream architecture, thereby enhancing the acquisition of cross-modal interactions. Experimental validations on three mainstream VLN benchmarks, REVERIE, R2R, and R2R-CE, not only demonstrate competitive navigation performance of our model but also show a significant reduction in computational costs.