Context-Independent OCR with Multimodal LLMs: Effects of Image Resolution and Visual Complexity
作者: Kotaro Inoue
分类: cs.CV
发布日期: 2025-03-31
💡 一句话要点
研究多模态LLM在上下文无关OCR中的图像分辨率和视觉复杂度影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态LLM 光学字符识别 图像分辨率 视觉复杂度 上下文无关OCR
📋 核心要点
- 多模态LLM在OCR任务中展现潜力,但其在不同图像条件下的性能尚不明确,尤其是在上下文无关的单字符识别方面。
- 该研究通过分析图像分辨率和视觉复杂度对多模态LLM在单字符OCR任务中性能的影响,探究其适用条件。
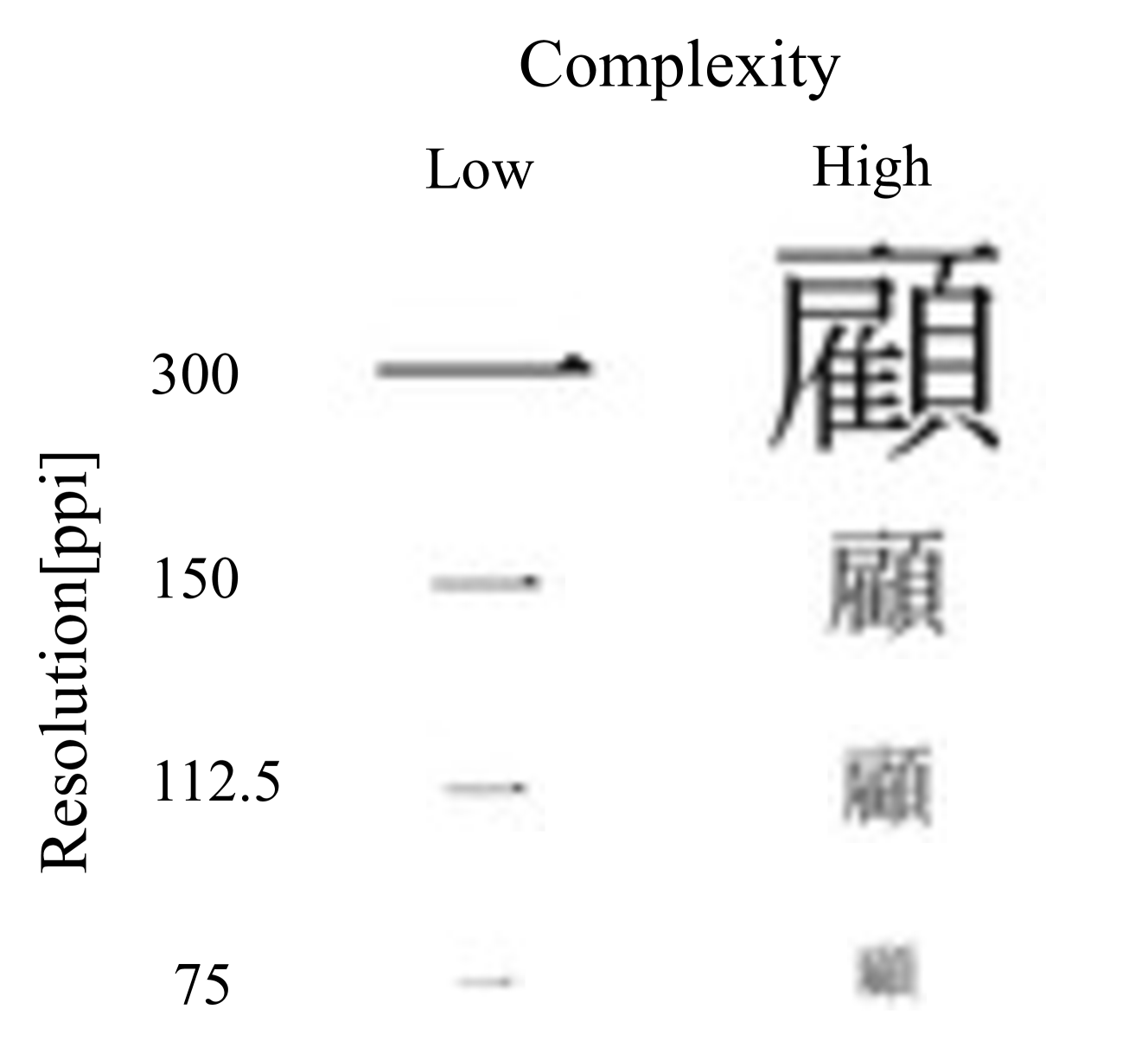
- 实验表明,多模态LLM在300 ppi时性能可与传统OCR方法媲美,但低于150 ppi时显著下降,且视觉复杂度影响较小。
📝 摘要(中文)
多模态大型语言模型(LLM)在图像描述、文档分析和自动内容生成等任务中表现出高度的通用性,受到了各个工业领域的广泛关注。尤其是在光学字符识别(OCR)方面,它们已经超越了专门的模型。然而,它们在不同图像条件下的性能仍未得到充分研究,并且由于依赖于上下文线索,无法保证单个字符的识别准确性。本文通过使用具有不同视觉复杂度的单字符图像,进行上下文无关的OCR任务,以确定准确识别的条件。研究结果表明,多模态LLM在大约300 ppi时可以与传统OCR方法相媲美,但当分辨率低于150 ppi时,其性能会显著下降。此外,我们观察到视觉复杂度和错误识别之间的相关性非常弱,而传统的OCR专用模型则没有相关性。这些结果表明,图像分辨率和视觉复杂度可能在多模态LLM可靠应用于需要精确字符级准确性的OCR任务中发挥重要作用。
🔬 方法详解
问题定义:论文旨在研究多模态LLM在上下文无关的OCR任务中的性能,特别是针对单字符图像的识别。现有方法,即传统OCR模型,可能在处理复杂视觉场景或低分辨率图像时表现不佳,而多模态LLM的性能受图像条件的影响程度尚不清楚。因此,需要确定多模态LLM在不同图像分辨率和视觉复杂度下的适用性。
核心思路:论文的核心思路是通过控制单字符图像的分辨率和视觉复杂度,系统地评估多模态LLM的OCR性能。通过分析不同条件下的识别准确率,揭示图像分辨率和视觉复杂度对多模态LLM性能的影响规律,从而确定其在上下文无关OCR任务中的适用范围。
技术框架:该研究采用实验方法,主要流程包括:1) 构建包含不同分辨率和视觉复杂度的单字符图像数据集;2) 使用多模态LLM和传统OCR模型对数据集进行OCR识别;3) 分析不同模型在不同图像条件下的识别准确率;4) 评估视觉复杂度和错误识别之间的相关性。
关键创新:该研究的关键创新在于系统性地研究了图像分辨率和视觉复杂度对多模态LLM在上下文无关OCR任务中性能的影响。以往的研究可能更多关注多模态LLM在复杂文档场景下的OCR性能,而忽略了单字符识别的精度问题。该研究关注单字符识别,并量化了图像分辨率和视觉复杂度的影响,为多模态LLM在OCR任务中的可靠应用提供了指导。
关键设计:研究中,图像分辨率被设置为多个离散值(例如,低于150 ppi,300 ppi),视觉复杂度通过某种图像处理算法进行量化(具体算法未知)。多模态LLM的具体选择未知,但需要具备图像输入和文本输出能力。评估指标为单字符识别准确率,以及视觉复杂度和错误识别之间的相关系数。
🖼️ 关键图片


📊 实验亮点
实验结果表明,多模态LLM在300 ppi左右的分辨率下,OCR性能可以与传统OCR方法相媲美。然而,当分辨率低于150 ppi时,多模态LLM的性能显著下降。此外,研究发现视觉复杂度和多模态LLM的错误识别之间存在非常弱的相关性,而传统OCR模型则没有相关性。这些结果强调了图像分辨率在多模态LLM应用于OCR任务中的重要性。
🎯 应用场景
该研究成果可应用于需要高精度字符识别的场景,例如自动驾驶中的交通标志识别、工业自动化中的零件编号识别、以及文档图像处理中的关键信息提取。通过了解多模态LLM在不同图像条件下的性能,可以更好地选择合适的OCR方案,提高系统的可靠性和准确性。未来,可以进一步研究如何优化多模态LLM以提高其在低分辨率和复杂视觉场景下的OCR性能。
📄 摘要(原文)
Due to their high versatility in tasks such as image captioning, document analysis, and automated content generation, multimodal Large Language Models (LLMs) have attracted significant attention across various industrial fields. In particular, they have been shown to surpass specialized models in Optical Character Recognition (OCR). Nevertheless, their performance under different image conditions remains insufficiently investigated, and individual character recognition is not guaranteed due to their reliance on contextual cues. In this work, we examine a context-independent OCR task using single-character images with diverse visual complexities to determine the conditions for accurate recognition. Our findings reveal that multimodal LLMs can match conventional OCR methods at about 300 ppi, yet their performance deteriorates significantly below 150 ppi. Additionally, we observe a very weak correlation between visual complexity and misrecognitions, whereas a conventional OCR-specific model exhibits no correlation. These results suggest that image resolution and visual complexity may play an important role in the reliable application of multimodal LLMs to OCR tasks that require precise character-level accuracy.