BoundMatch: Boundary detection applied to semi-supervised segmentation
作者: Haruya Ishikawa, Yoshimitsu Aoki
分类: cs.CV
发布日期: 2025-03-30 (更新: 2025-09-30)
备注: 24 pages, 23 figures, to be published to IEEE Access
💡 一句话要点
BoundMatch:提出一种结合边界检测的半监督语义分割框架,提升分割精度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 半监督学习 语义分割 边界检测 一致性正则化 多任务学习
📋 核心要点
- 现有半监督语义分割方法缺乏对边界信息的显式建模,导致分割精度受限。
- BoundMatch通过引入边界检测任务,并采用教师-学生一致性正则化,显式地学习和利用边界信息。
- 实验表明,BoundMatch在Cityscapes等数据集上取得了有竞争力的性能,尤其在使用DINOv2时达到了SOTA。
📝 摘要(中文)
半监督语义分割(SS-SS)旨在通过利用大量未标记图像和少量标记图像来减轻密集像素标记的繁重标注负担。虽然目前的置信度正则化方法取得了显著成果,但大多数方法没有将边界作为单独的学习目标进行显式建模。本文提出BoundMatch,一种新颖的多任务SS-SS框架,将语义边界检测显式集成到教师-学生一致性正则化流程中。我们的核心机制,边界一致性正则化多任务学习(BCRM),强制教师和学生模型在分割掩码和详细语义边界上达成预测一致,从而提供来自两个独立任务的互补监督。为了进一步提高性能并鼓励更清晰的边界,BoundMatch包含两个轻量级融合模块:边界-语义融合(BSF)将学习到的边界线索注入到分割解码器中,而空间梯度融合(SGF)使用掩码梯度细化边界预测,从而产生更可靠的边界伪标签。该框架建立在SAMTH之上,这是一个强大的教师-学生基线,具有用于提高稳定性的和谐批归一化(HBN)更新策略。在包括Cityscapes和Pascal VOC在内的各种数据集上的大量实验表明,BoundMatch相对于当前最先进的方法取得了有竞争力的性能。我们的方法在使用DINOv2基础模型的新Cityscapes基准上取得了最先进的结果。消融研究突出了BoundMatch提高边界特定评估指标的能力,其在现实的大规模未标记数据场景中的有效性,以及对移动部署的轻量级架构的适用性。
🔬 方法详解
问题定义:半监督语义分割旨在利用少量标注数据和大量无标注数据来训练分割模型,以降低标注成本。现有方法通常侧重于像素级别的置信度一致性,忽略了图像边界信息的重要性。边界模糊会导致分割精度下降,尤其是在复杂场景中。
核心思路:BoundMatch的核心思路是将语义边界检测作为一个辅助任务,与语义分割任务联合训练。通过在教师模型和学生模型之间强制执行边界预测的一致性,可以提高模型对边界的感知能力,从而改善分割效果。同时,利用边界信息反过来指导语义分割,形成互补监督。
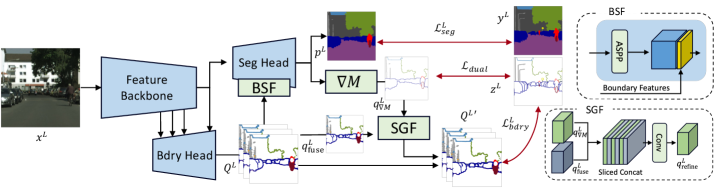
技术框架:BoundMatch建立在教师-学生模型的框架之上。首先,使用标注数据训练教师模型。然后,利用教师模型对无标注数据进行预测,生成分割伪标签和边界伪标签。学生模型同时学习分割任务和边界检测任务,并与教师模型的预测结果进行一致性约束。框架包含三个主要模块:分割模块、边界检测模块和一致性正则化模块。此外,还包含边界-语义融合(BSF)和空间梯度融合(SGF)两个模块来增强边界信息。
关键创新:BoundMatch的关键创新在于显式地将边界检测任务引入半监督语义分割框架,并设计了边界一致性正则化方法。通过多任务学习和一致性约束,模型能够更好地学习和利用边界信息,从而提高分割精度。此外,BSF和SGF模块进一步增强了边界信息的利用。
关键设计:BoundMatch使用了边界一致性正则化损失函数,用于约束教师模型和学生模型在边界预测上的差异。具体来说,该损失函数计算教师模型和学生模型预测的边界概率图之间的交叉熵损失。BSF模块将边界特征图与分割特征图进行融合,以增强分割解码器对边界信息的感知。SGF模块利用分割掩码的梯度来细化边界预测结果,从而生成更准确的边界伪标签。
🖼️ 关键图片


📊 实验亮点
BoundMatch在Cityscapes数据集上取得了显著的性能提升,尤其是在使用DINOv2作为基础模型时,达到了state-of-the-art水平。消融实验表明,边界一致性正则化、边界-语义融合和空间梯度融合等模块均对性能提升有贡献。此外,该方法在处理大规模无标注数据时表现出良好的鲁棒性,并且适用于轻量级网络架构。
🎯 应用场景
BoundMatch在自动驾驶、医学图像分析、遥感图像处理等领域具有广泛的应用前景。在这些领域中,获取高质量的标注数据成本高昂,而BoundMatch能够有效利用大量无标注数据,提高分割精度,降低标注成本。该方法还可以应用于移动端设备,实现轻量级的语义分割。
📄 摘要(原文)
Semi-supervised semantic segmentation (SS-SS) aims to mitigate the heavy annotation burden of dense pixel labeling by leveraging abundant unlabeled images alongside a small labeled set. While current consistency regularization methods achieve strong results, most do not explicitly model boundaries as a separate learning objective. In this paper, we propose BoundMatch, a novel multi-task SS-SS framework that explicitly integrates semantic boundary detection into a teacher-student consistency regularization pipeline. Our core mechanism, Boundary Consistency Regularized Multi-Task Learning (BCRM), enforces prediction agreement between teacher and student models on both segmentation masks and detailed semantic boundaries, providing complementary supervision from two independent tasks. To further enhance performance and encourage sharper boundaries, BoundMatch incorporates two lightweight fusion modules: Boundary-Semantic Fusion (BSF) injects learned boundary cues into the segmentation decoder, while Spatial Gradient Fusion (SGF) refines boundary predictions using mask gradients, yielding more reliable boundary pseudo-labels. This framework is built upon SAMTH, a strong teacher-student baseline featuring a Harmonious Batch Normalization (HBN) update strategy for improved stability. Extensive experiments on diverse datasets including Cityscapes and Pascal VOC show that BoundMatch achieves competitive performance against current state-of-the-art methods. Our approach achieves state-of-the-art results on the new Cityscapes benchmark with DINOv2 foundation model. Ablation studies highlight BoundMatch's ability to improve boundary-specific evaluation metrics, its effectiveness in realistic large-scale unlabeled data scenario, and applicability to lightweight architectures for mobile deployment.