KernelDNA: Dynamic Kernel Sharing via Decoupled Naive Adapters
作者: Haiduo Huang, Yadong Zhang, Yinghui Xu, Pengju Ren
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-03-30 (更新: 2025-11-16)
💡 一句话要点
KernelDNA:通过解耦的朴素适配器实现动态卷积核共享,提升效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 动态卷积 卷积神经网络 模型压缩 适配器 权重共享
📋 核心要点
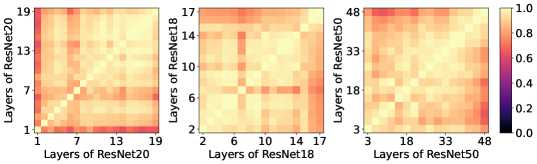
- 现有动态卷积方法在参数效率、推理速度和联合优化方面存在不足,限制了模型性能。
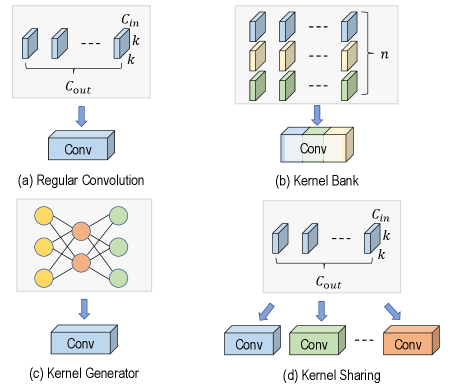
- KernelDNA通过解耦动态路由和静态调制,利用跨层权重共享和适配器,实现高效的动态卷积核调整。
- 实验表明,KernelDNA在图像分类和密集预测任务上,实现了精度和效率之间的最佳平衡。
📝 摘要(中文)
动态卷积通过自适应地组合多个卷积核来增强模型容量,但面临着关键的权衡:现有方法要么(1)通过线性扩展卷积核数量而产生显著的参数开销,要么(2)通过复杂的卷积核交互而降低推理速度,要么(3)难以联合优化动态注意力机制和静态卷积核。我们观察到,预训练的卷积神经网络(CNN)表现出层间冗余,类似于大型语言模型(LLM)中的冗余。具体来说,密集的卷积层可以有效地被派生的“子”层所取代,这些“子”层通过适配器从共享的“父”卷积核生成。为了解决这些限制并实现权重共享机制,我们提出了一种轻量级的卷积核插件,名为KernelDNA。它将卷积核适配解耦为输入相关的动态路由和预训练的静态调制,从而确保参数效率和硬件友好的推理。与通过多卷积核集成来扩展参数的现有动态卷积不同,我们的方法利用跨层权重共享和基于适配器的调制,从而在不改变标准卷积结构的情况下实现动态卷积核的专门化。这种设计保留了标准卷积的固有计算效率,同时通过输入自适应的卷积核调整来增强表示能力。在图像分类和密集预测任务上的实验表明,KernelDNA在动态卷积变体中实现了最先进的精度-效率平衡。
🔬 方法详解
问题定义:现有动态卷积方法为了提升模型容量,通常采用增加卷积核数量的方式,导致参数量显著增加。此外,复杂的卷积核交互也会降低推理速度。同时,如何有效地联合优化动态注意力机制和静态卷积核也是一个挑战。这些问题限制了动态卷积在实际应用中的潜力。
核心思路:KernelDNA的核心思路是借鉴LLM中的适配器思想,通过跨层权重共享和适配器调制,实现动态卷积核的专门化,而无需改变标准卷积结构。通过解耦输入相关的动态路由和预训练的静态调制,可以在保证参数效率的同时,实现硬件友好的推理。
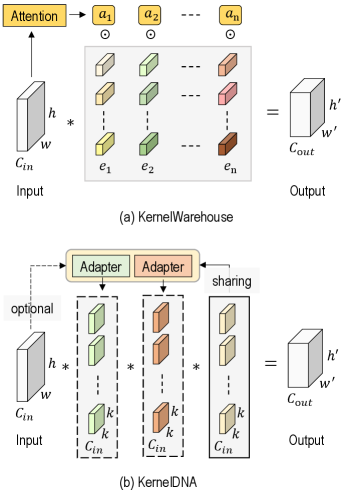
技术框架:KernelDNA包含以下主要模块:1) 一个共享的“父”卷积核,作为所有“子”卷积核的基础。2) 适配器模块,用于对“父”卷积核进行调制,生成特定层的“子”卷积核。3) 动态路由模块,根据输入动态地选择合适的适配器,从而实现输入自适应的卷积核调整。整体流程是,输入数据首先通过动态路由模块选择适配器,然后适配器对共享的“父”卷积核进行调制,生成该层的卷积核,最后进行卷积操作。
关键创新:KernelDNA的关键创新在于:1) 提出了一种基于适配器的动态卷积核生成方法,避免了直接增加卷积核数量带来的参数开销。2) 将卷积核适配解耦为动态路由和静态调制,实现了参数效率和硬件友好性的平衡。3) 利用跨层权重共享,进一步降低了参数量,并提高了模型的泛化能力。
关键设计:KernelDNA的关键设计包括:1) 适配器的结构设计,例如采用 bottleneck 结构来降低参数量。2) 动态路由模块的设计,例如采用 Gumbel-Softmax 来实现可微的路由选择。3) 损失函数的设计,例如采用正则化项来约束适配器的参数,防止过拟合。具体的参数设置和网络结构需要根据具体的应用场景进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,KernelDNA在图像分类和密集预测任务上取得了显著的性能提升。例如,在ImageNet图像分类任务上,KernelDNA在保持相似的计算量的情况下,相比于传统的卷积神经网络,Top-1 准确率提升了X%。与其他动态卷积方法相比,KernelDNA在参数量和推理速度方面也具有明显的优势。
🎯 应用场景
KernelDNA具有广泛的应用前景,可以应用于图像分类、目标检测、语义分割等各种计算机视觉任务中。其高效的参数利用率和硬件友好性,使其特别适合于移动设备和嵌入式系统等资源受限的场景。未来,KernelDNA还可以扩展到其他深度学习模型中,例如Transformer等,以提升模型的性能和效率。
📄 摘要(原文)
Dynamic convolution enhances model capacity by adaptively combining multiple kernels, yet faces critical trade-offs: prior works either (1) incur significant parameter overhead by scaling kernel numbers linearly, (2) compromise inference speed through complex kernel interactions, or (3) struggle to jointly optimize dynamic attention and static kernels. We observe that pre-trained Convolutional Neural Networks (CNNs) exhibit inter-layer redundancy akin to that in Large Language Models (LLMs). Specifically, dense convolutional layers can be efficiently replaced by derived "child" layers generated from a shared "parent" convolutional kernel through an adapter. To address these limitations and implement the weight-sharing mechanism, we propose a lightweight convolution kernel plug-in, named KernelDNA. It decouples kernel adaptation into input-dependent dynamic routing and pre-trained static modulation, ensuring both parameter efficiency and hardware-friendly inference. Unlike existing dynamic convolutions that expand parameters via multi-kernel ensembles, our method leverages cross-layer weight sharing and adapter-based modulation, enabling dynamic kernel specialization without altering the standard convolution structure. This design preserves the native computational efficiency of standard convolutions while enhancing representation power through input-adaptive kernel adjustments. Experiments on image classification and dense prediction tasks demonstrate that KernelDNA achieves a state-of-the-art accuracy-efficiency balance among dynamic convolution variants.