MoCha: Towards Movie-Grade Talking Character Synthesis
作者: Cong Wei, Bo Sun, Haoyu Ma, Ji Hou, Felix Juefei-Xu, Zecheng He, Xiaoliang Dai, Luxin Zhang, Kunpeng Li, Tingbo Hou, Animesh Sinha, Peter Vajda, Wenhu Chen
分类: cs.CV
发布日期: 2025-03-30
备注: https://congwei1230.github.io/MoCha/
💡 一句话要点
MoCha:面向电影级对话角色合成,实现逼真、可控的全身角色动画生成
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 对话角色生成 视频生成 语音-视频同步 多角色对话 联合训练 注意力机制 电影叙事 AI内容生成
📋 核心要点
- 现有视频生成方法忽略了角色驱动的叙事,限制了其在电影和动画制作中的应用。
- MoCha通过语音-视频窗口注意力机制和联合训练策略,实现了逼真的全身对话角色生成。
- 实验结果表明,MoCha在真实感、表现力、可控性和泛化性方面均优于现有方法,为AI电影叙事树立了新标准。
📝 摘要(中文)
视频生成领域的最新进展在运动真实感方面取得了显著成果,但往往忽略了角色驱动的叙事,这对于自动化电影和动画生成至关重要。本文提出了“对话角色”这一更具挑战性的任务,旨在直接从语音和文本生成对话角色动画,而不仅仅是头部。为此,本文提出了MoCha,这是首个生成对话角色的模型。为了确保视频和语音之间的精确同步,MoCha提出了一种语音-视频窗口注意力机制,有效地对齐语音和视频token。为了解决大规模语音标注视频数据集的稀缺问题,MoCha引入了一种联合训练策略,利用语音标注和文本标注的视频数据,显著提高了模型在各种角色动作上的泛化能力。此外,MoCha还设计了带有角色标签的结构化提示模板,首次实现了多角色对话,使AI生成的角色能够进行具有电影连贯性的上下文感知对话。大量的定性和定量评估,包括人类偏好研究和基准比较,表明MoCha为AI生成的电影叙事树立了新标准,在真实感、表现力、可控性和泛化性方面均表现出色。
🔬 方法详解
问题定义:现有视频生成方法,特别是对话人物生成,主要集中在头部区域,缺乏对全身角色动画的生成能力,难以满足电影和动画制作中对角色完整性和表现力的需求。同时,大规模语音标注的全身角色视频数据稀缺,限制了模型的训练和泛化能力。
核心思路:MoCha的核心思路是通过结合语音和文本信息,生成逼真的全身对话角色动画。通过语音-视频窗口注意力机制实现语音和视频的精确同步,并利用联合训练策略解决数据稀缺问题。此外,结构化提示模板的设计使得多角色对话成为可能,从而提升了AI生成电影叙事的连贯性和可控性。
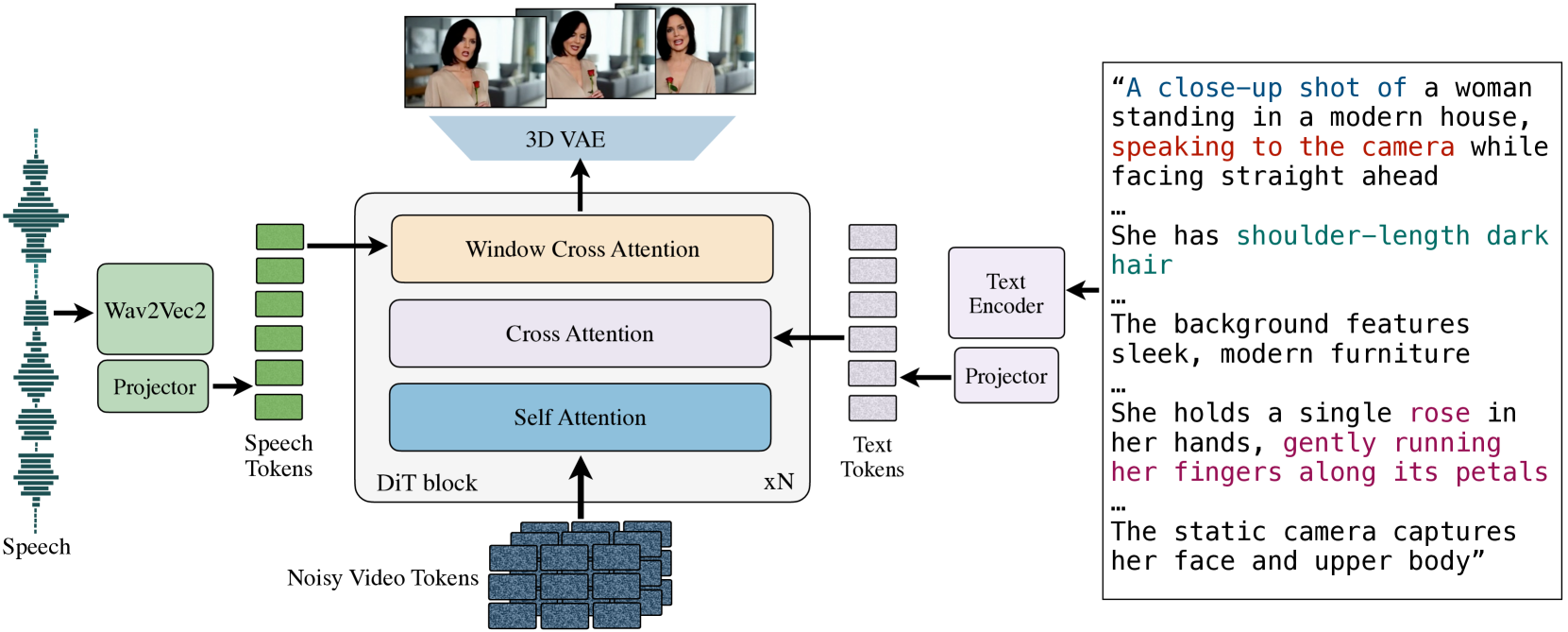
技术框架:MoCha的整体框架包含以下几个主要模块:1) 语音/文本编码器:将语音或文本信息编码为特征向量。2) 视频编码器:提取视频帧的视觉特征。3) 语音-视频窗口注意力模块:对齐语音和视频特征,确保同步。4) 视频生成器:根据对齐后的特征生成视频帧。5) 判别器:用于提升生成视频的真实感。
关键创新:MoCha的关键创新在于:1) 提出了语音-视频窗口注意力机制,有效对齐语音和视频token,保证了视频和语音的同步性。2) 引入了联合训练策略,利用语音标注和文本标注的视频数据,解决了数据稀缺问题,提高了模型的泛化能力。3) 设计了结构化提示模板,实现了多角色对话,提升了AI生成电影叙事的连贯性和可控性。
关键设计:语音-视频窗口注意力机制采用滑动窗口的方式,在视频特征上进行注意力计算,窗口大小是一个关键参数,需要根据语音和视频的帧率进行调整。联合训练策略中,需要平衡语音标注数据和文本标注数据的损失权重。结构化提示模板包含角色标签、对话内容等信息,需要精心设计,以保证生成视频的质量和多样性。
🖼️ 关键图片


📊 实验亮点
MoCha在多个数据集上进行了评估,包括自建的对话角色数据集。实验结果表明,MoCha在真实感、表现力、可控性和泛化性方面均优于现有方法。人类偏好研究表明,MoCha生成的视频在视觉质量和语音同步性方面更受用户青睐。MoCha在多角色对话生成方面也取得了显著进展,能够生成具有电影连贯性的上下文感知对话。
🎯 应用场景
MoCha具有广泛的应用前景,包括自动化电影制作、动画生成、虚拟角色扮演、游戏开发等领域。它可以降低电影和动画制作的成本,提高制作效率,并为用户提供更加个性化的内容创作体验。未来,MoCha有望应用于虚拟现实、增强现实等新兴领域,创造更加沉浸式的互动体验。
📄 摘要(原文)
Recent advancements in video generation have achieved impressive motion realism, yet they often overlook character-driven storytelling, a crucial task for automated film, animation generation. We introduce Talking Characters, a more realistic task to generate talking character animations directly from speech and text. Unlike talking head, Talking Characters aims at generating the full portrait of one or more characters beyond the facial region. In this paper, we propose MoCha, the first of its kind to generate talking characters. To ensure precise synchronization between video and speech, we propose a speech-video window attention mechanism that effectively aligns speech and video tokens. To address the scarcity of large-scale speech-labeled video datasets, we introduce a joint training strategy that leverages both speech-labeled and text-labeled video data, significantly improving generalization across diverse character actions. We also design structured prompt templates with character tags, enabling, for the first time, multi-character conversation with turn-based dialogue-allowing AI-generated characters to engage in context-aware conversations with cinematic coherence. Extensive qualitative and quantitative evaluations, including human preference studies and benchmark comparisons, demonstrate that MoCha sets a new standard for AI-generated cinematic storytelling, achieving superior realism, expressiveness, controllability and generalization.