Efficient Explicit Joint-level Interaction Modeling with Mamba for Text-guided HOI Generation
作者: Guohong Huang, Ling-An Zeng, Zexin Zheng, Shengbo Gu, Wei-Shi Zheng
分类: cs.CV
发布日期: 2025-03-29
备注: Accepted to ICME 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出高效的显式关节级交互建模方法以解决文本引导的HOI生成问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱五:交互与反应 (Interaction & Reaction) 支柱八:物理动画 (Physics-based Animation)
关键词: 人机交互 文本引导 显式建模 关节级交互 计算机视觉 高效算法 动态交互
📋 核心要点
- 现有方法将整个人体视为单一token,难以捕捉细粒度的关节级交互,导致生成的HOI不够真实。
- 本文提出高效显式关节级交互模型(EJIM),通过双分支HOI Mamba和条件注入器,分别建模时空信息与文本语义。
- 实验结果表明,EJIM在公共数据集上显著提升性能,推理时间仅为传统方法的5%。
📝 摘要(中文)
本文提出了一种新颖的方法,用于生成文本引导的人物-物体交互(HOI),以计算高效的方式实现显式的关节级交互建模。以往方法将整个人体视为单一的token,难以捕捉细粒度的关节级交互,导致生成的HOI不够真实。而将每个关节视为token则会导致超过二十倍的token数量,增加计算开销。为了解决这些挑战,本文引入了高效显式关节级交互模型(EJIM),其特点是采用双分支HOI Mamba,分别高效建模时空HOI信息,以及双分支条件注入器,将文本语义和物体几何信息整合到人和物体的运动中。此外,设计了动态交互模块和渐进式掩蔽机制,迭代过滤无关关节,确保准确细致的交互建模。大量定量和定性评估表明,EJIM在公共数据集上显著超越了以往工作,同时仅使用5%的推理时间。
🔬 方法详解
问题定义:本文旨在解决文本引导的HOI生成中,现有方法无法有效捕捉细粒度关节级交互的问题。以往方法将整个人体视为单一token,导致生成的HOI缺乏真实感,同时将每个关节视为token又会显著增加计算开销。
核心思路:论文提出的EJIM通过双分支架构,分别处理时空HOI信息和文本语义,避免了将每个关节单独建模带来的计算负担,同时确保了交互的细致性和准确性。
技术框架:EJIM的整体架构包括双分支HOI Mamba和双分支条件注入器,前者负责时空信息建模,后者则将文本语义与物体几何信息整合到运动中。此外,动态交互模块和渐进式掩蔽机制用于过滤无关关节。
关键创新:EJIM的主要创新在于其高效的双分支建模方式和动态交互模块,显著提升了关节级交互的建模能力,与传统方法相比,能够在保持高效性的同时捕捉更细致的交互信息。
关键设计:在设计中,EJIM采用了动态交互模块来迭代过滤无关关节,并使用渐进式掩蔽机制来确保交互建模的准确性。具体的损失函数和网络结构细节在论文中进行了详细描述。
🖼️ 关键图片
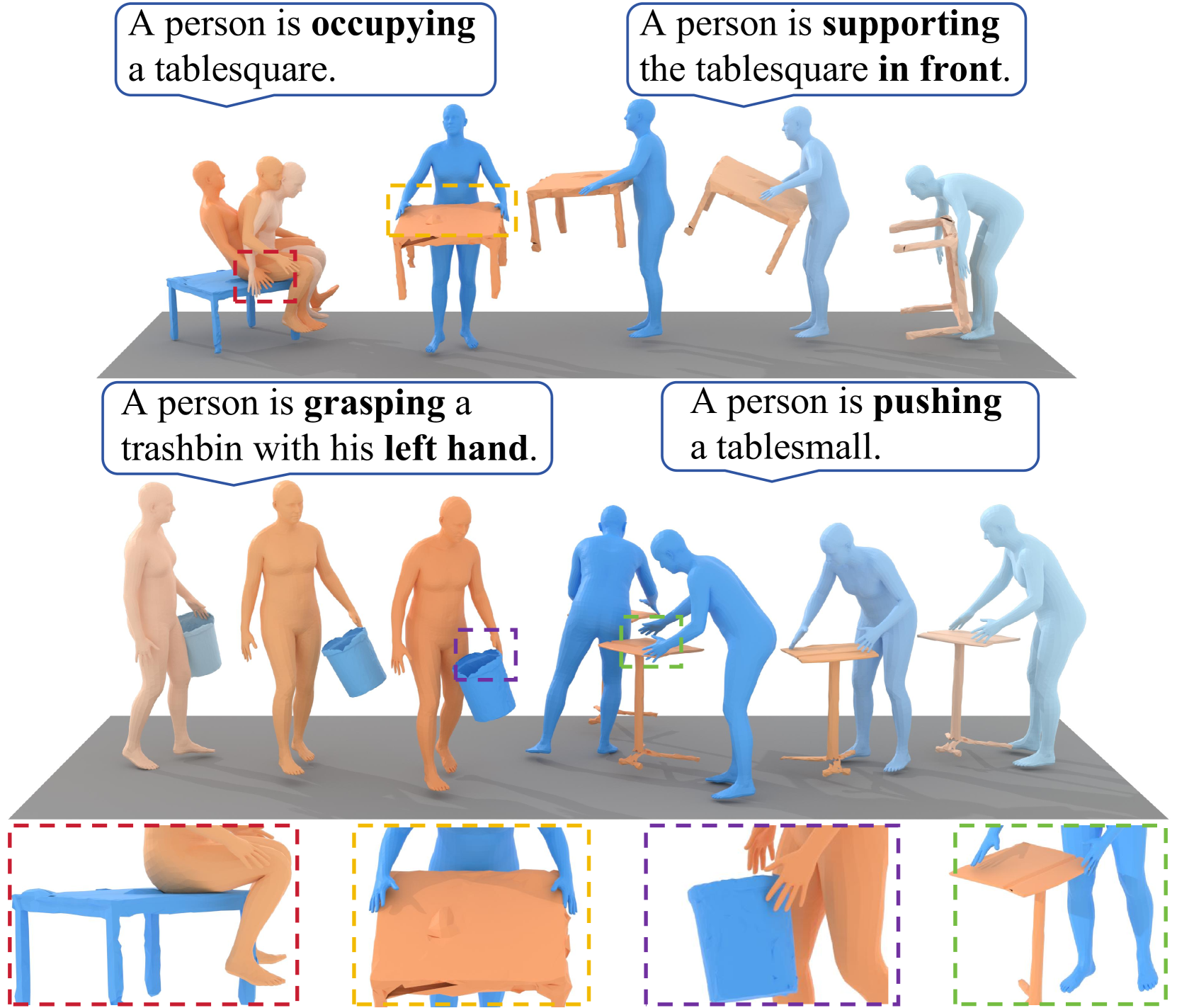


📊 实验亮点
实验结果显示,EJIM在多个公共数据集上表现优异,相较于以往方法,性能提升显著,推理时间仅为5%。具体而言,EJIM在生成的HOI质量上超越了传统方法,展示了其在效率与效果上的优势。
🎯 应用场景
该研究在计算机视觉和人机交互领域具有广泛的应用潜力,能够用于增强现实、虚拟现实以及智能监控等场景。通过更真实的HOI生成,能够提升用户体验和系统的智能化水平,未来可能推动相关技术的进一步发展。
📄 摘要(原文)
We propose a novel approach for generating text-guided human-object interactions (HOIs) that achieves explicit joint-level interaction modeling in a computationally efficient manner. Previous methods represent the entire human body as a single token, making it difficult to capture fine-grained joint-level interactions and resulting in unrealistic HOIs. However, treating each individual joint as a token would yield over twenty times more tokens, increasing computational overhead. To address these challenges, we introduce an Efficient Explicit Joint-level Interaction Model (EJIM). EJIM features a Dual-branch HOI Mamba that separately and efficiently models spatiotemporal HOI information, as well as a Dual-branch Condition Injector for integrating text semantics and object geometry into human and object motions. Furthermore, we design a Dynamic Interaction Block and a progressive masking mechanism to iteratively filter out irrelevant joints, ensuring accurate and nuanced interaction modeling. Extensive quantitative and qualitative evaluations on public datasets demonstrate that EJIM surpasses previous works by a large margin while using only 5\% of the inference time. Code is available \href{https://github.com/Huanggh531/EJIM}{here}.