AutoComPose: Automatic Generation of Pose Transition Descriptions for Composed Pose Retrieval Using Multimodal LLMs
作者: Yi-Ting Shen, Sungmin Eum, Doheon Lee, Rohit Shete, Chiao-Yi Wang, Heesung Kwon, Shuvra S. Bhattacharyya
分类: cs.CV
发布日期: 2025-03-28 (更新: 2025-08-19)
备注: ICCV 2025
💡 一句话要点
AutoComPose:利用多模态LLM自动生成姿态迁移描述,用于组合姿态检索。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 组合姿态检索 多模态LLM 姿态迁移描述 自动标注 循环一致性
📋 核心要点
- 现有组合姿态检索数据集依赖人工标注或启发式规则,成本高昂且缺乏多样性和可扩展性。
- AutoComPose利用多模态LLM自动生成姿态迁移描述,通过细粒度分解和循环一致性提高标注质量。
- 实验表明,使用AutoComPose训练的检索模型优于人工标注和启发式方法,降低成本并提升检索质量。
📝 摘要(中文)
组合姿态检索(CPR)允许用户通过指定参考姿态和迁移描述来搜索人体姿态,但该领域的发展受到带标注的姿态迁移数据稀缺和不一致的阻碍。现有的CPR数据集依赖于昂贵的人工标注或基于启发式的规则生成,这两种方法都限制了可扩展性和多样性。本文提出了AutoComPose,这是第一个利用多模态大型语言模型(MLLM)自动生成丰富且结构化的姿态迁移描述的框架。我们的方法通过将迁移分解为细粒度的身体部位运动,并引入镜像/交换变体来提高标注质量,同时循环一致性约束确保了正向和反向迁移之间的逻辑连贯性。为了推进CPR研究,我们构建并发布了两个专用基准,AIST-CPR和PoseFixCPR,用增强的属性补充了先前的数据集。大量实验表明,使用AutoComPose训练检索模型比人工标注和基于启发式的方法产生更好的性能,显著降低了标注成本,同时提高了检索质量。我们的工作开创了姿态迁移的自动标注,为未来的CPR研究奠定了可扩展的基础。
🔬 方法详解
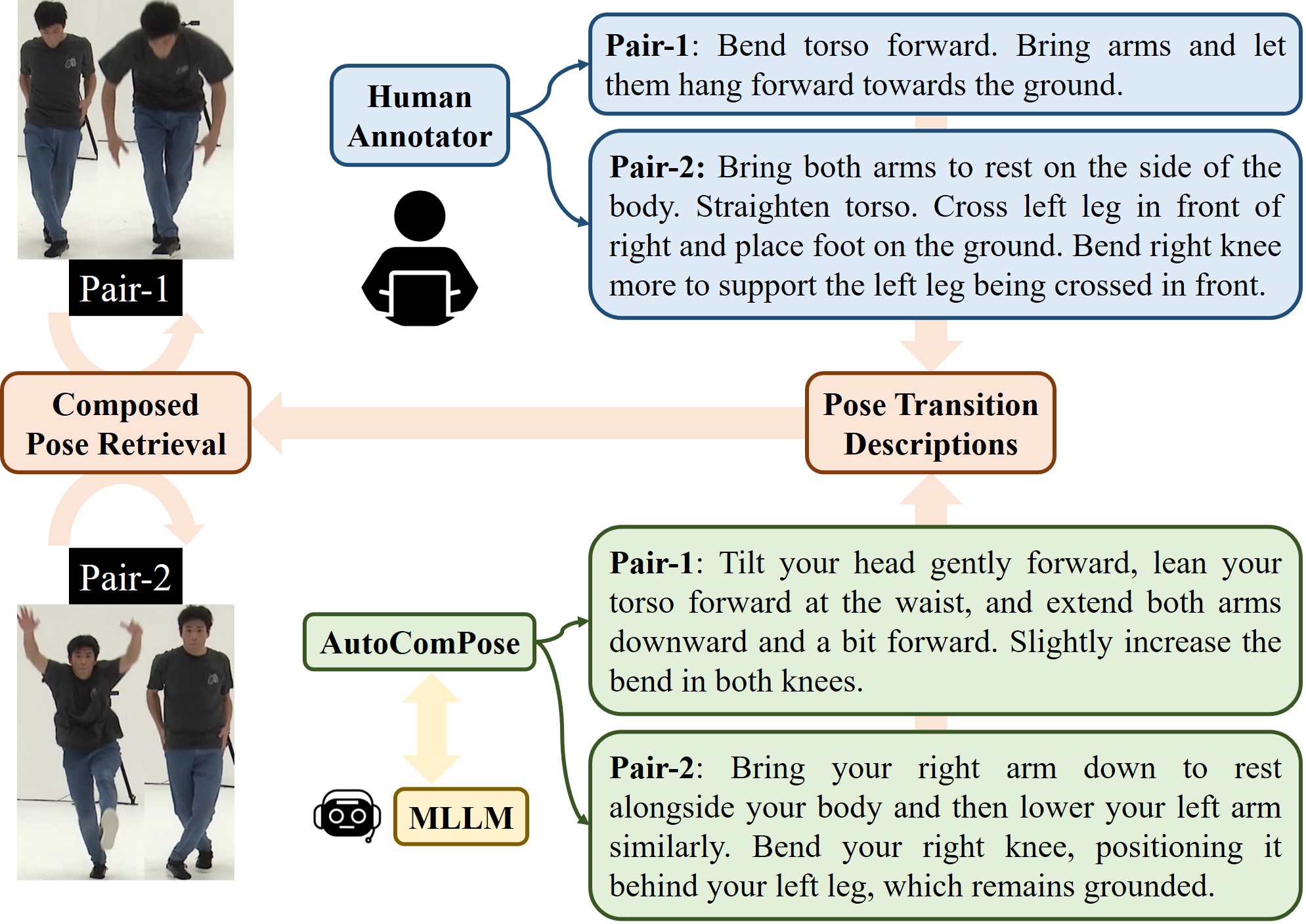
问题定义:组合姿态检索(CPR)旨在根据参考姿态和迁移描述检索目标姿态。现有方法依赖于人工标注或启发式规则生成姿态迁移描述,存在成本高、可扩展性差、描述不一致等问题。人工标注耗时耗力,启发式规则难以覆盖复杂多样的姿态迁移。
核心思路:AutoComPose的核心在于利用多模态大型语言模型(MLLM)的强大生成能力,自动生成高质量、结构化的姿态迁移描述。通过将姿态迁移分解为细粒度的身体部位运动,并引入镜像/交换变体,增强描述的多样性和准确性。同时,引入循环一致性约束,确保正向和反向迁移描述的逻辑一致性,提高标注质量。
技术框架:AutoComPose框架主要包含以下几个阶段:1) 参考姿态输入:输入参考姿态图像或姿态关键点。2) MLLM描述生成:利用MLLM生成初始的姿态迁移描述。3) 细粒度分解:将姿态迁移描述分解为各个身体部位的运动描述。4) 变体生成:生成镜像/交换等变体描述,增加多样性。5) 循环一致性校验:通过正向和反向迁移描述的循环一致性校验,过滤不一致的描述。6) 数据集构建:将生成的姿态迁移描述与对应的姿态对组成新的CPR数据集。
关键创新:AutoComPose的关键创新在于:1) 首次将多模态LLM应用于姿态迁移描述的自动生成,摆脱了对人工标注的依赖。2) 提出了细粒度的姿态迁移描述分解方法,提高了描述的准确性和可解释性。3) 引入了循环一致性约束,保证了正向和反向迁移描述的逻辑一致性,提高了标注质量。与现有方法相比,AutoComPose能够以更低的成本生成更高质量、更多样化的姿态迁移描述。
关键设计:AutoComPose中,MLLM的选择至关重要,需要选择具备强大的图像理解和文本生成能力的MLLM。循环一致性损失函数的设计也需要仔细考虑,以确保正向和反向迁移描述的语义一致性。此外,细粒度分解的粒度选择也会影响最终的描述质量,需要根据具体的应用场景进行调整。具体参数设置和网络结构在论文中未详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用AutoComPose生成的数据集训练的CPR模型在AIST-CPR和PoseFixCPR两个基准测试上均取得了显著的性能提升,超越了使用人工标注和启发式方法生成的数据集训练的模型。具体性能数据和提升幅度在论文中未给出明确的量化指标,属于未知信息。但总体而言,AutoComPose在降低标注成本的同时,显著提高了CPR的检索质量。
🎯 应用场景
AutoComPose生成的姿态迁移描述可用于训练更强大的组合姿态检索模型,从而广泛应用于人机交互、运动分析、虚拟现实、游戏等领域。例如,用户可以通过自然语言描述“向左转”来搜索人体姿态,从而实现更自然、更高效的人机交互。该研究为姿态检索领域提供了一种新的数据生成和模型训练方法,具有重要的实际应用价值和未来发展潜力。
📄 摘要(原文)
Composed pose retrieval (CPR) enables users to search for human poses by specifying a reference pose and a transition description, but progress in this field is hindered by the scarcity and inconsistency of annotated pose transitions. Existing CPR datasets rely on costly human annotations or heuristic-based rule generation, both of which limit scalability and diversity. In this work, we introduce AutoComPose, the first framework that leverages multimodal large language models (MLLMs) to automatically generate rich and structured pose transition descriptions. Our method enhances annotation quality by structuring transitions into fine-grained body part movements and introducing mirrored/swapped variations, while a cyclic consistency constraint ensures logical coherence between forward and reverse transitions. To advance CPR research, we construct and release two dedicated benchmarks, AIST-CPR and PoseFixCPR, supplementing prior datasets with enhanced attributes. Extensive experiments demonstrate that training retrieval models with AutoComPose yields superior performance over human-annotated and heuristic-based methods, significantly reducing annotation costs while improving retrieval quality. Our work pioneers the automatic annotation of pose transitions, establishing a scalable foundation for future CPR research.