MVSAnywhere: Zero-Shot Multi-View Stereo
作者: Sergio Izquierdo, Mohamed Sayed, Michael Firman, Guillermo Garcia-Hernando, Daniyar Turmukhambetov, Javier Civera, Oisin Mac Aodha, Gabriel Brostow, Jamie Watson
分类: cs.CV
发布日期: 2025-03-28
备注: CVPR 2025
💡 一句话要点
MVSAnywhere:提出一种零样本多视角立体匹配方法,可泛化到不同场景和深度范围。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 多视角立体匹配 零样本学习 深度估计 Transformer网络 自适应代价体
📋 核心要点
- 现有多视角立体匹配方法难以泛化到不同场景和深度范围,通用模型训练面临诸多挑战。
- MVSA结合单目和多视角线索,利用自适应代价体处理尺度问题,实现跨域泛化。
- 在Robust Multi-View Depth Benchmark上,MVSA实现了最先进的零样本深度估计性能。
📝 摘要(中文)
从多视角图像中计算精确的深度信息是计算机视觉领域一个基础且长期存在的挑战。然而,现有方法在不同领域和场景类型(例如,室内与室外)之间的泛化能力较差。训练一个通用的多视角立体匹配模型具有挑战性,并引发了几个问题,例如,如何最好地利用基于Transformer的架构,如何在输入视图数量可变的情况下整合额外的元数据,以及如何估计有效深度的范围,因为该范围在不同场景中可能差异很大,并且通常无法先验得知?为了解决这些问题,我们引入了MVSA,一种新颖且通用的多视角立体匹配架构,旨在通过泛化到不同的领域和深度范围来在任何地方工作。MVSA结合了单目和多视角线索,并采用自适应代价体来处理与尺度相关的问题。我们在Robust Multi-View Depth Benchmark上展示了最先进的零样本深度估计结果,超越了现有的多视角立体匹配和单目基线。
🔬 方法详解
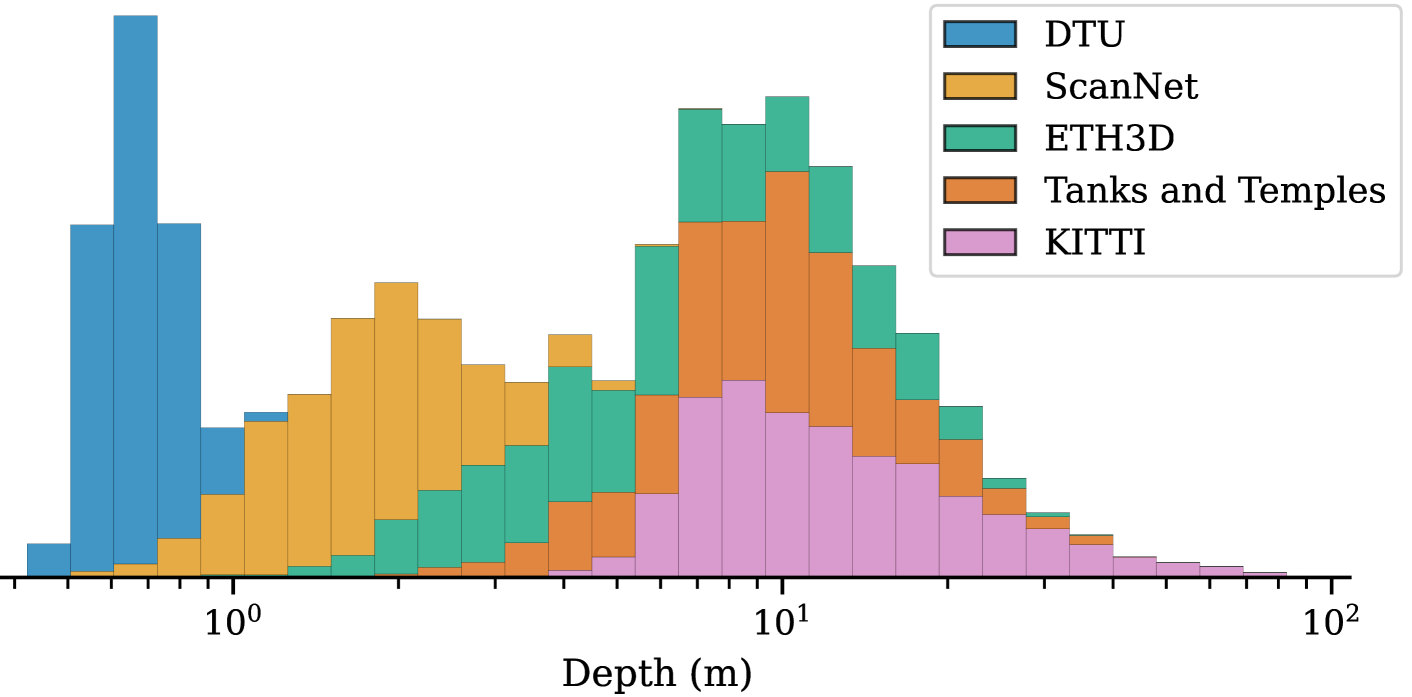
问题定义:论文旨在解决多视角立体匹配中,现有方法在不同场景和深度范围泛化能力差的问题。现有方法通常针对特定数据集进行训练,难以适应新的、未见过的场景,尤其是在深度范围变化较大的情况下,性能会显著下降。
核心思路:论文的核心思路是设计一个能够同时利用单目和多视角信息的架构,并引入自适应代价体来处理不同场景下的尺度变化问题。通过结合单目深度估计的先验知识和多视角几何约束,模型能够更好地理解场景结构,从而提高泛化能力。自适应代价体允许模型根据输入图像的特性动态调整深度搜索范围,从而适应不同的深度范围。
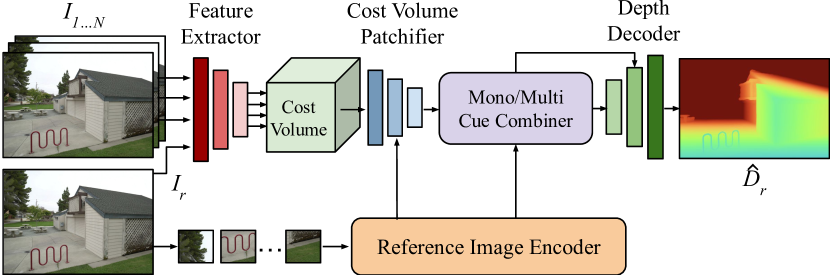
技术框架:MVSA的整体架构包含以下几个主要模块:1) 特征提取模块:使用卷积神经网络提取每个输入图像的特征。2) 单目深度估计模块:利用单目图像估计初始深度图,提供深度先验。3) 代价体构建模块:基于多视角图像的特征和单目深度先验,构建代价体。4) 代价体优化模块:使用Transformer网络对代价体进行优化,聚合多视角信息。5) 深度图回归模块:从优化后的代价体中回归最终的深度图。
关键创新:MVSA的关键创新在于其自适应代价体和Transformer网络的结合。自适应代价体能够根据场景特性动态调整深度搜索范围,从而提高对不同深度范围的适应性。Transformer网络能够有效地聚合多视角信息,从而提高深度估计的准确性。此外,MVSA还结合了单目深度估计的先验知识,进一步提高了模型的泛化能力。
关键设计:在自适应代价体方面,论文采用了一种基于方差的深度范围估计方法,根据单目深度估计结果的方差来确定深度搜索范围。在Transformer网络方面,论文采用了一种多头注意力机制,允许模型同时关注不同的特征维度。损失函数方面,论文采用了L1损失和Smooth L1损失的组合,以提高深度估计的鲁棒性。
🖼️ 关键图片

📊 实验亮点
MVSA在Robust Multi-View Depth Benchmark上取得了显著的成果,在零样本设置下超越了现有的多视角立体匹配和单目深度估计基线。具体而言,MVSA在多个指标上都取得了最佳性能,证明了其在跨域泛化方面的优越性。实验结果表明,MVSA能够有效地处理不同场景和深度范围,具有很强的鲁棒性。
🎯 应用场景
MVSAnywhere具有广泛的应用前景,包括自动驾驶、机器人导航、三维重建、虚拟现实和增强现实等领域。该方法能够提高这些应用在不同场景下的鲁棒性和准确性,尤其是在缺乏训练数据的场景中。未来,该方法可以进一步扩展到处理动态场景和具有挑战性的光照条件。
📄 摘要(原文)
Computing accurate depth from multiple views is a fundamental and longstanding challenge in computer vision. However, most existing approaches do not generalize well across different domains and scene types (e.g. indoor vs. outdoor). Training a general-purpose multi-view stereo model is challenging and raises several questions, e.g. how to best make use of transformer-based architectures, how to incorporate additional metadata when there is a variable number of input views, and how to estimate the range of valid depths which can vary considerably across different scenes and is typically not known a priori? To address these issues, we introduce MVSA, a novel and versatile Multi-View Stereo architecture that aims to work Anywhere by generalizing across diverse domains and depth ranges. MVSA combines monocular and multi-view cues with an adaptive cost volume to deal with scale-related issues. We demonstrate state-of-the-art zero-shot depth estimation on the Robust Multi-View Depth Benchmark, surpassing existing multi-view stereo and monocular baselines.