One Look is Enough: Seamless Patchwise Refinement for Zero-Shot Monocular Depth Estimation on High-Resolution Images
作者: Byeongjun Kwon, Munchurl Kim
分类: cs.CV
发布日期: 2025-03-28 (更新: 2025-07-31)
备注: ICCV 2025 (camera-ready version). Project page
💡 一句话要点
提出PRO框架,通过无缝分块细化实现高分辨率图像零样本单目深度估计
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 零样本深度估计 单目深度估计 高分辨率图像 分块细化 深度不连续性 泛化能力 一致性训练
📋 核心要点
- 现有零样本深度估计模型在高分辨率图像上表现不佳,直接处理计算量大,下采样则损失细节,泛化性不足。
- 提出Patch Refine Once (PRO)框架,通过分组分块一致性训练和无偏掩码,提升效率和泛化能力。
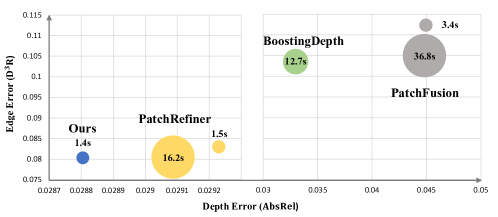
- 在多个数据集上的零样本评估表明,PRO可以无缝集成到现有深度估计模型中,提升深度估计效果。
📝 摘要(中文)
零样本深度估计(DE)模型由于在大规模数据集上训练,展现出强大的泛化性能。然而,现有模型在高分辨率图像上表现不佳,这是因为训练(使用较小分辨率)和推理(针对高分辨率)的图像分辨率存在差异。以全分辨率处理会导致深度估计精度下降和巨大的内存消耗,而下采样到训练分辨率会导致估计深度图像中的边缘模糊。主流的高分辨率深度估计方法采用基于分块的方法,但在重新组装估计的深度分块时会引入深度不连续性问题,导致测试时效率低下。此外,为了获得精细的深度细节,这些方法依赖于合成数据集,因为真实世界的ground truth深度是稀疏的,导致泛化能力差。为了解决这些限制,我们提出了Patch Refine Once (PRO),一个高效且可泛化的基于分块的框架。我们的PRO包含两个关键组件:(i)分组分块一致性训练,通过联合处理四个重叠的分块并在单个反向传播步骤中对它们的重叠区域强制执行一致性损失,从而提高测试时效率,同时减轻深度不连续性问题,以及(ii)无偏掩码,防止DE模型过度拟合数据集特定的偏差,即使在合成数据上训练后也能更好地泛化到真实世界的数据集。在Booster、ETH3D、Middlebury 2014和NuScenes上的零样本评估表明,我们的PRO可以无缝集成到现有的深度估计模型中。
🔬 方法详解
问题定义:论文旨在解决零样本单目深度估计在高分辨率图像上的应用难题。现有方法要么计算量过大,要么损失细节,并且依赖合成数据导致泛化性差。基于分块的方法虽然能处理高分辨率图像,但会引入深度不连续性,影响最终效果。
核心思路:论文的核心思路是通过一种高效且可泛化的分块细化框架,在保证计算效率的同时,解决深度不连续性问题,并提高模型在真实场景中的泛化能力。该框架通过分组分块一致性训练和无偏掩码来达到这一目标。
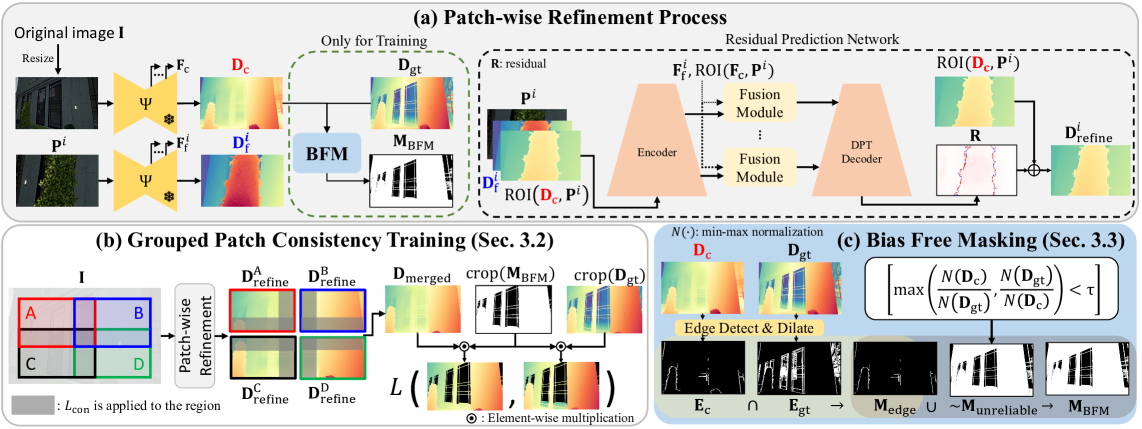
技术框架:PRO框架主要包含两个关键模块:分组分块一致性训练和无偏掩码。分组分块一致性训练同时处理四个重叠的分块,并在重叠区域强制执行一致性损失,以减少深度不连续性。无偏掩码则用于防止模型过度拟合训练数据中的特定偏差。整体流程是先将高分辨率图像分割成重叠的patch,然后利用PRO框架进行深度估计,最后将patch重新组合成完整的深度图。
关键创新:论文的关键创新在于分组分块一致性训练和无偏掩码的结合。分组分块一致性训练通过联合处理重叠区域,有效缓解了深度不连续性问题,提高了深度估计的准确性。无偏掩码则增强了模型的泛化能力,使其能够更好地适应真实世界的场景。
关键设计:分组分块一致性训练的关键在于一致性损失函数的选择和重叠区域的比例。无偏掩码的关键在于如何有效地识别和消除训练数据中的偏差。具体的网络结构和参数设置取决于所集成的深度估计模型。论文中可能使用了特定的损失函数来衡量重叠区域深度估计的一致性,例如L1损失或L2损失。具体实现细节未知。
🖼️ 关键图片

📊 实验亮点
论文在Booster、ETH3D、Middlebury 2014和NuScenes等数据集上进行了零样本评估,结果表明PRO可以无缝集成到现有的深度估计模型中,并在深度估计精度和泛化能力方面取得了显著提升。具体的性能提升数据未知,但论文强调了PRO在解决深度不连续性问题和提高泛化能力方面的优势。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、虚拟现实等领域,为这些应用提供更准确、更可靠的深度信息。通过提升高分辨率图像的深度估计精度,可以增强环境感知能力,提高决策的准确性和安全性。未来,该技术有望在更多需要深度信息的场景中发挥重要作用。
📄 摘要(原文)
Zero-shot depth estimation (DE) models exhibit strong generalization performance as they are trained on large-scale datasets. However, existing models struggle with high-resolution images due to the discrepancy in image resolutions of training (with smaller resolutions) and inference (for high resolutions). Processing them at full resolution leads to decreased estimation accuracy on depth with tremendous memory consumption, while downsampling to the training resolution results in blurred edges in the estimated depth images. Prevailing high-resolution depth estimation methods adopt a patch-based approach, which introduces depth discontinuity issues when reassembling the estimated depth patches, resulting in test-time inefficiency. Additionally, to obtain fine-grained depth details, these methods rely on synthetic datasets due to the real-world sparse ground truth depth, leading to poor generalizability. To tackle these limitations, we propose Patch Refine Once (PRO), an efficient and generalizable tile-based framework. Our PRO consists of two key components: (i) Grouped Patch Consistency Training that enhances test-time efficiency while mitigating the depth discontinuity problem by jointly processing four overlapping patches and enforcing a consistency loss on their overlapping regions within a single backpropagation step, and (ii) Bias Free Masking that prevents the DE models from overfitting to dataset-specific biases, enabling better generalization to real-world datasets even after training on synthetic data. Zero-shot evaluations on Booster, ETH3D, Middlebury 2014, and NuScenes demonstrate that our PRO can be seamlessly integrated into existing depth estimation models.