Segment Any Motion in Videos
作者: Nan Huang, Wenzhao Zheng, Chenfeng Xu, Kurt Keutzer, Shanghang Zhang, Angjoo Kanazawa, Qianqian Wang
分类: cs.CV
发布日期: 2025-03-28 (更新: 2025-04-14)
备注: CVPR 2025. Website: https://motion-seg.github.io/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出一种结合长程轨迹运动线索和语义特征的视频运动目标分割方法
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视频分割 运动目标分割 长程轨迹 语义特征 注意力机制 SAM2 DINO
📋 核心要点
- 现有方法依赖光流进行运动目标分割,但易受部分运动、复杂形变和背景干扰等因素影响。
- 该方法结合长程轨迹运动线索和DINO语义特征,通过迭代提示策略使用SAM2进行像素级掩码优化。
- 实验结果表明,该方法在各种数据集上均取得了state-of-the-art的性能,尤其在复杂场景下表现优异。
📝 摘要(中文)
移动目标分割是实现视觉场景高级理解的关键任务,并具有众多的下游应用。人类可以毫不费力地分割视频中的移动物体。以往的工作主要依赖于光流来提供运动线索;然而,由于诸如部分运动、复杂变形、运动模糊和背景干扰等挑战,这种方法通常会导致不完美的预测。我们提出了一种新颖的移动目标分割方法,该方法结合了长程轨迹运动线索与基于DINO的语义特征,并通过迭代提示策略利用SAM2进行像素级掩码密集化。我们的模型采用时空轨迹注意力和运动-语义解耦嵌入来优先考虑运动,同时整合语义支持。在各种数据集上的广泛测试表明,该方法具有最先进的性能,在具有挑战性的场景和多个对象的精细分割方面表现出色。
🔬 方法详解
问题定义:视频中的运动目标分割旨在准确识别和分割视频序列中独立运动的物体。现有方法,特别是基于光流的方法,在处理复杂运动(如非刚性形变、遮挡、快速运动)以及存在噪声或背景干扰时,分割效果往往不理想。这些方法难以有效利用长程的运动信息和高级语义信息,导致分割精度受限。
核心思路:该论文的核心思路是将长程的运动轨迹信息与图像的语义信息相结合,从而更准确地识别和分割运动目标。通过分析物体在视频中的运动轨迹,可以更好地理解物体的运动模式,克服光流法在处理复杂运动时的局限性。同时,结合语义信息可以区分不同的物体,并提高分割的准确性。利用SAM2进行像素级掩码密集化,进一步提升分割的精细程度。
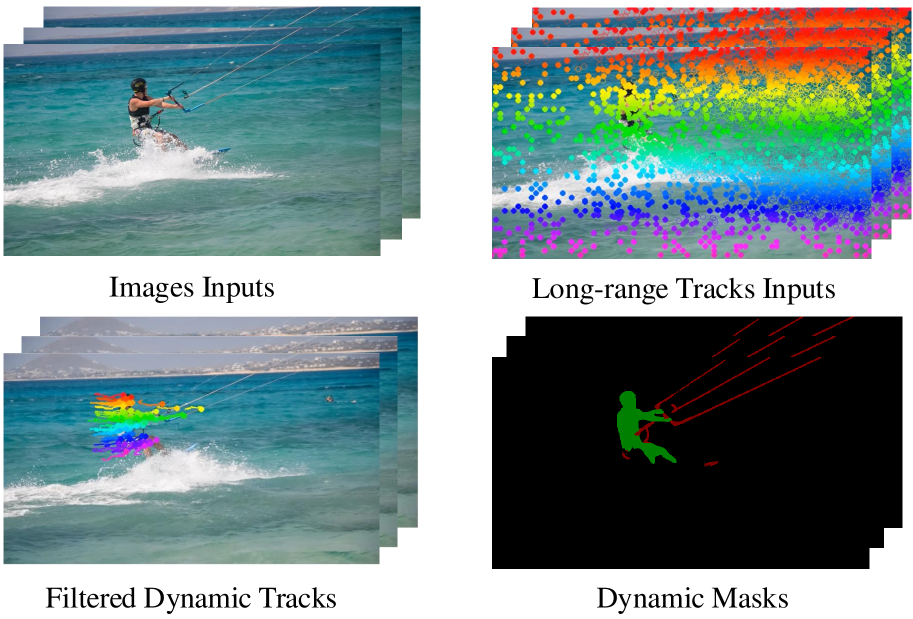
技术框架:该方法主要包含以下几个模块:1) 特征提取:使用DINO模型提取图像的语义特征。2) 轨迹提取:通过某种轨迹跟踪算法提取视频中物体的运动轨迹。3) 时空轨迹注意力:设计时空轨迹注意力机制,用于融合运动轨迹信息和语义特征,突出运动区域。4) 运动-语义解耦嵌入:将运动信息和语义信息解耦,分别进行嵌入表示,然后进行融合。5) 掩码生成与优化:利用融合后的特征生成初始的运动目标掩码,并使用SAM2进行迭代提示,逐步优化掩码的精度。
关键创新:该方法最重要的创新点在于:1) 结合了长程运动轨迹信息和语义信息,克服了传统光流法的局限性。2) 提出了时空轨迹注意力机制和运动-语义解耦嵌入,有效地融合了运动信息和语义信息。3) 利用SAM2进行像素级掩码密集化,提升了分割的精细程度。
关键设计:关于关键设计,论文中提到了Spatio-Temporal Trajectory Attention和Motion-Semantic Decoupled Embedding,但具体实现细节(如注意力机制的具体形式、嵌入向量的维度、损失函数的设计等)需要参考论文原文。迭代提示策略的具体实现方式,例如每次迭代的prompt选择方法,也是一个关键的设计细节。
🖼️ 关键图片


📊 实验亮点
该方法在多个数据集上取得了state-of-the-art的性能,尤其在复杂场景和精细分割方面表现出色。论文中提到在具有挑战性的场景和多个对象的精细分割方面表现出色,但未提供具体的性能数据和对比基线,具体提升幅度未知。
🎯 应用场景
该研究成果可广泛应用于视频监控、自动驾驶、视频编辑、机器人导航等领域。例如,在自动驾驶中,可以利用该技术准确分割移动的车辆和行人,提高驾驶安全性。在视频监控中,可以自动识别和跟踪可疑目标。在视频编辑中,可以方便地对视频中的运动物体进行编辑和处理。
📄 摘要(原文)
Moving object segmentation is a crucial task for achieving a high-level understanding of visual scenes and has numerous downstream applications. Humans can effortlessly segment moving objects in videos. Previous work has largely relied on optical flow to provide motion cues; however, this approach often results in imperfect predictions due to challenges such as partial motion, complex deformations, motion blur and background distractions. We propose a novel approach for moving object segmentation that combines long-range trajectory motion cues with DINO-based semantic features and leverages SAM2 for pixel-level mask densification through an iterative prompting strategy. Our model employs Spatio-Temporal Trajectory Attention and Motion-Semantic Decoupled Embedding to prioritize motion while integrating semantic support. Extensive testing on diverse datasets demonstrates state-of-the-art performance, excelling in challenging scenarios and fine-grained segmentation of multiple objects. Our code is available at https://motion-seg.github.io/.