Segment then Splat: Unified 3D Open-Vocabulary Segmentation via Gaussian Splatting
作者: Yiren Lu, Yunlai Zhou, Yiran Qiao, Chaoda Song, Tuo Liang, Jing Ma, Huan Wang, Yu Yin
分类: cs.CV
发布日期: 2025-03-28 (更新: 2025-10-26)
备注: NeurIPS 2025. Project page: https://vulab-ai.github.io/Segment-then-Splat/
💡 一句话要点
提出Segment then Splat,通过高斯溅射实现统一的3D开放词汇分割
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D分割 开放词汇 高斯溅射 动态场景 场景理解
📋 核心要点
- 现有方法依赖于2D像素级解析,导致多视角不一致和3D物体检索效果差,且难以处理动态场景。
- Segment then Splat的核心思想是在重建前将高斯分布分割成不同的对象集合,从而实现3D场景的自然分割。
- 实验表明,该方法在静态和动态场景中均表现出良好的分割效果,验证了其有效性。
📝 摘要(中文)
本文提出Segment then Splat,一种基于高斯溅射的3D感知开放词汇分割方法,适用于静态和动态场景。该方法颠覆了传统的“重建后分割”方法,在重建之前将高斯分布划分为不同的对象集合。完成重建后,场景自然地分割成独立的物体,从而实现真正的3D分割。这种设计消除了几何和语义的歧义,以及动态场景中高斯-对象未对齐的问题。它还加速了优化过程,因为它消除了学习单独语言场的需要。优化后,每个对象都被分配一个CLIP嵌入,以实现开放词汇查询。在各种数据集上的大量实验证明了该方法在静态和动态场景中的有效性。
🔬 方法详解
问题定义:现有3D开放词汇分割方法主要依赖于2D图像的像素级分割,然后将其投影到3D空间,这导致多视角不一致性问题,并且在3D物体检索方面表现不佳。此外,现有方法难以处理动态场景,因为动态场景中的运动建模非常复杂。
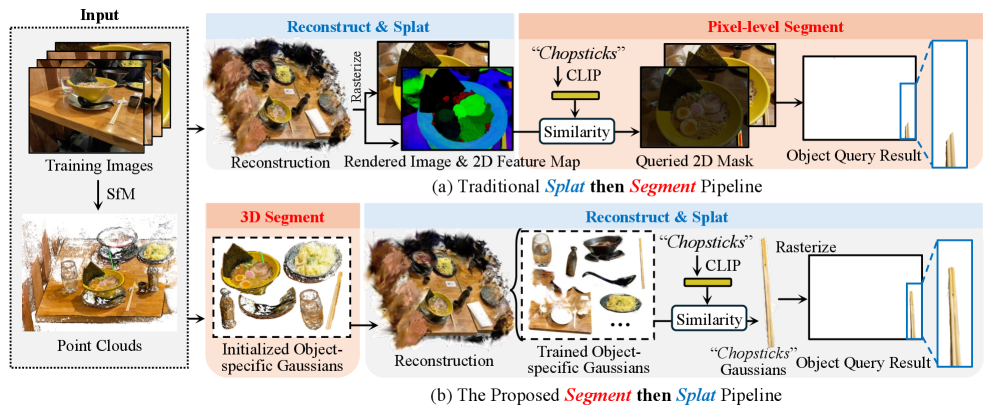
核心思路:Segment then Splat的核心思路是颠覆传统的“重建后分割”流程,改为“分割后重建”。具体来说,该方法首先将高斯分布分割成不同的对象集合,然后再进行3D场景的重建。这样,重建后的场景就自然地分割成了独立的物体。
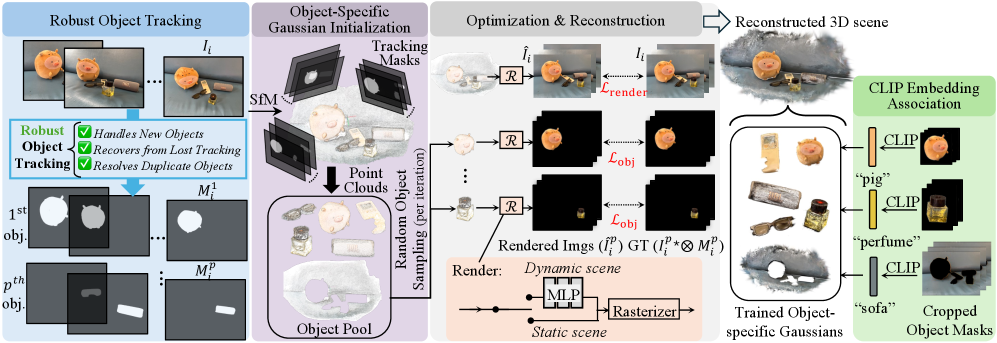
技术框架:Segment then Splat的整体框架可以分为以下几个阶段:1) 高斯分布初始化:使用高斯溅射技术初始化3D场景;2) 对象分割:将高斯分布分割成不同的对象集合;3) 场景重建:基于分割后的高斯分布重建3D场景;4) CLIP嵌入:为每个对象分配一个CLIP嵌入,用于开放词汇查询。
关键创新:Segment then Splat最重要的创新点在于其“分割后重建”的流程。与传统的“重建后分割”方法相比,该方法能够消除几何和语义的歧义,以及动态场景中高斯-对象未对齐的问题。此外,该方法还避免了学习单独的语言场,从而加速了优化过程。
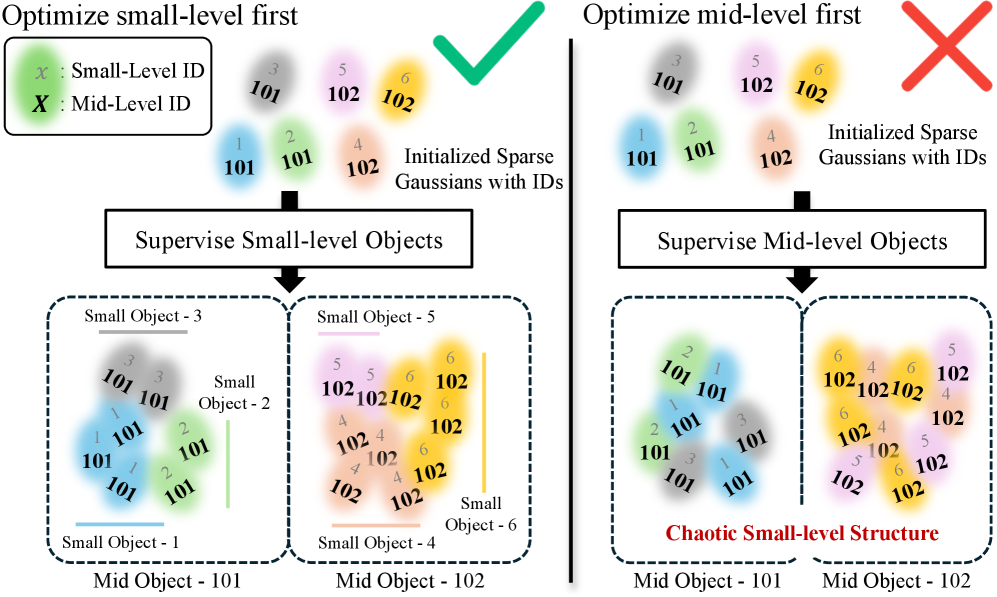
关键设计:论文的关键设计包括:1) 使用高斯溅射技术进行3D场景的初始化和重建;2) 设计有效的对象分割算法,将高斯分布分割成不同的对象集合;3) 使用CLIP模型为每个对象生成嵌入,用于开放词汇查询。具体的分割算法和损失函数等细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
论文在多个数据集上进行了实验,证明了Segment then Splat在静态和动态场景中的有效性。具体的性能数据和对比基线在摘要中未提及,属于未知信息。但论文强调该方法能够消除几何和语义的歧义,并加速优化过程,表明其具有显著的优势。
🎯 应用场景
该研究成果可广泛应用于机器人、自动驾驶系统和增强现实等领域。例如,机器人可以利用该技术理解周围环境,并根据用户的自然语言指令执行任务。自动驾驶系统可以利用该技术识别道路上的各种物体,并做出相应的决策。增强现实应用可以利用该技术将虚拟物体与真实场景进行融合。
📄 摘要(原文)
Open-vocabulary querying in 3D space is crucial for enabling more intelligent perception in applications such as robotics, autonomous systems, and augmented reality. However, most existing methods rely on 2D pixel-level parsing, leading to multi-view inconsistencies and poor 3D object retrieval. Moreover, they are limited to static scenes and struggle with dynamic scenes due to the complexities of motion modeling. In this paper, we propose Segment then Splat, a 3D-aware open vocabulary segmentation approach for both static and dynamic scenes based on Gaussian Splatting. Segment then Splat reverses the long established approach of "segmentation after reconstruction" by dividing Gaussians into distinct object sets before reconstruction. Once reconstruction is complete, the scene is naturally segmented into individual objects, achieving true 3D segmentation. This design eliminates both geometric and semantic ambiguities, as well as Gaussian-object misalignment issues in dynamic scenes. It also accelerates the optimization process, as it eliminates the need for learning a separate language field. After optimization, a CLIP embedding is assigned to each object to enable open-vocabulary querying. Extensive experiments one various datasets demonstrate the effectiveness of our proposed method in both static and dynamic scenarios.