A Survey on Remote Sensing Foundation Models: From Vision to Multimodality
作者: Ziyue Huang, Hongxi Yan, Qiqi Zhan, Shuai Yang, Mingming Zhang, Chenkai Zhang, YiMing Lei, Zeming Liu, Qingjie Liu, Yunhong Wang
分类: cs.CV
发布日期: 2025-03-28
🔗 代码/项目: GITHUB
💡 一句话要点
遥感领域大模型综述:从视觉到多模态的进展与挑战
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 遥感大模型 多模态融合 视觉模型 深度学习 遥感图像解译
📋 核心要点
- 遥感数据复杂异构,传统方法难以有效融合多源信息,限制了智能解译能力。
- 综述聚焦视觉和多模态遥感大模型,探讨其架构、训练方法和应用场景。
- 分析数据对齐、跨模态迁移学习等挑战,并展望未来研究方向,旨在推动实际应用。
📝 摘要(中文)
遥感领域大模型,特别是视觉和多模态模型,显著提升了智能地理空间数据解译的能力。这些模型结合了光学、雷达和LiDAR图像等多种数据模态,以及文本和地理信息,从而能够对遥感数据进行更全面的分析和理解。多模态的融合提高了目标检测、土地覆盖分类和变化检测等任务的性能,这些任务通常受到遥感数据复杂性和异构性的挑战。然而,仍然存在一些挑战,如数据类型的多样性、大规模标注数据集的需求以及多模态融合技术的复杂性。此外,训练和微调多模态模型的计算需求很高,进一步复杂化了它们在遥感图像解译任务中的实际应用。本文全面回顾了遥感领域视觉和多模态大模型的最新进展,重点关注它们的架构、训练方法、数据集和应用场景。我们讨论了这些模型面临的关键挑战,如数据对齐、跨模态迁移学习和可扩展性,同时确定了旨在克服这些限制的新兴研究方向。我们的目标是清晰地了解遥感大模型的当前格局,并激发未来的研究,从而推动这些模型在实际应用中能够实现的边界。
🔬 方法详解
问题定义:遥感图像解译面临数据异构性、标注数据稀缺以及计算资源限制等问题。传统方法难以有效融合多源遥感数据,且泛化能力不足,限制了在复杂场景下的应用。因此,如何构建能够有效利用多模态遥感数据,并具备良好泛化能力的大模型是当前研究的重点。
核心思路:论文的核心思路是对现有遥感领域视觉和多模态大模型进行全面的梳理和分析,总结其在架构设计、训练策略、数据利用等方面的特点,并深入探讨其面临的挑战和未来的发展趋势。通过对现有方法的归纳和比较,为研究人员提供一个清晰的遥感大模型发展蓝图,从而促进相关技术的创新和应用。
技术框架:该综述论文主要通过以下几个方面展开:首先,对遥感领域常用的数据集进行整理和归纳;其次,详细介绍了各种视觉和多模态遥感大模型的架构,包括其核心模块和设计理念;然后,对这些模型的训练方法进行了深入的分析,包括预训练、微调等策略;最后,对这些模型在各种遥感应用场景下的表现进行了评估,并总结了其优势和不足。
关键创新:该综述的关键创新在于其对遥感领域大模型的全面性和深度。它不仅涵盖了视觉模型,还包括了多模态模型,并对这些模型的技术细节和应用场景进行了深入的分析。此外,该综述还对遥感大模型面临的挑战和未来的发展趋势进行了展望,为研究人员提供了有价值的参考。
关键设计:该综述的关键设计在于其结构化的组织方式和清晰的表达。通过对遥感大模型进行分类和归纳,并对其技术细节进行详细的描述,使得读者能够快速了解该领域的研究进展。此外,该综述还使用了大量的图表和案例,使得内容更加生动和易于理解。
🖼️ 关键图片
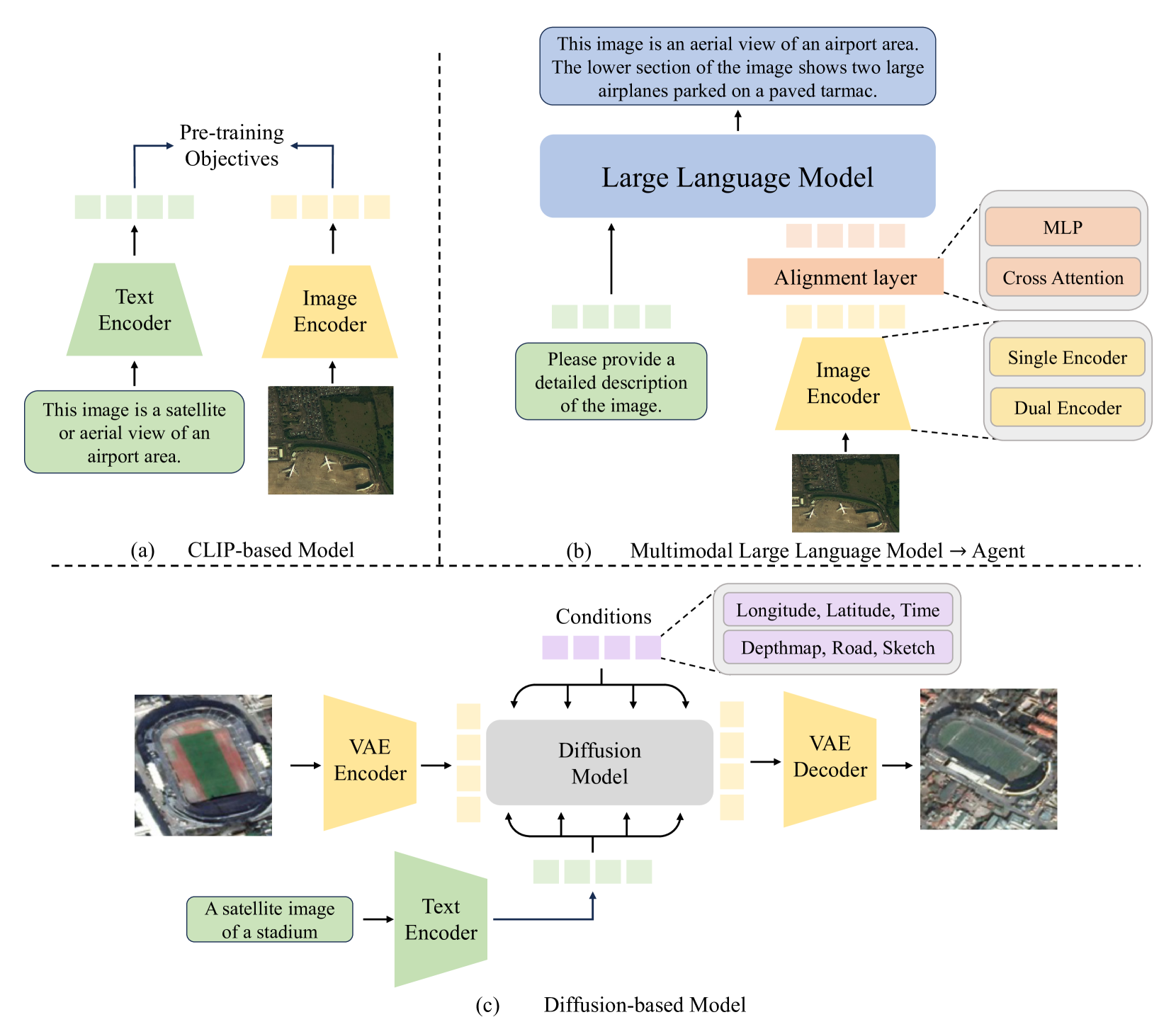
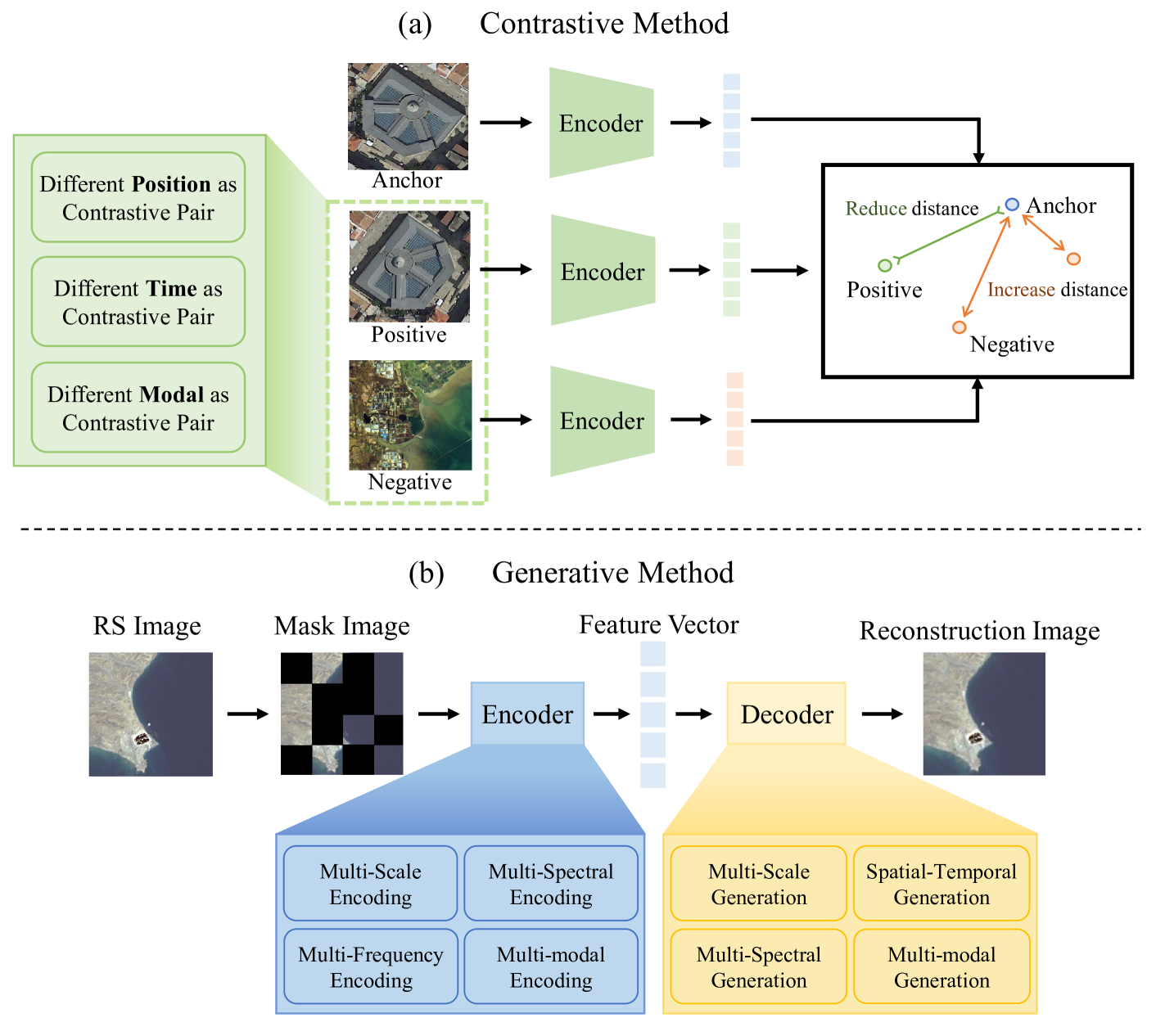
📊 实验亮点
该综述全面梳理了遥感领域视觉和多模态大模型的最新进展,深入分析了现有模型的架构、训练方法和应用场景,并指出了当前研究面临的挑战和未来的发展方向。该综述为遥感领域的研究人员提供了一个宝贵的资源,有助于推动相关技术的创新和应用。
🎯 应用场景
该研究对遥感图像智能解译具有重要意义,可应用于精准农业、城市规划、灾害监测、环境评估等领域。通过提升遥感数据分析的自动化和智能化水平,能够为决策提供更准确、及时的信息支持,助力可持续发展。
📄 摘要(原文)
The rapid advancement of remote sensing foundation models, particularly vision and multimodal models, has significantly enhanced the capabilities of intelligent geospatial data interpretation. These models combine various data modalities, such as optical, radar, and LiDAR imagery, with textual and geographic information, enabling more comprehensive analysis and understanding of remote sensing data. The integration of multiple modalities allows for improved performance in tasks like object detection, land cover classification, and change detection, which are often challenged by the complex and heterogeneous nature of remote sensing data. However, despite these advancements, several challenges remain. The diversity in data types, the need for large-scale annotated datasets, and the complexity of multimodal fusion techniques pose significant obstacles to the effective deployment of these models. Moreover, the computational demands of training and fine-tuning multimodal models require significant resources, further complicating their practical application in remote sensing image interpretation tasks. This paper provides a comprehensive review of the state-of-the-art in vision and multimodal foundation models for remote sensing, focusing on their architecture, training methods, datasets and application scenarios. We discuss the key challenges these models face, such as data alignment, cross-modal transfer learning, and scalability, while also identifying emerging research directions aimed at overcoming these limitations. Our goal is to provide a clear understanding of the current landscape of remote sensing foundation models and inspire future research that can push the boundaries of what these models can achieve in real-world applications. The list of resources collected by the paper can be found in the https://github.com/IRIP-BUAA/A-Review-for-remote-sensing-vision-language-models.