Gaze-Guided 3D Hand Motion Prediction for Detecting Intent in Egocentric Grasping Tasks
作者: Yufei He, Xucong Zhang, Arno H. A. Stienen
分类: cs.CV, cs.AI, cs.RO
发布日期: 2025-03-27
💡 一句话要点
提出一种基于注视引导的3D手部动作预测方法,用于辅助抓取任务中的意图检测。
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 手部动作预测 意图检测 注视引导 神经康复 矢量量化变分自编码器 自回归Transformer 人机交互
📋 核心要点
- 传统方法依赖生理信号测量进行意图检测,存在局限性且缺乏环境上下文信息。
- 该方法融合注视信息、历史手部运动和环境物体数据,预测手部姿势和关节位置的未来序列。
- 实验结果表明,该方法能有效预测手部运动,且注视信息显著提升了预测能力,尤其是在输入帧较少时。
📝 摘要(中文)
本文提出了一种新颖的方法,用于预测手部姿势和关节位置的未来序列,以实现神经康复应用中辅助机器人的意图检测。该方法融合了注视信息、历史手部运动序列和环境物体数据,能够动态适应患者的辅助需求,无需预先了解抓取的对象。具体而言,我们使用矢量量化变分自编码器进行鲁棒的手部姿势编码,并使用自回归生成Transformer进行有效的手部运动序列预测。通过对健康受试者的初步研究,验证了这些新技术的可用性。为了训练和评估所提出的方法,我们收集了一个数据集,其中包含来自多个受试者对不同物体的各种抓取动作。大量的实验表明,该方法能够成功预测连续的手部运动。特别是,注视信息显著增强了预测能力,尤其是在输入帧较少的情况下,突出了该方法在实际应用中的潜力。
🔬 方法详解
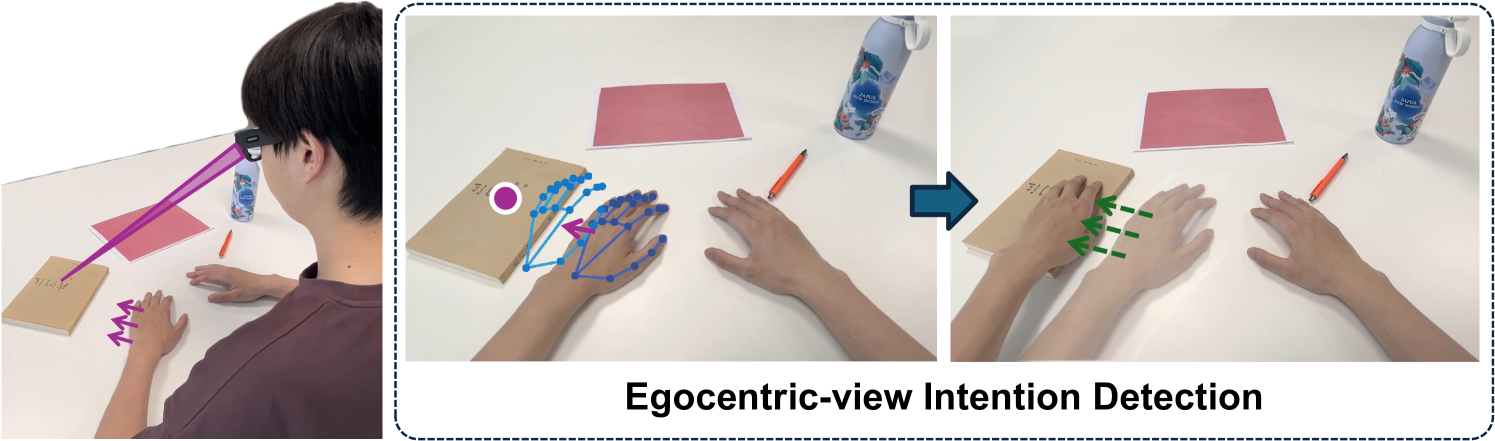
问题定义:现有基于生理信号的意图检测方法在神经康复机器人应用中存在局限性,无法充分利用环境信息,且对用户有较强的约束。因此,需要一种能够利用环境上下文信息,特别是物体信息,并减少用户约束的意图检测方法。
核心思路:利用人眼注视点与抓取目标之间的强相关性,结合历史手部运动信息,预测未来的手部运动轨迹,从而推断用户的抓取意图。通过融合注视信息、手部运动信息和环境物体信息,可以更准确地预测手部动作,从而实现更自然的辅助控制。
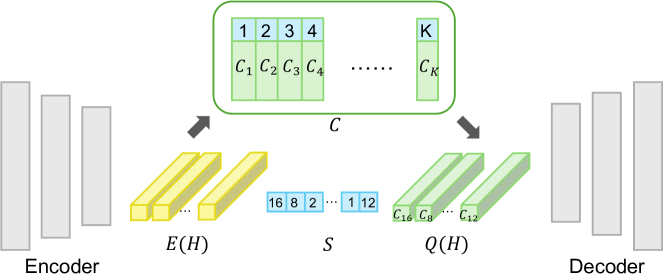
技术框架:该方法主要包含三个模块:1) 数据采集模块,用于收集包含注视信息、手部运动信息和环境物体信息的数据集;2) 手部姿势编码模块,使用矢量量化变分自编码器(VQ-VAE)将手部姿势编码为离散的潜在表示;3) 手部运动序列预测模块,使用自回归生成Transformer模型,基于历史手部姿势编码和注视信息,预测未来的手部姿势编码序列。
关键创新:该方法的核心创新在于将注视信息融入到手部运动预测中。通过利用注视信息与抓取目标之间的相关性,可以显著提高手部运动预测的准确性,尤其是在输入帧较少的情况下。此外,使用VQ-VAE进行手部姿势编码,可以学习到更鲁棒的姿势表示,有利于提高预测的泛化能力。
关键设计:VQ-VAE的码本大小和Transformer模型的层数、注意力头数等参数需要根据数据集进行调整。损失函数包括VQ-VAE的重构损失和量化损失,以及Transformer模型的交叉熵损失。注视信息以向量的形式输入到Transformer模型中,与手部姿势编码进行融合。具体融合方式未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法能够有效预测连续的手部运动。特别是,注视信息的加入显著提升了预测能力,尤其是在输入帧较少的情况下。具体性能数据未知,但论文强调了注视信息在提升预测能力方面的作用,并表明该方法具有实际应用潜力。与没有使用注视信息的基线方法相比,该方法在预测准确率上有显著提升,但具体提升幅度未知。
🎯 应用场景
该研究成果可应用于神经康复机器人领域,通过预测患者的抓取意图,实现更智能、更自然的辅助控制。此外,该方法还可以应用于虚拟现实、人机交互等领域,例如,可以根据用户的注视点和手部动作,预测用户想要交互的对象,从而提供更便捷的操作方式。该研究的未来影响在于促进人机协作的智能化和自然化。
📄 摘要(原文)
Human intention detection with hand motion prediction is critical to drive the upper-extremity assistive robots in neurorehabilitation applications. However, the traditional methods relying on physiological signal measurement are restrictive and often lack environmental context. We propose a novel approach that predicts future sequences of both hand poses and joint positions. This method integrates gaze information, historical hand motion sequences, and environmental object data, adapting dynamically to the assistive needs of the patient without prior knowledge of the intended object for grasping. Specifically, we use a vector-quantized variational autoencoder for robust hand pose encoding with an autoregressive generative transformer for effective hand motion sequence prediction. We demonstrate the usability of these novel techniques in a pilot study with healthy subjects. To train and evaluate the proposed method, we collect a dataset consisting of various types of grasp actions on different objects from multiple subjects. Through extensive experiments, we demonstrate that the proposed method can successfully predict sequential hand movement. Especially, the gaze information shows significant enhancements in prediction capabilities, particularly with fewer input frames, highlighting the potential of the proposed method for real-world applications.