Video-R1: Reinforcing Video Reasoning in MLLMs
作者: Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Junfei Wu, Xiaoying Zhang, Benyou Wang, Xiangyu Yue
分类: cs.CV
发布日期: 2025-03-27 (更新: 2025-10-22)
备注: NeurIPS 2025, Project page: https://github.com/tulerfeng/Video-R1
🔗 代码/项目: GITHUB
💡 一句话要点
Video-R1:通过规则强化学习提升多模态大语言模型中的视频推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频推理 多模态大语言模型 强化学习 时间建模 规则强化学习 T-GRPO算法 视频理解
📋 核心要点
- 现有MLLM在视频推理方面面临挑战,主要体现在缺乏有效的时间建模能力和高质量训练数据的不足。
- Video-R1通过引入T-GRPO算法,鼓励模型利用视频中的时间信息进行推理,并结合图像推理数据来弥补视频数据的不足。
- 实验结果表明,Video-R1在多个视频推理和通用视频基准测试中取得了显著提升,甚至超越了GPT-4o在特定任务上的表现。
📝 摘要(中文)
受DeepSeek-R1通过规则强化学习(RL)激发推理能力的启发,我们推出了Video-R1,首次尝试系统性地探索R1范式,以激励多模态大语言模型(MLLM)中的视频推理。然而,直接应用带有GRPO算法的RL训练到视频推理面临两个主要挑战:(i)缺乏视频推理的时间建模,以及(ii)高质量视频推理数据的稀缺。为了解决这些问题,我们首先提出了T-GRPO算法,该算法鼓励模型利用视频中的时间信息进行推理。此外,我们没有仅仅依赖视频数据,而是将高质量的图像推理数据纳入训练过程。我们构建了两个数据集:Video-R1-CoT-165k用于SFT冷启动,Video-R1-260k用于RL训练,两者都包含图像和视频数据。实验结果表明,Video-R1在视频推理基准测试(如VideoMMMU和VSI-Bench)以及通用视频基准测试(包括MVBench和TempCompass等)上取得了显著改进。值得注意的是,Video-R1-7B在视频空间推理基准测试VSI-bench上达到了37.1%的准确率,超过了商业专有模型GPT-4o。
🔬 方法详解
问题定义:现有的多模态大语言模型(MLLM)在处理视频推理任务时,面临着两个主要的痛点。一是缺乏有效的时间建模能力,无法充分利用视频中的时间信息进行推理。二是高质量的视频推理数据非常稀缺,限制了模型的训练效果。直接将现有的强化学习方法应用于视频推理,效果并不理想。
核心思路:Video-R1的核心思路是通过规则强化学习(RL)来激励MLLM进行视频推理,并针对现有方法的不足进行改进。具体来说,通过引入T-GRPO算法来增强模型的时间建模能力,并结合图像推理数据来缓解视频数据稀缺的问题。这样设计的目的是为了让模型能够更好地理解视频内容,并进行准确的推理。
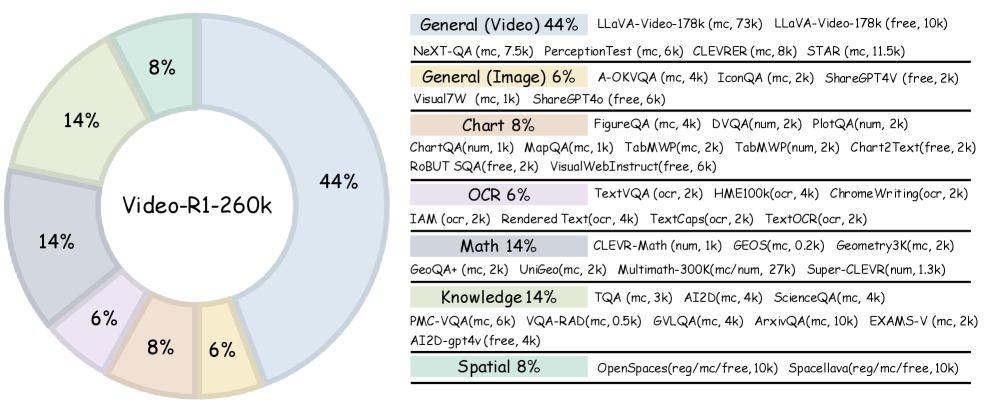
技术框架:Video-R1的整体框架包括以下几个主要部分:首先,使用Video-R1-CoT-165k数据集进行监督微调(SFT),为模型提供一个良好的冷启动。然后,使用Video-R1-260k数据集进行强化学习训练,其中使用了T-GRPO算法。T-GRPO算法在标准的GRPO算法的基础上,引入了时间建模的机制。此外,训练过程中还使用了图像推理数据,以提高模型的泛化能力。
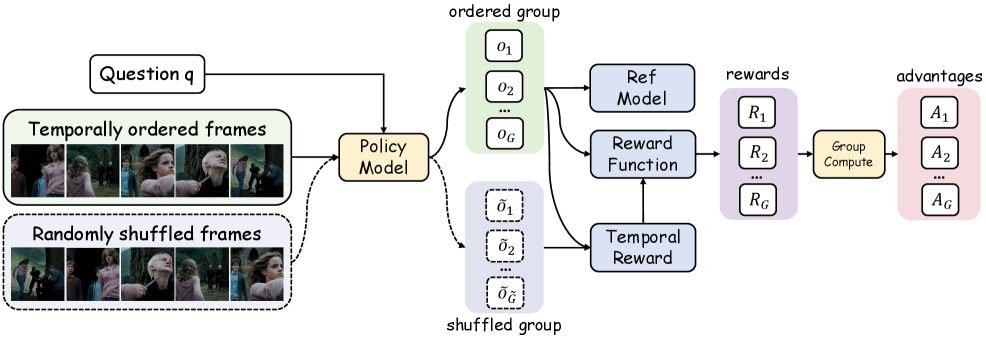
关键创新:Video-R1最重要的技术创新点在于T-GRPO算法。T-GRPO算法通过鼓励模型利用视频中的时间信息进行推理,从而提高了模型在视频推理任务上的性能。与现有的方法相比,T-GRPO算法能够更好地捕捉视频中的动态信息,并进行更准确的推理。此外,结合图像推理数据进行训练也是一个重要的创新点,可以有效地缓解视频数据稀缺的问题。
关键设计:T-GRPO算法的关键设计在于如何有效地利用视频中的时间信息。具体来说,T-GRPO算法通过引入时间注意力机制,让模型能够关注视频中不同时间点的信息,并进行加权融合。此外,在损失函数的设计上,T-GRPO算法也考虑了时间因素,使得模型能够更好地学习视频中的时间依赖关系。数据集方面,Video-R1-CoT-165k和Video-R1-260k的构建也至关重要,保证了模型能够学习到高质量的视频和图像推理知识。
🖼️ 关键图片

📊 实验亮点
Video-R1在多个视频推理和通用视频基准测试中取得了显著的提升。例如,在视频空间推理基准测试VSI-bench上,Video-R1-7B达到了37.1%的准确率,超越了商业专有模型GPT-4o。此外,在VideoMMMU、MVBench和TempCompass等基准测试中,Video-R1也取得了显著的改进,证明了其在视频推理方面的优越性能。
🎯 应用场景
Video-R1的研究成果具有广泛的应用前景,例如智能监控、视频内容分析、自动驾驶等领域。它可以用于识别视频中的异常行为、理解视频内容、辅助自动驾驶系统进行决策。未来,Video-R1有望成为多模态大语言模型在视频理解领域的重要组成部分,推动相关技术的发展。
📄 摘要(原文)
Inspired by DeepSeek-R1's success in eliciting reasoning abilities through rule-based reinforcement learning (RL), we introduce Video-R1 as the first attempt to systematically explore the R1 paradigm for incentivizing video reasoning within multimodal large language models (MLLMs). However, directly applying RL training with the GRPO algorithm to video reasoning presents two primary challenges: (i) a lack of temporal modeling for video reasoning, and (ii) the scarcity of high-quality video-reasoning data. To address these issues, we first propose the T-GRPO algorithm, which encourages models to utilize temporal information in videos for reasoning. Additionally, instead of relying solely on video data, we incorporate high-quality image-reasoning data into the training process. We have constructed two datasets: Video-R1-CoT-165k for SFT cold start and Video-R1-260k for RL training, both comprising image and video data. Experimental results demonstrate that Video-R1 achieves significant improvements on video reasoning benchmarks such as VideoMMMU and VSI-Bench, as well as on general video benchmarks including MVBench and TempCompass, etc. Notably, Video-R1-7B attains a 37.1% accuracy on video spatial reasoning benchmark VSI-bench, surpassing the commercial proprietary model GPT-4o. All code, models, and data are released in: https://github.com/tulerfeng/Video-R1.