ICG-MVSNet: Learning Intra-view and Cross-view Relationships for Guidance in Multi-View Stereo
作者: Yuxi Hu, Jun Zhang, Zhe Zhang, Rafael Weilharter, Yuchen Rao, Kuangyi Chen, Runze Yuan, Friedrich Fraundorfer
分类: cs.CV
发布日期: 2025-03-27
💡 一句话要点
ICG-MVSNet:学习视图内和跨视图关系以指导多视图立体匹配
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 多视图立体匹配 深度估计 视图内关系 跨视图关系 几何信息 特征融合 三维重建
📋 核心要点
- 现有基于学习的MVS方法忽略了特征中的几何信息,导致成本匹配不准确,这是深度估计的瓶颈。
- ICG-MVSNet通过显式地建模视图内特征相关性和跨视图上下文关系,来提升深度估计的准确性和鲁棒性。
- 实验表明,ICG-MVSNet在DTU和Tanks and Temples数据集上取得了有竞争力的性能,同时降低了计算成本。
📝 摘要(中文)
本文提出ICG-MVSNet,旨在解决多视图立体匹配(MVS)中,现有基于学习的方法忽略特征和相关性中嵌入的几何信息,导致成本匹配较弱的问题。ICG-MVSNet显式地整合了视图内和跨视图关系以进行深度估计。具体而言,我们开发了一个视图内特征融合模块,该模块利用单个图像内的特征坐标相关性来增强鲁棒的成本匹配。此外,我们引入了一个轻量级的跨视图聚合模块,该模块有效地利用来自体相关性的上下文信息来指导正则化。在DTU数据集和Tanks and Temples基准测试上的评估结果表明,我们的方法始终如一地实现了与最先进方法相比具有竞争力的性能,同时需要更低的计算资源。
🔬 方法详解
问题定义:多视图立体匹配(MVS)旨在从一系列重叠图像中估计深度并重建3D点云。现有基于学习的MVS方法在成本匹配方面存在不足,因为它们忽略了特征和相关性中嵌入的几何信息,导致深度估计精度受限。
核心思路:ICG-MVSNet的核心思路是显式地建模和利用视图内和跨视图的几何关系,从而指导更准确的成本匹配和深度估计。通过增强特征的几何感知能力,可以提高MVS的鲁棒性和准确性。
技术框架:ICG-MVSNet主要包含以下几个模块:1) 特征提取模块:从输入图像中提取特征。2) 视图内特征融合模块:利用单个图像内的特征坐标相关性来增强特征表示。3) 跨视图聚合模块:利用体相关性的上下文信息来指导正则化。4) 深度图估计模块:基于聚合后的特征体进行深度图估计。
关键创新:ICG-MVSNet的关键创新在于同时考虑了视图内和跨视图的关系。视图内特征融合模块通过学习特征坐标相关性,增强了特征的几何感知能力。跨视图聚合模块则利用体相关性的上下文信息,指导深度图的正则化,从而提高深度估计的准确性。与现有方法相比,ICG-MVSNet更有效地利用了图像中的几何信息。
关键设计:视图内特征融合模块的具体实现方式未知,但其核心思想是利用特征坐标相关性。跨视图聚合模块采用轻量级设计,以降低计算成本。损失函数的设计也未知,但通常会包含深度图的平滑项和一致性约束。
🖼️ 关键图片


📊 实验亮点
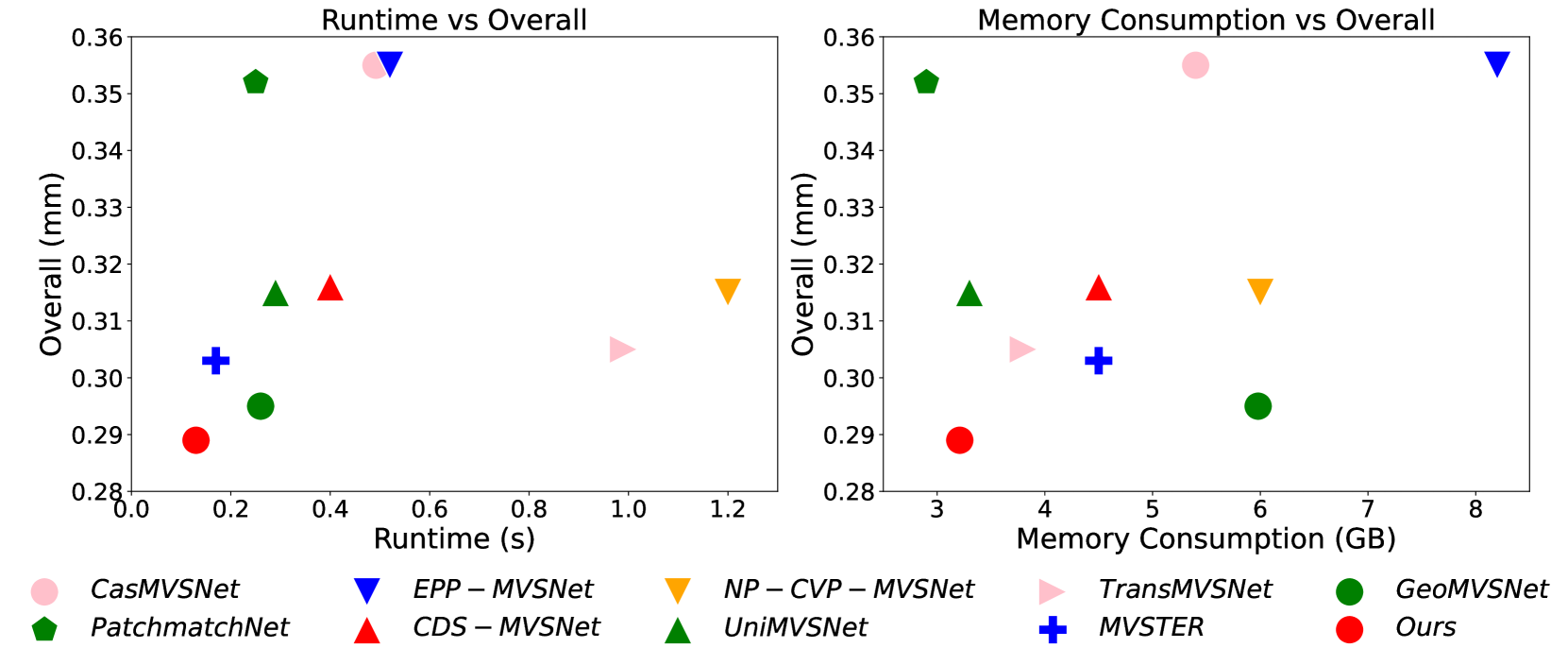
ICG-MVSNet在DTU数据集和Tanks and Temples基准测试上进行了评估,结果表明其性能与最先进的方法具有竞争力。更重要的是,ICG-MVSNet在保持竞争力的同时,降低了计算资源的需求,使其更适用于实际应用。具体的性能提升幅度未知,但摘要中强调了其“competitive performance”和“lower computational resources”。
🎯 应用场景
ICG-MVSNet可应用于三维重建、自动驾驶、机器人导航、虚拟现实等领域。通过提高深度估计的准确性和效率,可以改善这些应用中的三维场景理解和交互能力。未来,该方法可以进一步扩展到更大规模、更复杂的场景,并与其他感知技术相结合,实现更强大的三维感知系统。
📄 摘要(原文)
Multi-view Stereo (MVS) aims to estimate depth and reconstruct 3D point clouds from a series of overlapping images. Recent learning-based MVS frameworks overlook the geometric information embedded in features and correlations, leading to weak cost matching. In this paper, we propose ICG-MVSNet, which explicitly integrates intra-view and cross-view relationships for depth estimation. Specifically, we develop an intra-view feature fusion module that leverages the feature coordinate correlations within a single image to enhance robust cost matching. Additionally, we introduce a lightweight cross-view aggregation module that efficiently utilizes the contextual information from volume correlations to guide regularization. Our method is evaluated on the DTU dataset and Tanks and Temples benchmark, consistently achieving competitive performance against state-of-the-art works, while requiring lower computational resources.