VALLR: Visual ASR Language Model for Lip Reading
作者: Marshall Thomas, Edward Fish, Richard Bowden
分类: cs.CV
发布日期: 2025-03-27 (更新: 2026-01-05)
💡 一句话要点
VALLR:提出视觉ASR语言模型,用于唇语识别,显著降低词错误率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 唇语识别 视觉语音识别 音素识别 视频Transformer 语言模型
📋 核心要点
- 现有唇语识别方法在处理协同发音和视觉相似音素的歧义性时,错误率较高,缺乏有效的中间语言结构编码。
- 论文提出VALLR模型,通过视频Transformer预测音素序列,再利用大型语言模型重建单词和句子,显式编码中间语言结构。
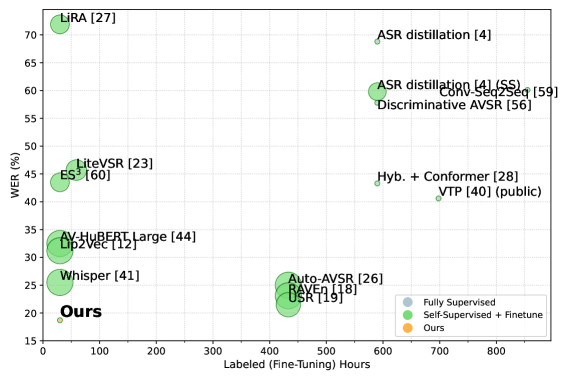
- 实验结果表明,VALLR在LRS2和LRS3数据集上取得了SOTA性能,显著降低了词错误率,并具有更高的数据效率。
📝 摘要(中文)
本文提出了一种新颖的两阶段、以音素为中心的视觉自动语音识别(V-ASR)框架,旨在解决唇语识别中的长期挑战。该模型首先使用带有CTC头的视频Transformer从视觉输入中预测一个紧凑的音素序列,从而降低任务复杂性并实现鲁棒的说话人不变性。然后,该音素输出作为微调的大型语言模型(LLM)的输入,利用更广泛的语言上下文重建连贯的单词和句子。与直接预测单词(容易在视觉上相似的音素上出错)或依赖大规模多模态预训练的现有方法不同,我们的方法显式地编码了中间语言结构,同时保持了高度的数据效率。在LRS2和LRS3两个具有挑战性的数据集上,我们的方法表现出最先进的性能,在词错误率(WER)方面取得了显著降低,在LRS3上实现了18.7的SOTA WER,同时使用的数据比次优方法少99.4%。
🔬 方法详解
问题定义:唇语识别(V-ASR)旨在仅通过视觉线索(如嘴唇运动和面部表情)来理解口语。现有方法直接从视觉信息预测单词或字符,但由于协同发音效应和视觉相似音素的歧义性,导致错误率较高。这些方法通常难以有效捕捉和利用语音的中间语言结构。
核心思路:论文的核心思路是将唇语识别任务分解为两个阶段:首先,从视觉输入中预测音素序列;然后,利用大型语言模型(LLM)将音素序列转换为连贯的单词和句子。这种分解降低了任务的复杂性,并允许模型显式地编码中间语言结构,从而更好地处理视觉歧义和协同发音。
技术框架:VALLR模型包含两个主要模块:1) 视频Transformer + CTC:该模块接收视觉输入(视频帧),并使用视频Transformer提取视觉特征。然后,CTC(Connectionist Temporal Classification)头用于将这些特征映射到音素序列。2) 微调的LLM:该模块接收音素序列作为输入,并利用其语言建模能力重建单词和句子。LLM经过微调,以更好地适应唇语识别任务。
关键创新:VALLR的关键创新在于其两阶段的音素中心方法。与直接预测单词的现有方法不同,VALLR显式地编码了中间语言结构,这使得模型能够更好地处理视觉歧义和协同发音。此外,VALLR不需要大规模的多模态预训练,因此具有更高的数据效率。
关键设计:视频Transformer使用标准的Transformer架构,并针对视频输入进行了优化。CTC损失函数用于训练视频Transformer,以将视觉特征映射到音素序列。LLM使用预训练的语言模型(例如,BERT或GPT),并使用唇语识别数据进行微调。具体的参数设置和网络结构细节在论文中有详细描述,但摘要中未明确给出。
🖼️ 关键图片

📊 实验亮点
VALLR模型在LRS3数据集上取得了18.7%的SOTA WER,显著优于现有方法。更重要的是,VALLR在实现这一性能的同时,使用的数据量比次优方法少了99.4%,展示了其卓越的数据效率。这些实验结果表明,VALLR是一种有效的唇语识别方法,具有很强的实用价值。
🎯 应用场景
VALLR模型在多种场景下具有潜在应用价值,例如在嘈杂环境中或对于听力受损人士的语音辅助设备,以及在安全监控和视频会议等需要理解无声语音的领域。该研究的未来影响在于推动唇语识别技术的发展,提高人机交互的自然性和便利性。
📄 摘要(原文)
Lip Reading, or Visual Automatic Speech Recognition (V-ASR), is a complex task requiring the interpretation of spoken language exclusively from visual cues, primarily lip movements and facial expressions. This task is especially challenging due to the absence of auditory information and the inherent ambiguity when visually distinguishing phonemes that have overlapping visemes where different phonemes appear identical on the lips. Current methods typically attempt to predict words or characters directly from these visual cues, but this approach frequently encounters high error rates due to coarticulation effects and viseme ambiguity. We propose a novel two-stage, phoneme-centric framework for Visual Automatic Speech Recognition (V-ASR) that addresses these longstanding challenges. First, our model predicts a compact sequence of phonemes from visual inputs using a Video Transformer with a CTC head, thereby reducing the task complexity and achieving robust speaker invariance. This phoneme output then serves as the input to a fine-tuned Large Language Model (LLM), which reconstructs coherent words and sentences by leveraging broader linguistic context. Unlike existing methods that either predict words directly-often faltering on visually similar phonemes-or rely on large-scale multimodal pre-training, our approach explicitly encodes intermediate linguistic structure while remaining highly data efficient. We demonstrate state-of-the-art performance on two challenging datasets, LRS2 and LRS3, where our method achieves significant reductions in Word Error Rate (WER) achieving a SOTA WER of 18.7 on LRS3 despite using 99.4% less labelled data than the next best approach.