FineCIR: Explicit Parsing of Fine-Grained Modification Semantics for Composed Image Retrieval
作者: Zixu Li, Zhiheng Fu, Yupeng Hu, Zhiwei Chen, Haokun Wen, Liqiang Nie
分类: cs.CV, cs.AI
发布日期: 2025-03-27
🔗 代码/项目: GITHUB
💡 一句话要点
提出FineCIR框架,通过显式解析细粒度语义提升组合图像检索精度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 组合图像检索 细粒度语义 图像文本对齐 Transformer 数据标注
📋 核心要点
- 现有组合图像检索数据集使用粗粒度修改文本,无法准确捕捉细粒度的检索意图,导致检索精度下降。
- 论文提出FineCIR框架,显式解析修改文本,捕获细粒度语义,并将其与视觉实体对齐,提升检索精度。
- 实验结果表明,FineCIR在细粒度和传统CIR数据集上均优于现有方法,验证了其有效性。
📝 摘要(中文)
组合图像检索(CIR)通过包含参考图像和修改文本的多模态查询来实现图像检索。参考图像定义了检索上下文,而修改文本指定了所需的更改。然而,现有的CIR数据集主要采用粗粒度的修改文本(CoarseMT),这不足以捕捉细粒度的检索意图。这种局限性带来了两个关键挑战:(1)忽略详细差异导致不精确的正样本,以及(2)在检索视觉上相似的图像时产生更大的歧义。这些问题降低了检索精度,需要手动过滤结果或重复查询。为了解决这些限制,我们开发了一个强大的细粒度CIR数据标注流程,该流程最大限度地减少了不精确的正样本,并增强了CIR系统准确辨别修改意图的能力。使用此流程,我们改进了FashionIQ和CIRR数据集,创建了两个细粒度的CIR数据集:Fine-FashionIQ和Fine-CIRR。此外,我们引入了FineCIR,这是第一个显式设计用于解析修改文本的CIR框架。FineCIR有效地捕获细粒度的修改语义,并将它们与模糊的视觉实体对齐,从而提高检索精度。大量的实验表明,FineCIR在细粒度和传统的CIR基准数据集上始终优于最先进的CIR基线。
🔬 方法详解
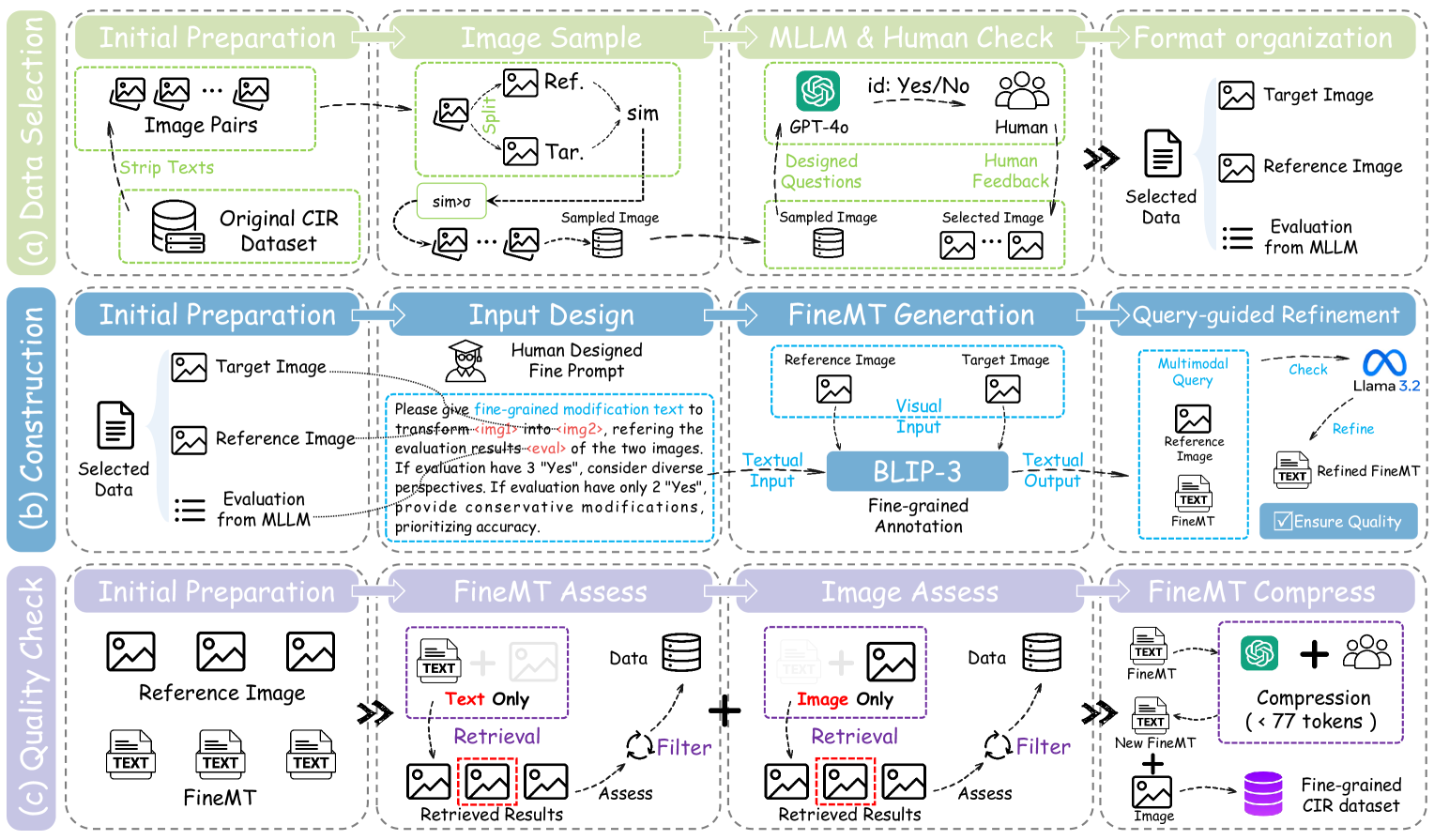
问题定义:现有组合图像检索方法依赖于粗粒度的修改文本,无法准确表达用户的细粒度检索意图。这导致模型难以区分相似图像之间的细微差别,从而降低检索精度。此外,不精确的正样本也进一步加剧了这一问题。
核心思路:论文的核心思路是显式地解析修改文本,提取细粒度的修改语义,并将其与图像中的视觉实体进行对齐。通过更精确地理解用户的修改意图,模型可以更准确地检索到目标图像。
技术框架:FineCIR框架主要包含以下几个模块:1) 细粒度数据标注流程,用于生成高质量的细粒度CIR数据集;2) 修改文本解析模块,用于提取细粒度的修改语义;3) 视觉实体对齐模块,用于将修改语义与图像中的视觉实体进行对齐;4) 检索模块,用于根据对齐后的语义信息进行图像检索。
关键创新:FineCIR的关键创新在于显式地解析修改文本,并将其与视觉实体进行对齐。与现有方法相比,FineCIR能够更准确地理解用户的修改意图,从而提高检索精度。此外,论文还提出了一个细粒度数据标注流程,为训练高质量的CIR模型提供了数据支持。
关键设计:在修改文本解析模块中,论文采用了基于Transformer的模型来提取细粒度的修改语义。在视觉实体对齐模块中,论文设计了一种注意力机制,用于将修改语义与图像中的视觉实体进行对齐。损失函数方面,使用了Triplet Loss来优化模型的检索性能。具体参数设置在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,FineCIR在Fine-FashionIQ和Fine-CIRR两个细粒度数据集上均取得了显著的性能提升。例如,在Fine-FashionIQ数据集上,FineCIR的Recall@1指标相比于最先进的基线方法提升了超过5%。此外,FineCIR在传统的FashionIQ和CIRR数据集上也取得了优于现有方法的结果,证明了其泛化能力。
🎯 应用场景
FineCIR框架可应用于电商平台的商品搜索、服装搭配推荐、室内设计等领域。通过理解用户对图像的细粒度修改意图,可以更准确地检索到用户所需的商品或图像,提升用户体验。该研究的未来影响在于推动组合图像检索技术的发展,使其能够更好地服务于实际应用。
📄 摘要(原文)
Composed Image Retrieval (CIR) facilitates image retrieval through a multimodal query consisting of a reference image and modification text. The reference image defines the retrieval context, while the modification text specifies desired alterations. However, existing CIR datasets predominantly employ coarse-grained modification text (CoarseMT), which inadequately captures fine-grained retrieval intents. This limitation introduces two key challenges: (1) ignoring detailed differences leads to imprecise positive samples, and (2) greater ambiguity arises when retrieving visually similar images. These issues degrade retrieval accuracy, necessitating manual result filtering or repeated queries. To address these limitations, we develop a robust fine-grained CIR data annotation pipeline that minimizes imprecise positive samples and enhances CIR systems' ability to discern modification intents accurately. Using this pipeline, we refine the FashionIQ and CIRR datasets to create two fine-grained CIR datasets: Fine-FashionIQ and Fine-CIRR. Furthermore, we introduce FineCIR, the first CIR framework explicitly designed to parse the modification text. FineCIR effectively captures fine-grained modification semantics and aligns them with ambiguous visual entities, enhancing retrieval precision. Extensive experiments demonstrate that FineCIR consistently outperforms state-of-the-art CIR baselines on both fine-grained and traditional CIR benchmark datasets. Our FineCIR code and fine-grained CIR datasets are available at https://github.com/SDU-L/FineCIR.git.