Reason-RFT: Reinforcement Fine-Tuning for Visual Reasoning of Vision Language Models
作者: Huajie Tan, Yuheng Ji, Xiaoshuai Hao, Xiansheng Chen, Pengwei Wang, Zhongyuan Wang, Shanghang Zhang
分类: cs.CV, cs.AI
发布日期: 2025-03-26 (更新: 2025-10-05)
备注: 51 pages, 23 figures, NeurIPS'25
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出Reason-RFT,通过强化微调提升视觉语言模型在视觉推理任务上的泛化能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉推理 强化学习 视觉语言模型 领域泛化 链式思考 群体相对策略优化 多模态学习
📋 核心要点
- 现有视觉推理方法依赖链式思考监督微调,易过拟合且泛化性差,限制了实际应用。
- Reason-RFT采用两阶段强化微调,先用CoT数据激活推理潜力,再用强化学习提升领域适应性。
- 实验表明,Reason-RFT在视觉推理任务上取得了SOTA结果,并在领域迁移和少样本学习中表现优异。
📝 摘要(中文)
本文提出Reason-RFT,一个用于视觉推理的两阶段强化微调框架,旨在克服现有方法中基于链式思考(CoT)监督微调的视觉语言模型(VLMs)存在的过拟合和认知僵化问题,从而提升模型在领域迁移下的泛化能力和实际应用性。该框架首先使用精选的CoT数据进行监督微调(SFT),激活VLMs的推理潜力,然后基于群体相对策略优化(GRPO)进行强化学习,生成多个推理-响应对,以增强对领域迁移的适应性。为了评估Reason-RFT,重建了一个综合数据集,涵盖视觉计数、结构感知和空间变换,作为跨三个关键维度的系统评估基准。实验结果表明,Reason-RFT在性能增强、泛化优越性和数据效率方面具有优势,并在少样本学习场景中表现出色,超越了全数据集SFT基线。
🔬 方法详解
问题定义:现有视觉语言模型在视觉推理任务中,依赖于链式思考(Chain-of-Thought, CoT)的监督微调。这种方法虽然可以提升模型在特定数据集上的性能,但容易导致过拟合,使得模型在面对领域迁移时表现不佳,泛化能力受限。此外,标注高质量的CoT数据成本高昂,限制了模型的实际应用。
核心思路:Reason-RFT的核心思路是通过强化学习来提升视觉语言模型在视觉推理任务中的泛化能力。具体来说,首先使用监督微调(SFT)来初始化模型,使其具备基本的推理能力。然后,利用强化学习,鼓励模型探索不同的推理路径,并根据最终结果的奖励来优化策略,从而提高模型对不同领域和任务的适应性。这种方法避免了对大量标注数据的依赖,并能够提升模型的鲁棒性。
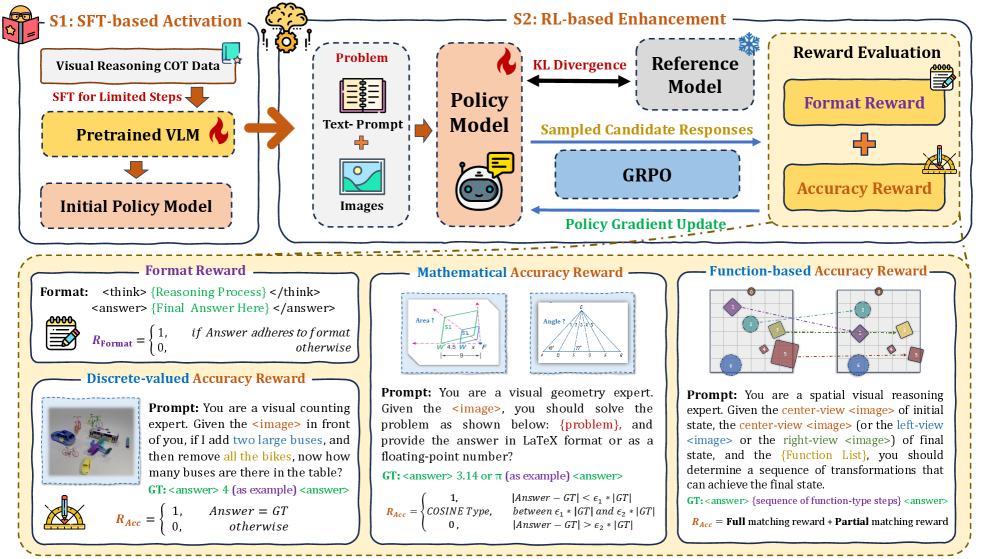
技术框架:Reason-RFT框架包含两个主要阶段:监督微调(SFT)和强化微调(RFT)。在SFT阶段,使用精选的CoT数据对视觉语言模型进行微调,使其初步具备视觉推理能力。在RFT阶段,使用群体相对策略优化(GRPO)算法进行强化学习。GRPO算法通过生成多个推理-响应对,并根据最终结果的奖励来更新策略,从而提升模型对领域迁移的适应性。整个框架的目标是训练出一个既具备强大的推理能力,又具有良好泛化能力的视觉语言模型。
关键创新:Reason-RFT的关键创新在于引入了强化学习来提升视觉语言模型在视觉推理任务中的泛化能力。与传统的监督微调方法相比,Reason-RFT能够鼓励模型探索不同的推理路径,并根据最终结果的奖励来优化策略,从而提高模型对不同领域和任务的适应性。此外,Reason-RFT使用了群体相对策略优化(GRPO)算法,该算法能够有效地利用多个推理-响应对的信息,从而提升强化学习的效率。
关键设计:在SFT阶段,使用了精心挑选的CoT数据,以确保模型能够学习到高质量的推理过程。在RFT阶段,使用了群体相对策略优化(GRPO)算法,该算法通过生成多个推理-响应对,并根据最终结果的奖励来更新策略。奖励函数的设计至关重要,它需要能够准确地反映推理结果的质量。此外,还使用了合适的探索策略,以鼓励模型探索不同的推理路径。具体的参数设置和网络结构细节未在摘要中详细说明,需要参考论文全文。
🖼️ 关键图片


📊 实验亮点
Reason-RFT在视觉计数、结构感知和空间变换等任务上取得了state-of-the-art的结果,超越了现有的开源和商业模型。在领域迁移实验中,Reason-RFT表现出更强的鲁棒性。此外,在少样本学习场景下,Reason-RFT也表现出色,甚至超越了使用全数据集进行监督微调的基线模型,证明了其数据效率。
🎯 应用场景
Reason-RFT在视觉推理方面具有广泛的应用前景,例如智能问答系统、图像理解、机器人导航等。该方法可以提升模型在复杂场景下的推理能力和泛化能力,从而提高系统的智能化水平。此外,Reason-RFT还可以应用于自动驾驶、医疗诊断等领域,为这些领域提供更可靠的视觉理解能力,具有重要的实际价值和未来影响。
📄 摘要(原文)
Visual reasoning abilities play a crucial role in understanding complex multimodal data, advancing both domain-specific applications and artificial general intelligence (AGI). Existing methods enhance Vision-Language Models (VLMs) through Chain-of-Thought (CoT) supervised fine-tuning using meticulously annotated data. However, this approach may lead to overfitting and cognitive rigidity, limiting the model's generalization ability under domain shifts and reducing real-world applicability. To overcome these limitations, we propose Reason-RFT, a two-stage reinforcement fine-tuning framework for visual reasoning. First, Supervised Fine-Tuning (SFT) with curated CoT data activates the reasoning potential of VLMs. This is followed by reinforcement learning based on Group Relative Policy Optimization (GRPO), which generates multiple reasoning-response pairs to enhance adaptability to domain shifts. To evaluate Reason-RFT, we reconstructed a comprehensive dataset covering visual counting, structural perception, and spatial transformation, serving as a benchmark for systematic assessment across three key dimensions. Experimental results highlight three advantages: (1) performance enhancement, with Reason-RFT achieving state-of-the-art results and outperforming both open-source and proprietary models; (2) generalization superiority, maintaining robust performance under domain shifts across various tasks; and (3) data efficiency, excelling in few-shot learning scenarios and surpassing full-dataset SFT baselines. Reason-RFT introduces a novel training paradigm for visual reasoning and marks a significant step forward in multimodal research. Project website: https://tanhuajie.github.io/ReasonRFT