UniSTD: Towards Unified Spatio-Temporal Learning across Diverse Disciplines
作者: Chen Tang, Xinzhu Ma, Encheng Su, Xiufeng Song, Xiaohong Liu, Wei-Hong Li, Lei Bai, Wanli Ouyang, Xiangyu Yue
分类: cs.CV
发布日期: 2025-03-26
备注: Accepted to CVPR 2025
🔗 代码/项目: GITHUB
💡 一句话要点
UniSTD:提出一种统一时空学习框架,解决跨领域任务泛化性问题。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时空学习 统一框架 Transformer 预训练 混合专家模型 跨任务学习 多领域应用
📋 核心要点
- 传统时空模型依赖于特定任务的架构,限制了其在不同任务中的泛化性和可扩展性,因为领域相关的设计需求各不相同。
- UniSTD框架通过在2D视觉和视觉-文本数据上进行预训练,构建通用模型基础,再在时空数据上进行联合训练,增强任务适应性。
- 该方法在包含10个任务的大规模数据集上进行了评估,证明了其跨任务学习能力,并降低了多领域应用的训练成本。
📝 摘要(中文)
本文提出UniSTD,一个基于Transformer的统一时空建模框架。该框架受到近期基础模型的启发,采用两阶段的预训练-适应范式。具体而言,本文证明了在2D视觉和视觉-文本数据集上进行任务无关的预训练,可以为时空学习构建一个通用的模型基础,然后通过在时空数据集上进行专门的联合训练,来增强任务特定的适应性。为了提高跨领域的学习能力,该框架采用秩自适应的混合专家适配,通过使用分数插值来放宽离散变量,从而可以在连续空间中进行优化。此外,还引入了一个时间模块来显式地结合时间动态。在涵盖4个学科的10个任务的大规模数据集上评估了该方法,结果表明,统一的时空模型可以实现可扩展的跨任务学习,并在一个模型中同时支持多达10个任务,同时降低多领域应用中的训练成本。
🔬 方法详解
问题定义:现有时空模型通常针对特定任务设计,缺乏通用性和跨领域适应性。不同领域和任务的时空数据特性差异大,导致模型难以在多个任务上同时取得良好性能。因此,如何设计一个通用的时空模型,使其能够适应不同领域的任务,是本文要解决的核心问题。
核心思路:UniSTD的核心思路是借鉴预训练-微调范式,通过在通用视觉和视觉-文本数据上进行预训练,学习通用的视觉和语言表征,然后通过在特定时空任务上进行微调,使模型适应特定任务的需求。此外,引入混合专家模型,增强模型的容量和表达能力,使其能够更好地适应不同领域的任务。
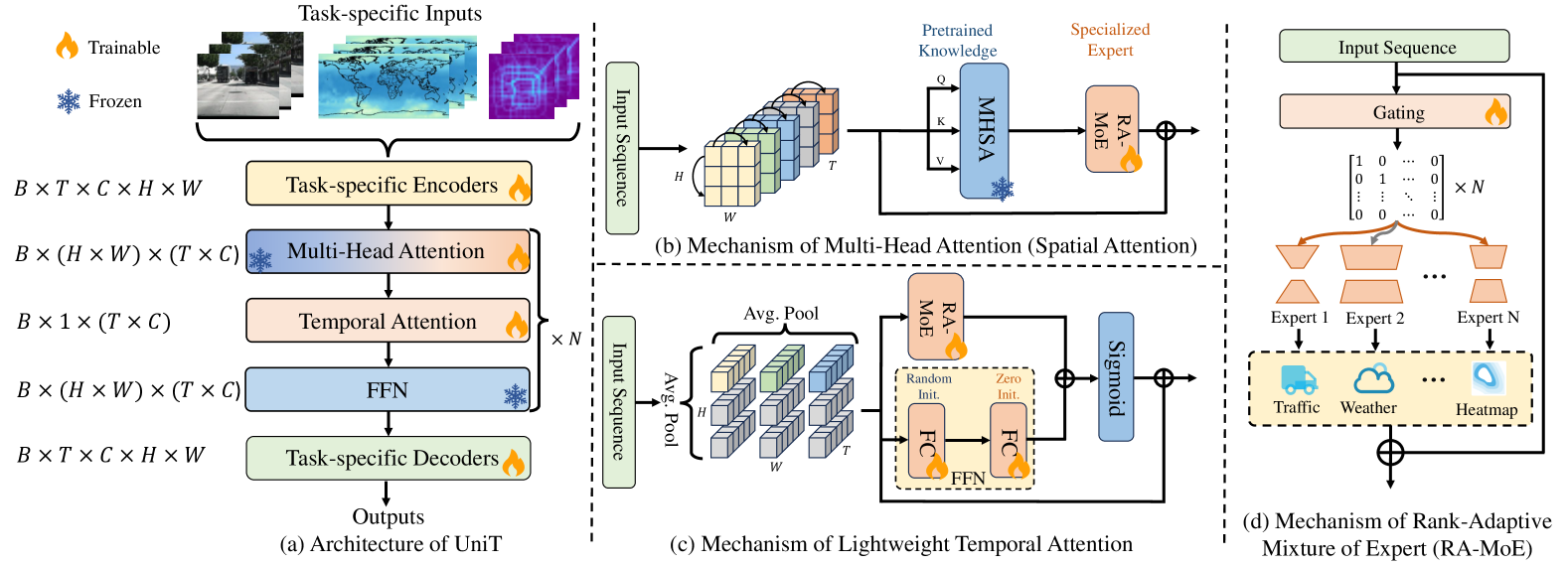
技术框架:UniSTD框架主要包含以下几个模块:1) 预训练阶段:在2D视觉和视觉-文本数据集上预训练Transformer模型,学习通用的视觉和语言表征。2) 时空建模阶段:引入时间模块,显式地建模时间动态。3) 混合专家适配:采用秩自适应的混合专家适配,增强模型的容量和表达能力。4) 微调阶段:在特定时空任务上微调模型,使其适应特定任务的需求。
关键创新:UniSTD的关键创新在于:1) 提出了一种统一的时空建模框架,可以适应不同领域的任务。2) 引入了秩自适应的混合专家适配,增强了模型的容量和表达能力。3) 采用预训练-微调范式,利用通用视觉和语言知识,提高了模型的泛化能力。
关键设计:在混合专家适配中,使用了分数插值来放宽离散变量,从而可以在连续空间中进行优化。时间模块的设计考虑了不同时间尺度的信息,采用了多层Transformer结构来建模时间动态。损失函数包括预训练损失、微调损失和混合专家适配的正则化损失。
🖼️ 关键图片

📊 实验亮点
UniSTD在包含10个任务的大规模数据集上进行了评估,结果表明,该模型可以实现可扩展的跨任务学习,并在一个模型中同时支持多达10个任务。相比于特定任务的模型,UniSTD在多个任务上取得了具有竞争力的性能,同时降低了多领域应用中的训练成本。具体性能提升数据未知。
🎯 应用场景
UniSTD具有广泛的应用前景,例如视频理解、行为识别、交通流量预测、气象预测等。该研究可以降低多领域应用中的模型开发和训练成本,加速时空智能在各个领域的落地。未来,可以进一步探索UniSTD在更多领域的应用,并研究如何更好地利用预训练知识来提高模型的性能。
📄 摘要(原文)
Traditional spatiotemporal models generally rely on task-specific architectures, which limit their generalizability and scalability across diverse tasks due to domain-specific design requirements. In this paper, we introduce \textbf{UniSTD}, a unified Transformer-based framework for spatiotemporal modeling, which is inspired by advances in recent foundation models with the two-stage pretraining-then-adaption paradigm. Specifically, our work demonstrates that task-agnostic pretraining on 2D vision and vision-text datasets can build a generalizable model foundation for spatiotemporal learning, followed by specialized joint training on spatiotemporal datasets to enhance task-specific adaptability. To improve the learning capabilities across domains, our framework employs a rank-adaptive mixture-of-expert adaptation by using fractional interpolation to relax the discrete variables so that can be optimized in the continuous space. Additionally, we introduce a temporal module to incorporate temporal dynamics explicitly. We evaluate our approach on a large-scale dataset covering 10 tasks across 4 disciplines, demonstrating that a unified spatiotemporal model can achieve scalable, cross-task learning and support up to 10 tasks simultaneously within one model while reducing training costs in multi-domain applications. Code will be available at https://github.com/1hunters/UniSTD.