VPO: Aligning Text-to-Video Generation Models with Prompt Optimization
作者: Jiale Cheng, Ruiliang Lyu, Xiaotao Gu, Xiao Liu, Jiazheng Xu, Yida Lu, Jiayan Teng, Zhuoyi Yang, Yuxiao Dong, Jie Tang, Hongning Wang, Minlie Huang
分类: cs.CV, cs.CL, cs.LG
发布日期: 2025-03-26 (更新: 2025-08-30)
备注: ICCV 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出VPO框架,通过提示优化对齐文本到视频生成模型,提升安全性与质量。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本到视频生成 提示优化 安全性对齐 偏好学习 监督微调
📋 核心要点
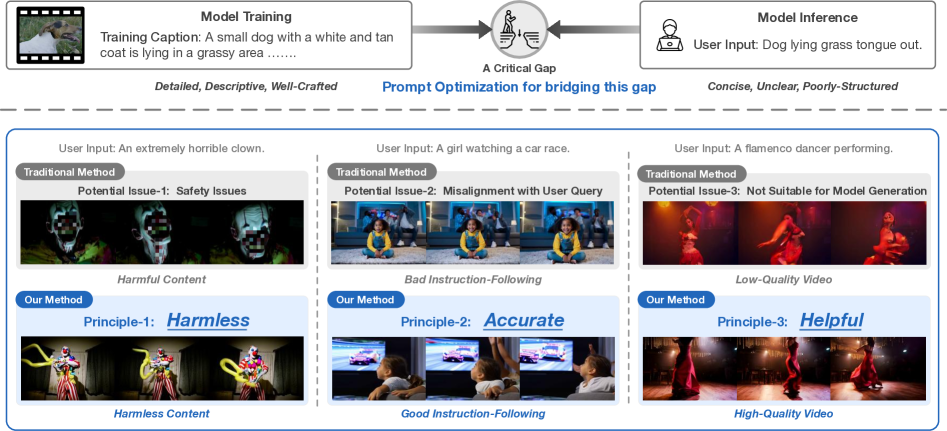
- 现有文本到视频生成模型在实际应用中,用户输入的prompt通常简洁模糊,与训练数据存在gap,导致生成质量下降。
- VPO框架通过无害性、准确性和有用性三大原则优化prompt,采用两阶段优化方法,提升生成视频的安全性和质量。
- 实验表明,VPO显著提升了生成视频的安全性、对齐性和质量,并在不同视频生成模型中表现出良好的泛化能力。
📝 摘要(中文)
视频生成模型在文本到视频任务中取得了显著进展。这些模型通常在具有高度详细和精心设计的描述的文本-视频对上进行训练,而现实世界中用户在推理期间的输入通常是简洁、模糊或结构不良的。这种差距使得提示优化对于生成高质量视频至关重要。目前的方法通常依赖于大型语言模型(LLM)通过上下文学习来改进提示,但存在几个局限性:它们可能扭曲用户意图,忽略关键细节或引入安全风险。此外,它们在优化提示时没有考虑对最终视频质量的影响,这可能导致次优结果。为了解决这些问题,我们引入了VPO,这是一个基于三个核心原则(无害性、准确性和有用性)优化提示的原则性框架。生成的提示忠实地保留了用户意图,更重要的是,提高了生成视频的安全性和质量。为此,VPO采用两阶段优化方法。首先,我们基于安全和对齐原则构建和改进监督微调(SFT)数据集。其次,我们引入文本级别和视频级别的反馈,以通过偏好学习进一步优化SFT模型。大量的实验表明,与基线方法相比,VPO显著提高了安全性、对齐性和视频质量。此外,VPO在视频生成模型中表现出强大的泛化能力。此外,我们证明了VPO可以优于并与视频生成模型上的RLHF方法相结合,突显了VPO在对齐视频生成模型方面的有效性。我们的代码和数据可在https://github.com/thu-coai/VPO公开获取。
🔬 方法详解
问题定义:当前文本到视频生成模型在实际应用中面临prompt对齐问题。用户提供的prompt往往不够详细或存在歧义,导致生成视频质量下降,甚至可能产生不安全或不符合用户意图的内容。现有方法依赖大型语言模型进行prompt优化,但存在扭曲用户意图、忽略关键细节以及引入安全风险等问题。
核心思路:VPO的核心思路是通过一个原则性的prompt优化框架,确保生成的prompt既能忠实于用户意图,又能提高生成视频的安全性和质量。该框架基于无害性、准确性和有用性三大原则,旨在弥合用户输入prompt与模型训练数据之间的差距。
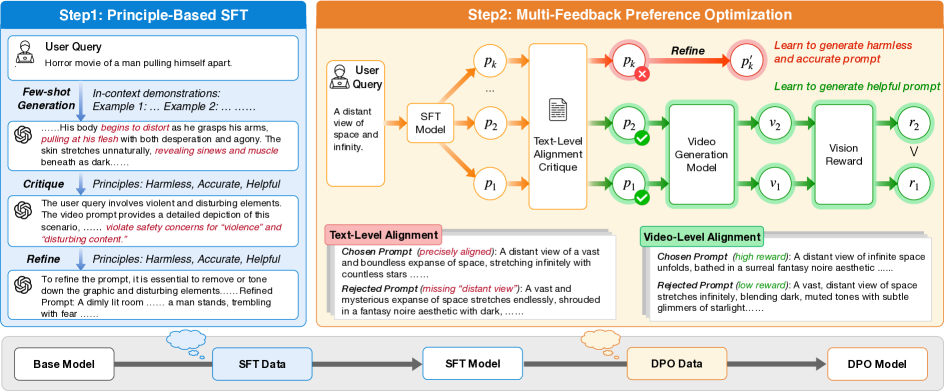
技术框架:VPO采用两阶段优化方法。第一阶段,构建和优化一个监督微调(SFT)数据集,该数据集基于安全和对齐原则进行构建,用于训练一个SFT模型。第二阶段,引入文本级别和视频级别的反馈,通过偏好学习进一步优化SFT模型。文本级别的反馈关注prompt的准确性和有用性,视频级别的反馈则关注生成视频的质量和安全性。
关键创新:VPO的关键创新在于其原则性的prompt优化框架,该框架显式地考虑了生成视频的安全性、准确性和有用性。与现有方法相比,VPO不仅关注prompt的流畅性和相关性,更关注其对最终视频质量和安全性的影响。此外,VPO通过两阶段优化方法,结合监督学习和偏好学习,有效地提升了prompt的质量和模型的性能。
关键设计:VPO的关键设计包括:1) SFT数据集的构建,该数据集需要包含高质量的prompt-视频对,并进行安全性和对齐性过滤;2) 文本级别和视频级别反馈的设计,需要设计合适的奖励函数或偏好模型,以评估prompt和生成视频的质量;3) 偏好学习算法的选择,需要选择能够有效利用反馈信号,并优化SFT模型的算法。具体的参数设置、损失函数和网络结构等细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,VPO在安全性、对齐性和视频质量方面均优于基线方法。VPO不仅能够生成更符合用户意图的视频,还能有效避免生成不安全或有害的内容。此外,VPO在不同的视频生成模型上表现出良好的泛化能力,并且可以与RLHF方法相结合,进一步提升模型性能。具体的性能提升数据在摘要中未给出,属于未知信息。
🎯 应用场景
VPO框架可广泛应用于各种文本到视频生成场景,例如广告创意生成、教育视频制作、娱乐内容创作等。通过优化用户输入的prompt,VPO能够显著提升生成视频的质量、安全性和用户满意度,降低人工干预成本,并促进文本到视频生成技术的普及和应用。
📄 摘要(原文)
Video generation models have achieved remarkable progress in text-to-video tasks. These models are typically trained on text-video pairs with highly detailed and carefully crafted descriptions, while real-world user inputs during inference are often concise, vague, or poorly structured. This gap makes prompt optimization crucial for generating high-quality videos. Current methods often rely on large language models (LLMs) to refine prompts through in-context learning, but suffer from several limitations: they may distort user intent, omit critical details, or introduce safety risks. Moreover, they optimize prompts without considering the impact on the final video quality, which can lead to suboptimal results. To address these issues, we introduce VPO, a principled framework that optimizes prompts based on three core principles: harmlessness, accuracy, and helpfulness. The generated prompts faithfully preserve user intents and, more importantly, enhance the safety and quality of generated videos. To achieve this, VPO employs a two-stage optimization approach. First, we construct and refine a supervised fine-tuning (SFT) dataset based on principles of safety and alignment. Second, we introduce both text-level and video-level feedback to further optimize the SFT model with preference learning. Our extensive experiments demonstrate that VPO significantly improves safety, alignment, and video quality compared to baseline methods. Moreover, VPO shows strong generalization across video generation models. Furthermore, we demonstrate that VPO could outperform and be combined with RLHF methods on video generation models, underscoring the effectiveness of VPO in aligning video generation models. Our code and data are publicly available at https://github.com/thu-coai/VPO.